ElasticSearch
ElasticSearch
ELK
: ELK - 데이터 수집 및 분석 툴로서 동작. 로그분석으로도 많이 쓰임.
- ElasticSearch : Lucene 기반으로 개발한 분산 검색엔진으로, LogStash 를 통해 수신된 데이터를 저장소에 저장하는 역할을 담당
- Logstash : 수집할 로그를 선정해서, 지정된 대상 서버(Elasticsearch)에 인덱싱해서 전송하는 역할을 담당하는 소프트웨어.여러 소스의 데이터를 동시에 가져 와서 변환 한 다음 Elasticsearch와 같은 stash로 보내는 서버 측 데이터 처리 파이프 라인
- Kibana : Visualization 을 담당하는 HTML + Javascript 엔진. Elasticsearch에서 차트와 그래프로 데이터를 시각화
ELK 장점
- 자유스키마 : JSON방식의 key-value 형식으로 데이터사용 형식에 자유롭고, 인덱스와일드카드를 지원해서 인덱스의 조인 가능.
- 확장가능 : 여러 대의 서버를 엮어 성능향상을 기대할 수 있는 클러스터방식. - 분산적이다. es에 저장되는 문서는 shard라고 하는 컨테이너들에 분산되며, 중복저장하여 장애 시 복구에 용이하다.
- 데이터처리 개별설정 : programming을 이용한 코딩으로 수행 시 유지보수가 불편하고 종속성이 높아지지만 logstash가 유연성을 확보하고 단점극복이 가능하다.
- 실시간 데이터처리 : 메세지큐와 결합하면 실시간 데이터수집 및 처리하기 용이. lucene기반 구축으로 full-text검색에 용이, 문서가 indexing되고 검색 가능해질 때 까지 시간이 1초 이내로 아주 짧다.
ElasticSearch 특징
-
opensource(루씬-java기반)
-
real-time(실시간분석)
: 현대 빅데이터 분석 플랫폼과 비교해서 실시간성이 있다.
현재 hadoop플랫폼 위 다양한 맵 리듀서들이 빅데이터분석에 가장 널리 사용되고있는데,Hadoop은 기본적으로 배치 기반의 분석 시스템으로 분석에 사용될 소스 데이터,분석을 수행할 프로그램을 올려놓고 결과 셋이 나오도록 하는 루틴으로 실행. elasticsearch는 하둡 시스템과 달리 클러스터(elasticsearch)가 실행되고 있는 동안에 데이터가 입력(indexing)되고, 실시간에 가까운 속도로 인덱싱된 데이터 검색,집계가가능. -
full-text 검색 엔진
루씬기반 : inverted file index(역파일 색인)구조로 데이터 저장.- indexing된 데이터들 inverted file index구조로 저장.
- 사용자 관점에서는 JSON형식으로 데이터 전달 : 개발자들이 다루기 편한 구조로 개발 연동하기 용이.
- key-val형식이 아닌 문서 기반이므로 복합적인 정보를 포함하는 형식의 문서를 있는 그대로 저장할 수 있음.(query에 사용되는 쿼리문,결과 json형식으로 전달,리턴됨. es가 지원하는 유일한 형식 : csv,syslog등 형식들은 logstash에서 변환 지원. )
-
RESTFUL api 제공
- REST API 기본으로 지원, http프로토콜 통해 restapi CRUD처리
-
MultiTenancy
- Elasticsearch 데이터들은 index(논리적 데이터 집합 단위)로 구성. 서로 다른 저장소에 분산되어 저장됨.
multitenancy는 서로 다른 인덱스들 별도 커넥션 없이 하나의 query로 묶어 검색 / 검색결과 하나의 출력으로 가능한 특징을 말한다.
- Elasticsearch 데이터들은 index(논리적 데이터 집합 단위)로 구성. 서로 다른 저장소에 분산되어 저장됨.
ElasticSearch - Indexing
- Indexing(색인) : '데이터가 검색될 수있는 구조로 변경하기 위해' 원본 문서를 검색어
토큰들로 변환하여 저장하는 것. - Index, indices(인덱스) : 색인과정을 거친 결과물(색인된데이터)가 저장되는 저장소.
- 검색(search) : 인덱스에 들어있는 검색어 토큰들 포함한 문서를 찾는것.
- 질의(query) : 검색어 또는 검색조건.
