참고 링크 ) https://mangkyu.tistory.com/128
참고 링크 ) https://bcho.tistory.com/1387
참고 링크 ) https://wikidocs.net/26630
1.Spark
Spark
스파크는 인메모리 기반의 대용량 데이터 고속 처리 엔진으로, 분산 클러스터 컴퓨팅 프레임워크이다.
- 인메모리
In-Memory란 메인메모리인 RAM에 데이터를 올려서 사용하는 방법. : 속도
저장공간에서 데이터를 가지고오는 것 보다 RAM에 올려진 데이터를 가져오는데 걸리는 속도가 훨씬 빠르다. 그래서 Inmemory db로 h2를 쓰는것이고, 인메모리 데이터저장소(캐시)로 Redis를 쓰고 하는 것이다.
하둡에서는 분산, 병렬 처리를 위해 MapReduce라는 모듈을 제공했었고, 하둡의 핵심 코어 프로젝트였는데, 단점이 있었다
Map함수가 모두 종료되면 master node에게 작업완료를 알리고, 로컬 저장한 key-value기반의 itermediate files들을 read하는 것은 그 다음
: mapper함수가 모두 끝날 때 까지 reduce는 실행하지 못한다는 성능손실이 존재.
Spark는 (1)map함수가 종료되지 않았더라도 Map의 결과를 Streaming하는 방식으로 이러한 단점을 개선하였다.
또한 (2)In-memory 데이터 엔진을 통해 로컬 저장된 파일들을 불러와야 했던 성능상 한계가 있었던 초기 MapReduce보다 크게 개선되었다.(spark는 hadoop의 10배정도 우위에 있다고함)
이러한 장점에 요즘은 spark를 많이쓴다고한다.
하지만, hadoop을 대체한다는 의미는 아니며 hadoop의 HDFS같은 분산 파일시스템(저장)은 필요하다. spark자체가 하둡 기반으로 구동하는 것을 목적으로 만들어졌고 보통 하둡 기반으로 사용한다고한다.(하둡생태계에포함)
Spark 특징
- 인메모리 기반의 빠른 처리(Speed)
mapReduce를 대체하여 사용하는 경우가 많아 비교하자면 mr는 작업 중간결과를 disk에 쓰기 때문에 IO로인하여 작업 속도에 제약이있다. spark는 중간작업을 메모리에 저장하여 처리효율이 높다. - 다양한 클러스터매니저 지원, 파일포맷 지원(Run everywhere)
yarn,kubernetes,standalone등 다양한 포맷과 운영시스템 지원. HDFS,카산드라,HBase,S3등 다양한 데이터포맷도 지원. txt,json등 파일포맷지원. - 다양한 언어 지원(Easy-use)
java scala python r sql 지원 - 다양한 컴포넌트제공 (Generality)
spark stream(스트리밍처리), 스파크sql를 이용한 sql처리, mlib을 이용한 머신러닝처리, GraphX를 이용한 그래프 프로세싱을 제공. (추가설치 없이 다양한 기능이용가능, 컴포넌트 연계해 어플리케이션 생성 용이)컴포넌트 구성
- Spark Core : 메인 컴포넌트. 작업 스케줄링, 메모리관리, 장애복구와 같은 기본적 기능들을 제공하고 RDD,Dataset,Dataframe을 이용한 스파크 연산을 처리.
- Cluster Manager : 스파크 작업을 운영하는 관리자. standalone은 스파크 제공, yarn, kubernetes등도 지원.
