딥 러닝을 이용한 자연어처리 입문
1.딥 러닝을 이용한 자연어처리 입문0. 자연어처리
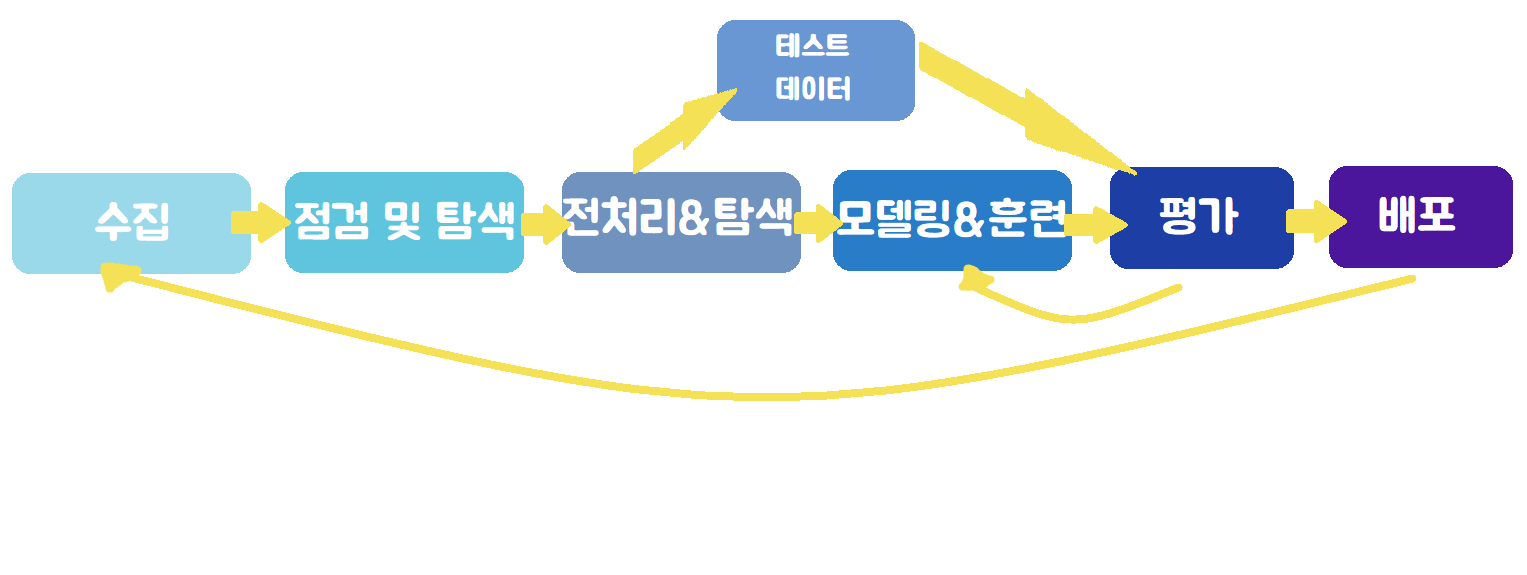
Natural Language Process (NLP).음성 인식, 내용 요약, 번역, 사용자의 감성 분석, 텍스트 분류 작업(스팸 메일 분류, 뉴스 기사 카테고리 분류), 질의 응답 시스템, 챗봇.. 등.말 그대로 언어를 처리하는 것을 의미한다.이전에는 symboli
2.딥 러닝을 이용한 자연어처리 입문1. 텍스트 전처리(1)

주어진 corpus를 Token단위로 나누는 과정.보통 의미 있는 단위로 토큰을 정의.의미 있는 단위를 단어로 설정하여 토큰화하는 것.단어 : literally 단어/ 단어구/ 의미가 있는 문자열간단한 예제 ) my name is 'name' -> my, name,
3.딥 러닝을 이용한 자연어처리 입문1. 텍스트 전처리(2)
텍스트 전처리 과정은 (1) tokenization : courpus에서 용도에 맞게 토큰 분류 (2) cleaning(정제) : 갖고 있는 코퍼스로부터 노이즈 데이터를 제거한다. (3) normalization(정규화) : 표현 방법이 다른 단어들을 통합시켜서 같은
4.딥 러닝을 이용한 자연어처리 입문1. 텍스트 전처리(3)
두 작업이 갖고 있는 의미는 눈으로 봤을 때는 서로 다른 단어들이지만, 하나의 단어로 일반화시킬 수 있다면 하나의 단어로 일반화시켜서 문서 내의 단어 수를 줄이겠다는 "정규화" 의미. 단어의 뿌리 단어를 찾아가 단어의 개수를 줄일 수 있도록 한다.형태학적 parsing
5.딥 러닝을 이용한 자연어처리 입문1. 텍스트 전처리(4)
cleaning. 데이터에서 의미가 없는 토큰 제거. (분석에 도움이 되지 않으며 복잡도만 높임)konlpy examplestopword사전 :https://www.ranks.nl/stopwords/korean 참고
6.딥 러닝을 이용한 자연어처리 입문1. 텍스트 전처리(5)
token화-> 정제(불용어..)/정규화(형태소분석)에대한 방법론까지 알아봤는데,이를 위해 텍스트 전처리에서 자주 사용되는 도구들을 알아볼것6\. 한국어 전처리 패키지
7.딥 러닝을 이용한 자연어처리 입문2. 언어모델(1)
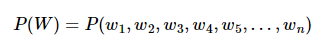
언어모델 : 단어 시퀀스(문장)에 확률을 할당하는 모델 (문장에대한 자연스러움,적절성 판단)Statistical Languagel Model, SLM : 통계에 기반한 언어모델,최근에는 딥러닝을 많이 사용하는 추세이다.주어진 단어들로부터 아직 모르는 단어를 예측하는 작
8.딥 러닝을 이용한 자연어처리 입문2. 언어모델(2)
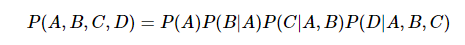
확률 chain rulechain rule에따라,이와 같이 문장 확률을 표현할 수 있다.결국, 문장의 확률은 다음 단어에 대한 예측 확률을 모두 곱한 것.그렇다면이때 P(단어)는 무엇을 의미할까=>SLM에서는 '카운트'기반으로 이전단어에대한 다음단어 확률을 계산함. 쉽
9.딥 러닝을 이용한 자연어처리 입문3. 카운트 기반 단어표현(1)
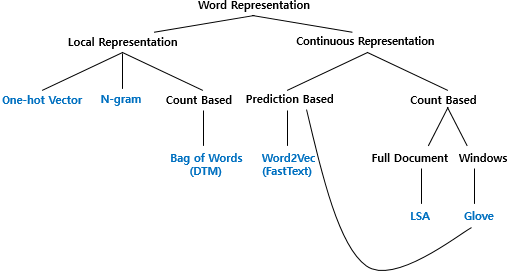
(1) 국소표현(local representation) : 단어 자체만 보고 표현 = 이산(discrete) (2) 분산표현(distributed representation) : 주변을 참고해 단어값 표현 = 연속(continuous) 같이 자주 등장하는 단어가 비슷하
10.딥 러닝을 이용한 자연어처리 입문4. Vector Similarity(1)

기계가 계산하는 문서의 유사도의 성능은 각 문서의 단어들을 어떤 방법으로 수치화하여 표현했는지(DTM, Word2Vec 등), 문서 간의 단어들의 차이를 어떤 방법(유클리드 거리, 코사인 유사도 등)으로 계산했는지에 달려있다. => 전자의경우 단어의 (수치화)표현방법