ElasticSearch - options
es 개별 설정 적용 대상은 노드마다이다.(노드 역할 나누거나 클러스터 속성 결정)
- jvm options : 힙메모리 및 환경변수
Java의 가상머신 위에서 실행이 되어 1gb의 힙메모리가 기본으로 설정되어있고, 이 설정들은 jvm.options 파일에서 변경가능. - elasticsearch.yml : 실질적 설정
(1) [cluster.name](http://cluster.name) : "<클러스터명>" (2) node.name: "<노드명>" (3) node.attr.<key>:"<value>" (4) path.data: ["<경로>" ] (5) path.logs: "<경로>" (6) bootstrap.memory_lock:true (7) network.host: <ip주소> (8) http.port: <포트번호> (9) transport.port: <포트번호> (10) discovery.seed_hosts: ["<host1>", "<host2>",... ] (11) cluster.initial_master_nodes: ["<node1>","<node2>"] - nodes
Node의 역할 : master, data, ingest (default : 기본적으로 노드 명시된 모든 역할 수행)- (1)node.master:true : 마스터 후보 노드 여부 설정, 모든 클러스터는 1개의 마스터 노드 존재
- (2)node.data.true : 노드가 데이터 저장
- (3)node.ingest.true : 데이터 색인시의 전처리작업 ingest(수집) pipeline작업
모든 설정을 false로 두게되면 해당 노드는 데이터를 저장하거나 색인하지 않고 클러스터 상태를 업데이트하지도않음. 클라이언트와 통신하는 역할로만 사용. (coordinate only node) : es culster에서 로드밸런서 비슷한 역할을 수행하고 cluster 크기가 커질수록 필요하다.
- (4) coordinate node
- routing이 안되어있는 경우 Coordinate node의 역할
- 특정 데이터를 찾아야 하는 요청(request)을 받는다
- cluster의 모든 노드에게 해당 데이터를 가지고 있는지 질의
- 모든 노드로부터 데이터 유무와 데이터 정보를 받고 데이터를 모아서(aggregate) 요청(request)에 응답(response)
- routing이 되어있는 경우 Coordinate Node의 역할
- 특정 데이터를 찾아야 하는 요청(request)을 받는다
- routing을 통해 어떤 node가 해당 데이터를 가지고 있는지 알 수 있음.
- 해당 노드에게만 데이터를 질의, 받아서 응답
- routing이 안되어있는 경우 Coordinate node의 역할
ElasticSearch 노드
노드
노드는 논리적 cluster를 이루는 구성원 일부이고 실제로 데이터를 가지고있는 물리적 단일 서버.
node식별은 실행 시 cluster에의해 uuid가 할당, cluster내에서 uuid로 식별.
마스터노드
:인덱스 생성, 삭제, 데이터를 어떤 샤드에 할당할지에 결정하는 역할을 수행
인덱스의 메타 데이터, 샤드의 위치와 같은 클러스터 상태(Cluster Status) 정보를 관리하는 노드
후보를 선정할 수 있고 후보들은 마스터노드 정보 공유하기에 마스터후보노드 에러 시 바로 대신 역할 가능.(default 모든 노드가 후보)
실제 운영 환경에서는 마스터 후보를 노드는 최소 3개 이상의 홀수개로 설정 : Split Brain(만약 2대의 마스터 노트 후보 노드가 존재하고 , 네트워크 단절로 연결이 끊어진다면 두대만 연결되있었으므로 각자 클러스터에서 서로 다른 클러스터로 동작하고있을 수 있다. 복구 시 데이터 정합성이 문제가 생길 수 있음.)
데이터노드
실제로 색인된 데이터를 저장하고 있는 노드
데이터가 실제로 분산 저장되는 물리공간인 샤드가 배치되어 있다.
Coordination 노드
사용자의 요청을 받아서 클러스터 관련 요청은 마스터 노드에 전달하고, 데이터 관련 요청은 데이터 노드에 전달하는 역할을 담당.
별도로 지정하지 않았다면 모든 노드가 코디네이션 노드 역할을 수행하게 됨.
대량의 노드로 구성된 클러스터라면 코디네이션 노드를 지정하여 역할을 분리하는 것이 더 안정적.