- 스파크 라이브러리
- sparkSQL : SQL을 이용하여 RDD, DataSet, DataFrame 작업을 생성하고 처리
- sparkStreaming : 실시간 데이터 스트림을 처리하는 컴포넌트,스트림 데이터를 작은 사이즈로 쪼개어 RDD 처럼 처리
- MLib : 스파크 기반의 머신러닝 기능을 제공하는 컴포넌트. 분류(classification), 회귀(regression), 클러스터링(clustering) 등의 머신러닝 알고리즘과 모델 평가 및 외부 데이터 불러오기 같은 기능도 지원
- GraphX : 분산형 그래프 프로세싱이 가능하게 해주는 컴포넌트
Spark 구조
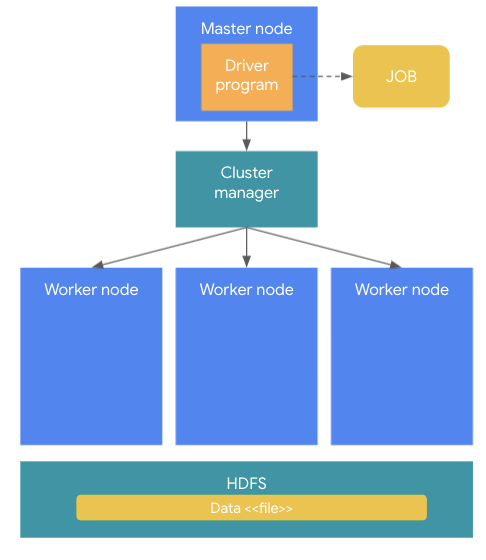
master-worker구조로 구성된다. (요즘 blm이슈로 master-slave라는 표현을 쓰지 않는 것이 좋다고함)
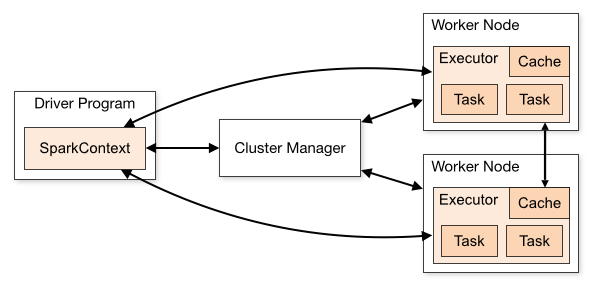
(masternode:driver program, cluster manager, worker node)
master node는 전체 클러스터를 관리, driver프로그램(분석프로그램)을 수행한다. driver 프로그램이 실행되면 하나의 job이 생성되는데, job이 외부 저장소(HDFS..)로부터 데이터를 로딩하는 경우, 데이터는 spark cluster worker node로 로딩이되고, 로딩된 데이터는 여러 서버 메모리에 분산로딩된다. 이 때 스파케 메모리에 저장된 객체를 RDD라고 함. 이렇게 로딩된 데이터는 어플리케이션 로직에 의해 처리되고 이 job들은 분산된 데이터를 이용해 분산되어 실행된다. 이 때 나눠진 task를 실행하는 것을 excutor라고 함.
스파크 어플리케이션
- driver: 스파크 어플리케이션을 실행하는 프로세스, SparkContext 객체를 생성함. 작업 처리결과를 사용자에게 알려준다.
- Excuter: 태스크 실행을 담당. 실제 작업을 진행한다. yarn의 컨테이너라고 볼 수 있고 태스크 작업 실행 후 결과를 드라이버에게 알려준다.
- Task : excutor에서 실행되는 실제 작업.
Spark Job 구성
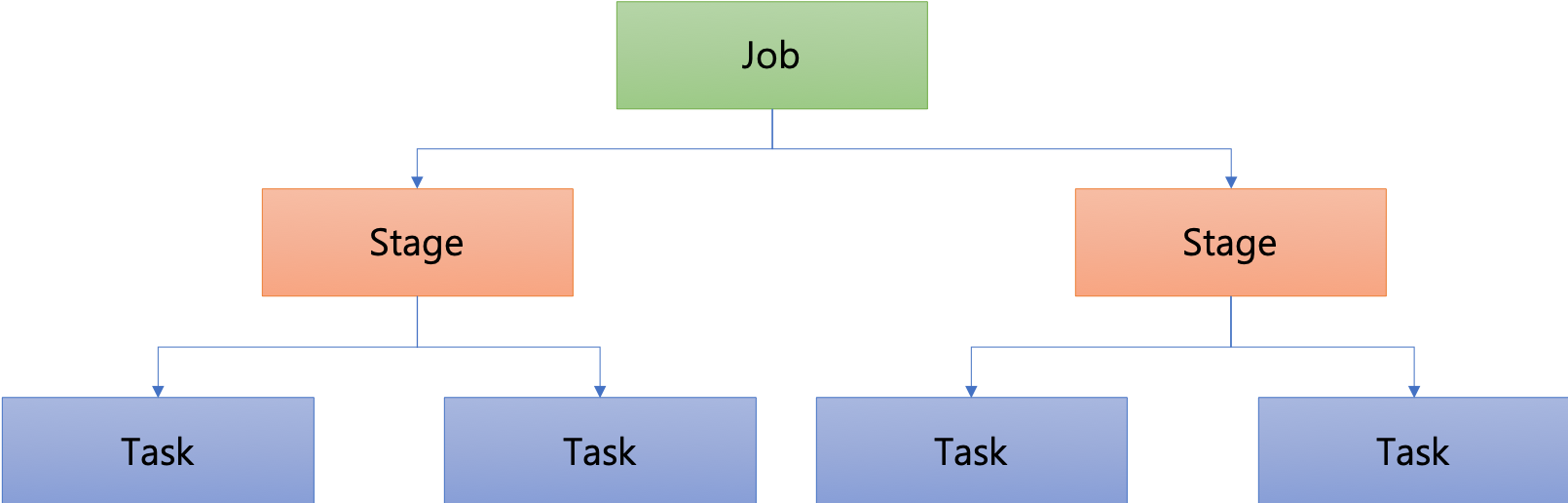
- 잡(Job)
스파크 애플리케이션으로 제출된 작업 - 스테이지(Stage)
잡을 작업의 단위에 따라 구분한 것 - 태스크(Task)
익스큐터에서 실행되는 실제 작업. 데이터를 읽거나, 필터링 하는 실제 작업을 처리.