ElasticSearch 클러스터 구성
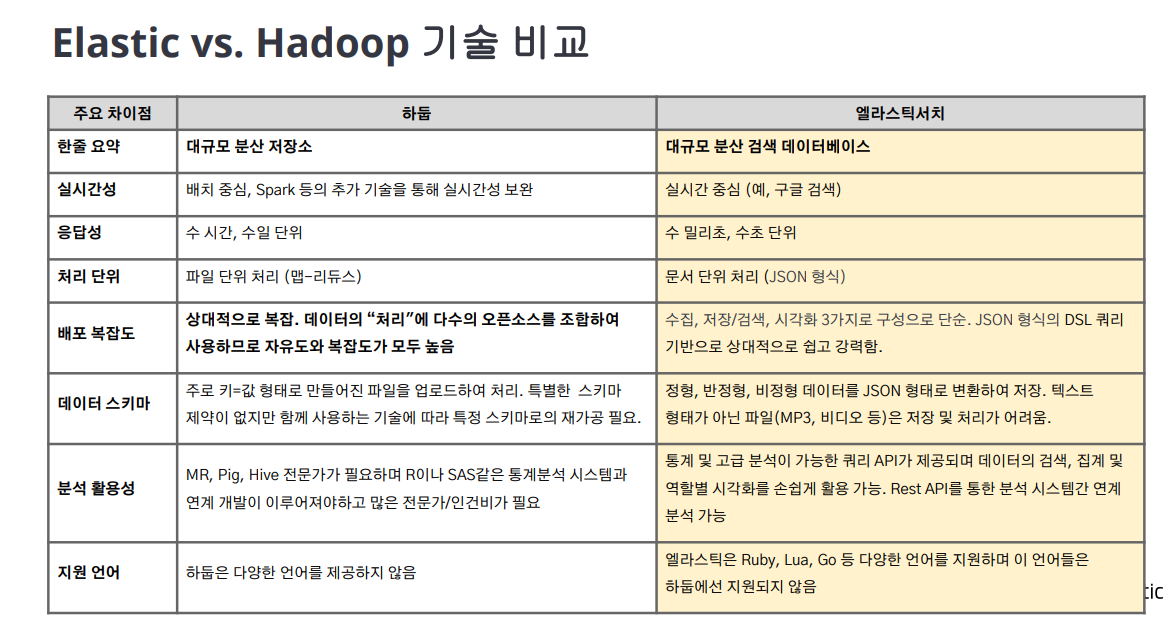
Elasticsearch의 노드들은 클라이언트와의 통신을 위한 http 포트(9200~9299), 노드 간의 데이터 교환을 위한 tcp 포트 (9300~9399) 총 2개의 네트워크 통신이 존재하고 일반적으로 서버1대당 마스터노드 1대 존재. 하나의 클러스터로 묶여있다면 데이터 교환이 일어난다.
디스커버리 : seed_host에서 설정된 네트워크 상 다른 노드들을 찾아 하나의 클러스터로 바인딩하는 과정.
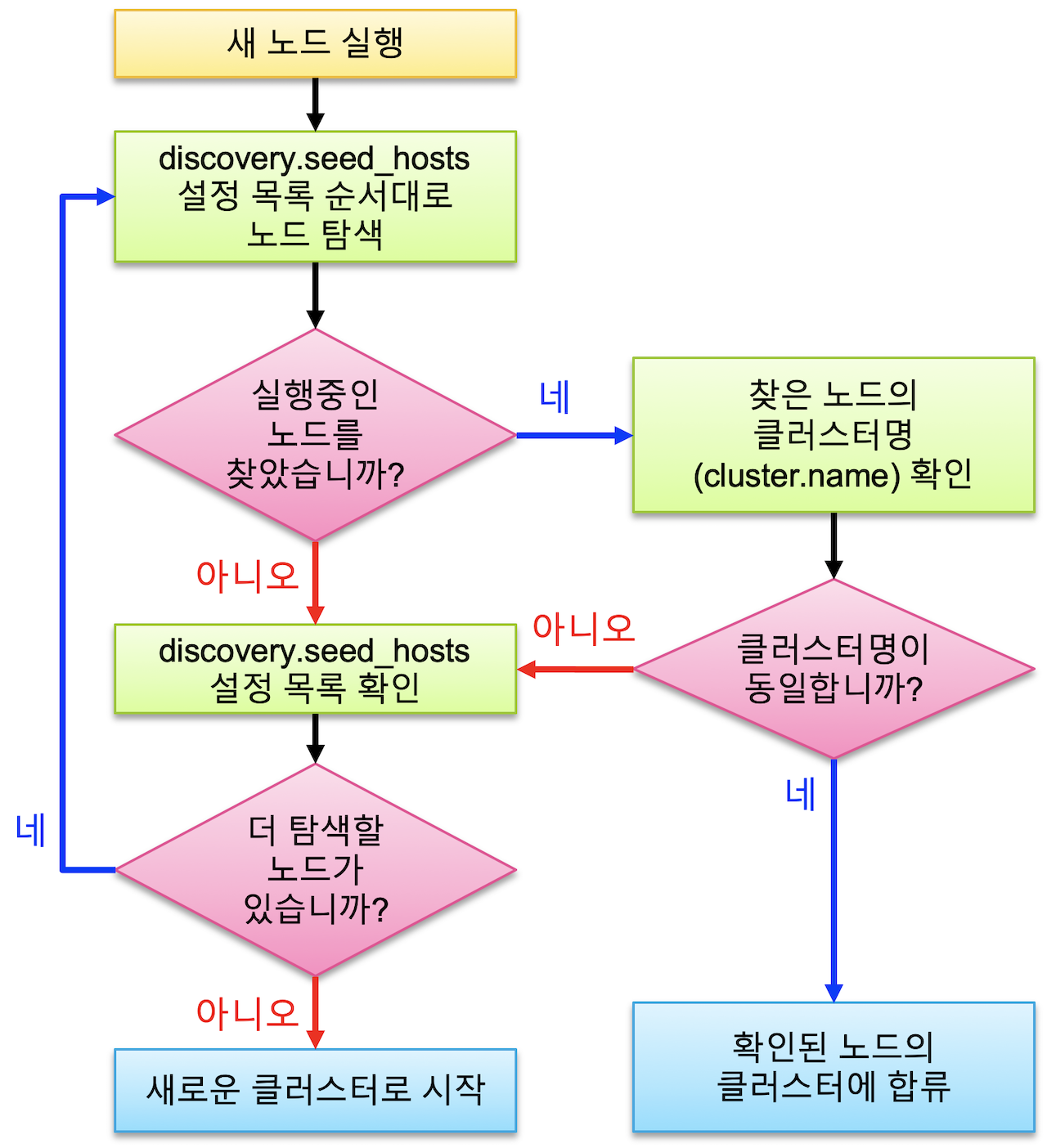
같은 Cluster 내부의 데이터만 서로 공유가능하기에 연관된 모든 노드가 하나의 Cluster 구성원으로 연결되는 것이 매우 중요하며, es설정 시 구성 노드들을 같은 클러스터 이름으로 설정하면 연결된다.
각 노드는 data indexing,검색작업, 데이터복구 작업 등이 가능한 일종의 물리적 서버이며, 내부에 Lucene 라이브러리가 있어 핵심 모듈을 구성
인덱스와 샤드
ES 단일 데이터 단위 : document(json형식으로 표현)
document를 모아놓은 집합 : Index(Indices)
데이터를 es에 저장하는 행위 : Indexing
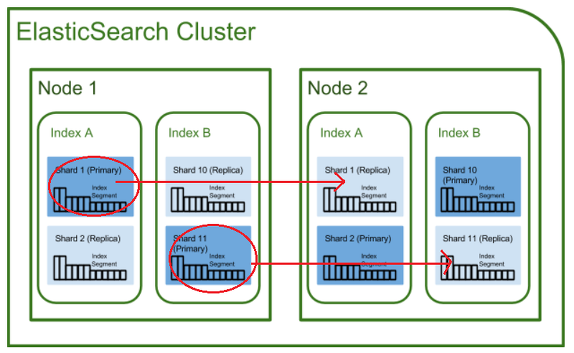
인덱스 저장 시 분산저장하는 단위 : Shard
장애 복구를 위해 존재하는 Shard의 복제본 : Replica
루씬(shard) 내부에 존재하는 역색인 구조의 자료구조. : Shard
Shard
인덱스는 기본적으로 shard라는 단위로 분리되고, 각 노드에 분산되어 저장됨. shard는 Lucene의 단일 검색 인스턴스이다. (indexing된 데이터들이 물리적인 여러 공간에 저장되는데, 그 공간이 검색라이브러리인 lucene의 인스턴스이다.)
index의 전체 데이터를 분산해서 가지고있으며, shard만으로도 독립적으로 검색 서비스가 가능하다. : shard는 내부에 각 독립적인 루씬 라이브러리를 가지고있다. 또한 샤드 내부에서는 세그먼트로 쪼개 저장하고 제공 시 세그먼트를 합쳐서 보내준다.Primary Shard, Replica
첫 생성 샤드를 primary shard, 복제본을 Replica라고 부른다. 같은 샤드와 replica는 동일 데이터를 담고있어 데이터 무결성, 가용성에 기여하고, 클러스터에서 유실된 노드 복구 시 샤드의 복제를 수행한다.Index
문서들의 컬렉션(document)이고 document들이 인덱스에 저장되면, 실제로는 물리적인 shard의 형태로 나누어져 다수의 노드로 분산저장된다.Index에 쿼리 요청 시
(1) Index가 가지고 있는 모든 Shard로 검색 요청 전달
(2) 각 Shard에서 1차적으로 검색 한 후
(3) 그 결과를 취합하여 최종 결과로 제공
Lucene과 내부구조(참고)
(1) Elastic Search shard vs Lucene index
- ES shard : 실제 데이터를 가지고 있는 최소 단위의 검색 모듈(하나의 ES shard는 하나의 Lucene index,모든 shard가 가지고 있는 segment들을 논리적으로 통합하여 검색 가능) => 루씬의 물리적 한계 극복
- Lucene index : IndexWriter와 IndexSearcher를 가지고 색인과 검색을 동시에 제공하는 루씬 인스턴스
자기 자신이 가지고 있는 segment 내에서만 검색 가능
데이터 저장 시 물리 머신이 제공하는 리소스의 한계를 뛰어넘을 수 없다는 단점 존재
그렇다면, ES index는?