클러스터 매니저
스파크는 여러대 worker들로 구성된다. (분산 task를 받기 위한)
job을 나눈 task들을 배치하는 역할을 하는 것. 클러스터 내 워커들 리소스를 관리하는 것이 클러스터 매니저다.
-
클러스터 매니저 cluster 모드 예시
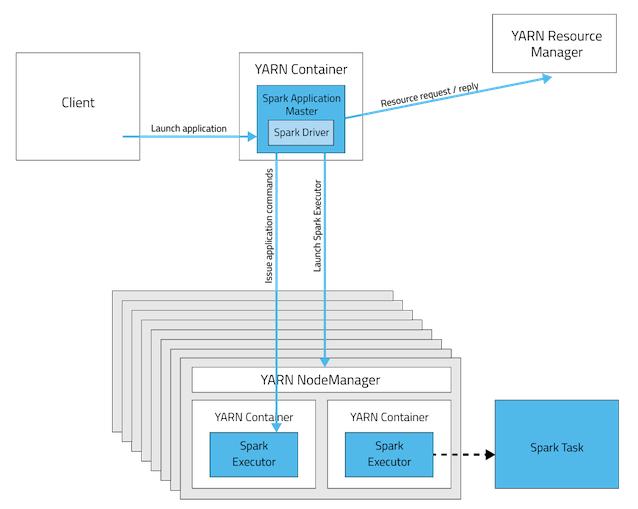
Cluster Mode는 모든 것들은 Cluster에서 구동, Spark Driver는 YARN Application Master 내부에 캡슐화 되어있다.Client가 꺼져도 Cluster에서 job은 처리.오랜 작업시간이 필요한 경우, Cluster Mode를 사용하는 것이 좋다. -
클러스터 매니저 client 모드 예시
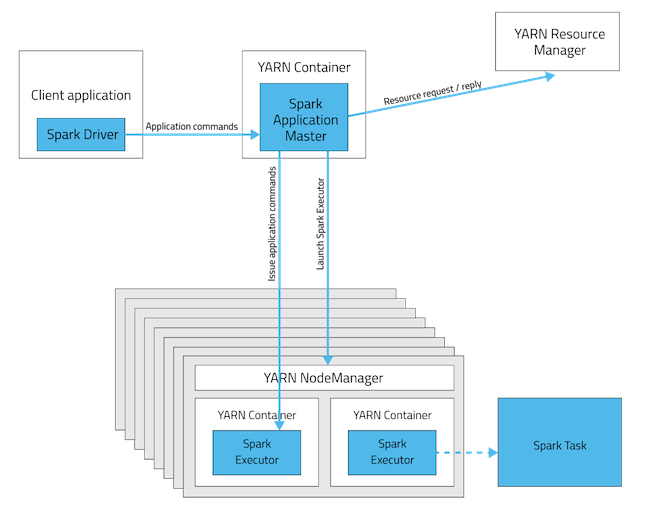
Client가 꺼지면, job은 fail.Client Mode는 interactive jobs(실시간 쿼리 or 온라인 데이터 분석 등)에 적합