물리적으로 분산된 ES shard를 논리적인 관점에서 하나의 거대한 데이터로 바라본 것(2) Elastic Search가 근실시간(Near Real-Time) 검색을 제공하는 이유
- 검색 과정
- 사용자가 ES index를 검색하면 index에 포함된 모든 shard(lucene index)로 동시에 요청 전송
- 각 shard에서는 commit point를 이용해 내부에 존재하는 모든 segment들을 순서대로 검색 후 결과 전달
- ES는 모든 shard로부터 도착한 검색 결과를 하나의 커다란 결과 셋으로 만들어 최종적으로 사용자에게 전달
- 어떻게 색인 결과가 물리적인 디스크에 생성되는데도 불구하고 실시간에 가까운 검색이 가능한지? : 역색인구조이며 index를 shard로 분산저장, segment를 불변하도록 만들어 캐시 활용, 락x 등 자원소요시간을 줄이고 commit point을 활용해 위치를 파악, segment 주기적으로 merge하는 등 최적화를 통해 응답을 빠르게함
#1 segment, 역색인 구조이기 때문에.
루씬은 검색 요청을 받으면 다수의 작은 segment 조각들이 각각 검색 결과 조각을 만들어내고 통합하여 결과를 응답하도록 설계된 검색방식(Per-Segment Search) -> 역색인 구조이기에 빠른 읽기 검색
- segment 불변성 (수정 절대 비허용)
- 동시성 문제 회피 : 다중 스레드 환경에서 불변성이 보장되기에 Lock 필요없어짐
- 시스템 캐시 활용 : 데이터가 시스템 캐시에 한번 생성되면 일정 시간 동안은 그대로 유지 (데이터 변경될 때마다 시스템 캐시를 삭제하고 다시 생성해야 하는 비용 제거)
- 높은 캐시 히트율 유지 : 검색 시 데이터를 항상 메모리에서 읽어올 수 있음.
- 단점으로 수정 불가하여 일부 데이터가 변경되더라도 새로 역색인을 만들어야 하고, 변경사항을 반영하려면 반드시 새로운 역색인을 만들어야하는데 변경이 매우 빠르게 일어날 경우 실시간 반영 자체가 불가능하다. 하지만 다수의 segment를 생성해서 제공해 변경이 일어날 때마다 segment를 다시 만드는게 아니라, 기존 segment는 그대로 두고 추가로 segment를 생성, 그리고 검색 요청 시에는 생성된 모든 segment를 읽어서 검색결과를 제공하는 방식으로 극복
#2 Commit Point 자료구조이기 때문에.
- 여러 segment의 목록 정보를 가지고 있어 색인, 검색 시 Commit Point 활용한다.
- IndexSearcher가 Commit Point를 이용해 모든 segment를 읽어 검색결과를 제공
- 루씬의 IndexSearcher는 검색 시 Commit Point를 이용해 가장 오래된 segment부터 차례대로 검색한 후 각 결과를 하나로 합쳐서 제공
- 최초 Indexing 작업 요청이 들어오면 IndexWriter에 의해 색인 작업 이루어지고 결과물로 하나의 segment가 생성.
- 색인 작업을 할 때마다 새로운 segment가 추가로 생성되고 Commit Point에 기록된다. -> 기존 segment에 정보를 추가하거나 변경하지 않고 매번 새로운 segment를 만들기에 segment의 개수는 점점 늘어난다. (다수의 파일을 열어 읽어야 하는 성능 저하 방지)
- segment 개수가 시간이 흐를수록 빠르게 늘어나기에 주기적으로 background에서 segment 파일을 Merge -> 읽기 성능 저하 방지
- Lucene을 위한 Flush, Commit, Merge
- Lucene Flush
segment가 생성된 후 검색이 가능해지도록 수행하는 작업
write() 함수로 동기화가 수행되었기에 커널 시스템 캐시에만 데이터가 생성
일단 시스템 캐시에만 기록되고 리턴. 이후 실제 데이터는 특정한 주기에 따라 물리 디스크에 기록. 시스템 비정상 종료 시 데이터 유실 가능성
이를 통해 유저 모드에서 파일을 열어서 사용하는 것이 가능
물리적으로 디스크에 쓰여진 상태는 아니다 (<-> fsync() 함수)- Lucene Commit
커널 시스템 캐시의 내용을 물리적인 디스크로 쓰는 작업
실제 물리적인 디스크에 데이터가 기록되기에 많은 리소스 필요- Lucene Merge
다수의 segment를 하나로 통합하는 작업
Merge 과정을 통해 삭제 처리된 데이터가 실제로 물리적으로 삭제 처리 된다
검색할 segment의 개수가 줄어들어 검색 성능 향상, 디스크 용량 경량화
역색인 구조)
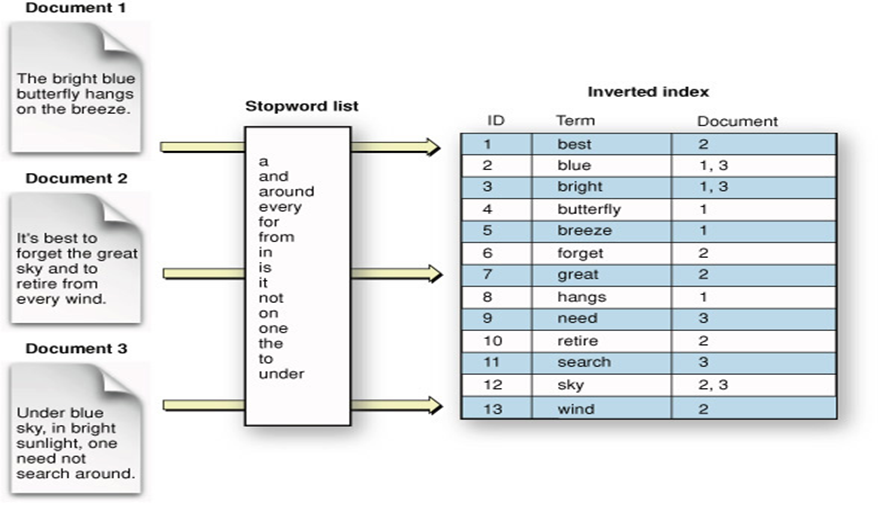
빅데이터 프레임워크들
참고자료
(1) 관계형 데이터베이스를 벗어나는 이유 : 비용
RDB는 수직적 확장을 할 수 밖에 없는 구조이기에 효율적이지 않다.
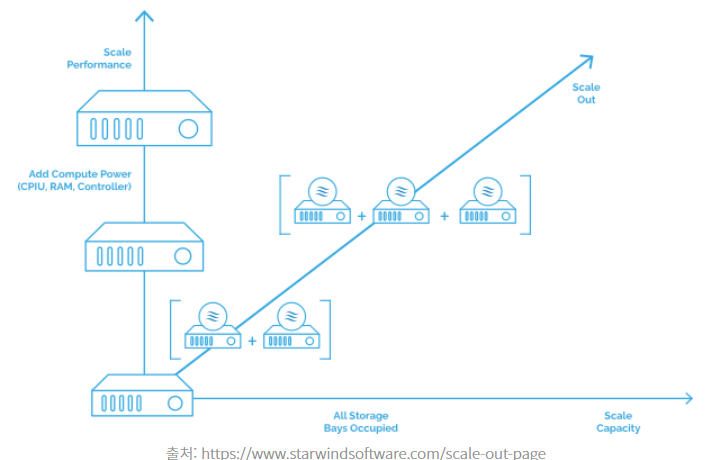
수평적으로 확장이 가능하도록 하는 것은 비용적으로 많이 유리하다.
수평적 확장 수직적 확장
: 수평 확장 은 리소스 풀에 더 많은 시스템 을 추가하여 확장하는 반면 수직 확장은 기존 시스템에 더 많은 전력 (CPU, RAM)을 추가하여 확장 할 수 있음을 의미한다.
(2) Hadoop : 클러스터(수평적확장이 가능 , 분산저장 및 분산처리)
Hadoop은 빅데이터 분석을 위해 표준으로 사용되는 프레임워크. 핵심은 NameNode를 제외하고 수평적 확장이 가능하다. HDFS에서는 스토리지가 부족할 경우 Data Node를 추가함으로써 수평적으로 scale out이 가능하고, Yarn에서는 map reduce를 빠르게 수행하기위해 cpu,ram등 컴퓨팅 자원이 필요할 경우 Node manager를 추가함으로써 컴퓨팅 자원을 늘릴 수 있다.
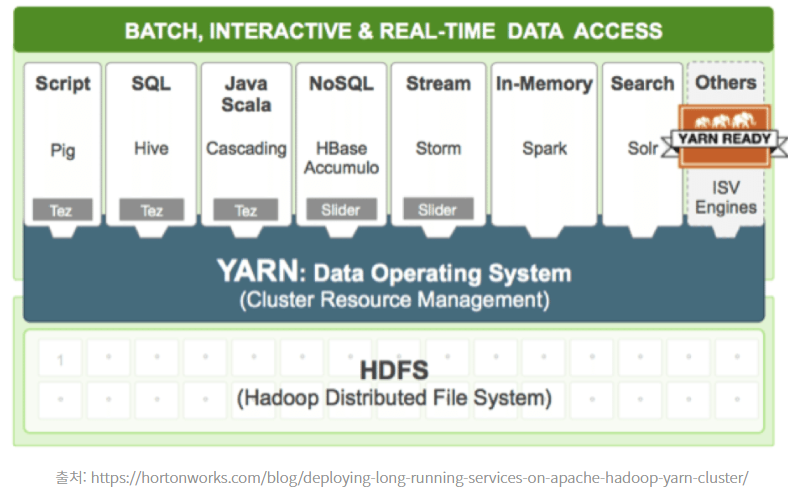
Hadoop을 이용하면 비교적 낮은 비용으로 수평적 확장을 할 수 있는 클러스터가 되는 것. (분산저징과 분산처리)
현재 하둡은 분산 저장, 분산 처리를 메인 프로젝트로 시작해서 여러 서브프로젝트들이 포함된 생태계를 의미하게되었다.
Hive
Hive는 빅데이터를 SQL(HiveQL)로 다룰 수 있게 도와주는 시스템이고 hadoop과 연동되는 파일시스템(HDFS)에 저장된 데이터를 hive에 테이블로 선언을 해두면 다양한 포맷 데이터를 SQL로 다룰 수 있게 된다. (jdbc, odbc application-> hive server-> hive driver-> metastore->..) Hive에 query가 들어오면 query를 분석해 여러단계의 mapreduce task로 분리, task관계도를 그래프로 구성해 hadoop yarn 위에서 데이터처리를 할 수 있게된다. 이 때 spark vs hadoop vs hive: spark sql는 관계형 데이터베이스에 결과를 직접 write할 수 있지만 hive에서는 sql을 이용해 데이터 처리를 할 수 있지만 그 이상의 저장 등은 어렵다. hive 에서 엔진으로 mapreduce, tez, spark를 사용할 수 있다.
ZooKeeper
자원 코디네이터. 분산 시스템에서는 동기화가 매우 중요한 문제이고, hadoop ecosystem에서는 mutex,semaphore의 역할을 zookeeper가 수행한다. zookeeper는 여러 노드에 데이터를 중복으로 저장하여 높은 신뢰성을 구현한다. (최소 3대, 한 node 변경사항은 다른노드로 전파)
hadoop HDFS namenode의 high-availabilty를 위해 zookeeper가 이용, namenode의 상태를 zookeeper에 동기화시키며 active namenode에 문제가 생겼을 때 standby Namenode가 active namenode로 승격할 수 있게 함.(kafka등 다양한 솔루션들에서도 사용됨)
(3) Spark : 분산 처리(컴퓨팅) 프레임워크
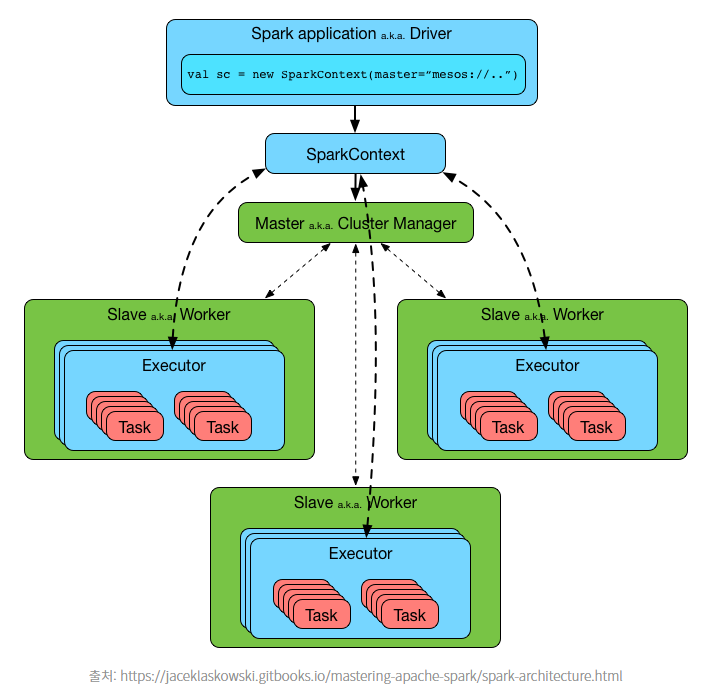
spark는 컴퓨팅에 대해 수평적 확장을 할 수 있는 분산 컴퓨팅 프레임워크이며, Hadoop의 분산처리모듈 MapReduce를 대체하여 많이 사용된다.
spark를 이용하면 hadoop HDFS혹은 연동된 파일시스템에 저장된 다양한 포캣의 데이터에 대해 분산컴퓨팅을 수행할 수 있다. mapReduce는 mapper의 작업이 모두 끝나야(key-value) 중간파일을 대상으로 Reduce(분산처리)를 진행하므로 속도가 떨어진다. 그러나 spark는 Streaming방식으로 map함수가 종료되지 않았더라도 결과를 스트리밍방식으로 처리가 가능해서 빠르고 in-memory데이터 엔진을 써서 로컬파일이 아닌 메모리접근을 하기때문에 어쨌든 훨씬 성능이 좋다.빠르다.
단일 머신(standalone) 외에도 Haddop Yarn, kubernetes와 같은 클러스터 시스템과 결합되어 자원을 동적으로 할당할 수 있다.
master node를 먼저 실행시키고, job을 실행하기 위해 추가적으로 필요한 node들을 ClusterManager를 통해 추가로 띄우는 식이다.
그래서 요즘의 분산 컴퓨팅의 거의 표준.
(4) Kafka : 높은 신뢰성,성능을 제공하는 스트림
publish-subcribe 구조를 고성능으로 제공하는 솔루션. 대용량 스트림처리에 있어 사실상 표준이다. queue보다 kafka같은 스트림이 좋은 이유는 queue로는 확장성이 부족할 때가 있기 때문.
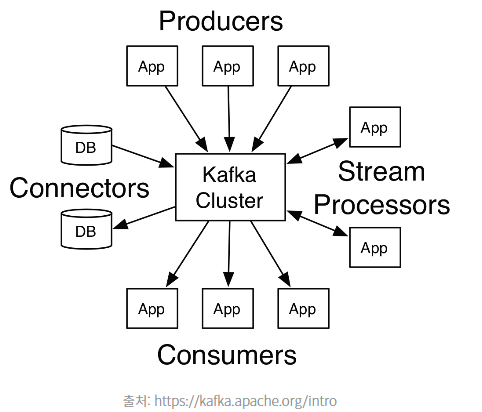
kafka의 강점은 장애에 강하다는 점도 있다. 단일 node로 구성하지 않고 broker라는 노드들을 이용해 구성, 2대 이상의 broker에 메세지를 중복저장하여 유실을 방지한다.
kafka는 cluster에 중앙집중화되어있고, producer와 consumer의 결합이 약하다. 또한 메세지 소비 시 바로 삭제되는 것이 아니고 저장,보존되므로 안전성이 높다. 실시간 스트리밍 처리를 위해 이용되기도 하며 kafka에 적재하고 spark streaming과 같은 스트리밍 처리 프레임워크를 이용해 스트리밍 처리를 하는 것이 일반적.
(5) ElasticSearch : 검색,집계 등 거의 모든 것을 할 수 있는 유용한 솔루션.
ElasticSearch를 이용해 indexing, storage하고, Logstash로 ElasticSearch에 데이터를 전송, Kibana로 시각화 및 관리를 하는 ELK스택을 많이 사용. 로그 분석에 강점. ElasticNode를 추가하여 수평적 확장이 가능하다. Elasticsearch 클러스터를 유지하기 위해서는 많은 비용이 든다(스토리지, 인덱스 유지) : 좋은 성능들의 node가 필요. elasticsearch 클러스터에 문제가 생겼을 때 데이터 유실이 발생할 수 있다. logstash를 쓰면 쉽게 거의 유실 없는 데이터 전송이 가능하고, kibana는 강력한 시각화도구이다. 비교적 적은 양의 데이터를 빠르게 다루기 위해서는 elasticsearch가 훌륭한 솔루션이라 할 수 있다.
참고)