1. 단어 표현 방법
문자를 숫자로 나타내는 방법.
=> vectorization으로 수학적 특성을 표현해야 자연어만 보고는 파악하지 못하는 특성, 관계 등 결과물을 수학적 - 통계적 기법/딥러닝을 통해 도출해낼 수 있다.
(1) 국소표현(local representation) : 단어 자체만 보고 표현 = 이산(discrete)
(2) 분산표현(distributed representation) : 주변을 참고해 단어값 표현 = 연속(continuous)
같이 자주 등장하는 단어가 비슷하여 비슷한값 매핑=> 분산표현 / 주변단어 신경 안쓰고 단어등장빈도수에따라 값부여 => 국소표현

단어표현방법.
- 이산
- one hot vector
- N-gram
- count-based (Bag of words)(DTM)
- 국소
- prediction based
- word2Vec
- count based
- fullDocoument : LSA
- windows : Glove ( +prediction based )
- prediction based
2. BoW (bag of words)
- 단어의 등장 순서를 고려하지 않는
- 빈도수 기반(word frequency)
BoW 과정
(1) 각 단어에 고유한 정수 인덱스를 부여
(2) 각 인덱스의 위치에 단어 토큰의 등장 횟수를 기록한 벡터를 생성
example)
from konlpy.tag import Okt
import re
okt=Okt()
token=re.sub("(\.)","","정부가 발표하는 물가상승률과 소비자가 느끼는 물가상승률은 다르다.") #마침표제거(cleaning)
token=okt.morphs(token)
# OKT tokenizing
word2index={}
bow=[]
for voca in token:
if voca not in word2index.keys():
word2index[voca]=len(word2index)
bow.insert(len(word2index)-1,1)
# BoW 단어 개수 최소 1개 이상=>default 1
else:
index=word2index.get(voca)
bow[index]=bow[index]+1
print(word2index)
------------------------------------
('정부': 0, '가': 1, '발표': 2, '하는': 3, '물가상승률': 4, '과': 5, '소비자': 6, '느끼는': 7, '은': 8, '다르다': 9)
bow = [1, 2, 1, 1, 2, 1, 1, 1, 1, 1] BoW는 주로 특정 단어 빈도수로 어떤 성격의 문서인지 판단하는데 주로 사용된다. (분류/여러문서간 유사도)
불용어 제거 BoW example
사용자정의 불용어
from sklearn.feature_extraction.text import CountVectorizer
text=["Family is not an important thing. It's everything."]
vect = CountVectorizer(stop_words=["the", "a", "an", "is", "not"])
print(vect.fit_transform(text).toarray())
print(vect.vocabulary_)
--------------------------------
[[1 1 1 1 1]]
{'family': 1, 'important': 2, 'thing': 4, 'it': 3, 'everything': 0}nltk지원 불용어
from sklearn.feature_extraction.text import CountVectorizer
from nltk.corpus import stopwords
text=["Family is not an important thing. It's everything."]
sw = stopwords.words("english")
vect = CountVectorizer(stop_words =sw)
print(vect.fit_transform(text).toarray())
print(vect.vocabulary_)
-----------------------------
[[1 1 1 1]]
{'family': 1, 'important': 2, 'thing': 3, 'everything': 0}3. DTM = 문서 단어 행렬(document-term matrix)
다수의 문서에서 등장하는 각 단어들의 빈도를 행렬로 표현한 것
BoW를 여러 문서가 있는 상황을 고려해 문서간 관계를 행렬로 표현하는 것이 DTM.
각 열/행은 하나의 문서/단어 의미
ex)

- dtm[n][m]은 n번째 문서에서 m번째 단어가 등장한 횟수.
=> dtm의 한계는 sparse representation (원-핫 벡터는 단어 집합의 크기가 벡터의 차원이 되고 대부분의 값이 0이 된다는 점에서, 0을 차지하는 메모리 / 계산리소스 증가 비효율)/ 단순 빈도 수 기반 접근으로 유사도 기준을 단순회시켜버림. (ex-> 설탕값 폭등 기사 문서와 설탕의 역사 문서가 어쩌다 단어빈도수가 맞아떨어져 원치 않게 유사문서로 분류될 수 있다. )
=> 정규화를통해 단어집합 크기 줄임 / TF-IDF를통해 중요 단어에 가중치
4. TF-IDF(Term Frequency-Inverse Document Frequency)
여러문서 고려 / 단어빈도수기반
단어가 얼마나 자주 등장하는지와, 특정 단어가 등장하는 문서가 얼마나 많은지(에 대한 반비례하는 수치)를 이용해 각 단어들에 가중치를 부여한다.
=> 가중치를 통해 각 단어 중요도를 계산
TD-IDF
문서 : d, 단어 : t, 문서 총 개수 n일 때,
(1) tf(d,t) : 특정 문서 d에서의 특정 단어 t의 등장횟수 (term frequency)
(2) df(t) : 특정 단어 t가 등장한 문서의 수(docs frequency)
(3)idf(d,t) : df(t)에 반비례하는 수
df(t)가 0에 수렴하면 무한대로 발산하기때문에, 분모에 1을 더해주고, 단어 빈도에 대한 급격한 수치변화를 조정하기위해 log를 사용했는데,
그냥 df(t)에 반비례하는 어떤 수치를 만들고자 해 상기 식이 나옴.(regularization같은 느낌)
TF-IDF에서
- 모든 문서에서 자주 등장하는 단어는 중요도가 낮다고 판단(tf-idf값 낮다)
- 특정 문서에서만 자주 등장하는 단어는 중요도가 높다고 판단(tf-idf값 높다)
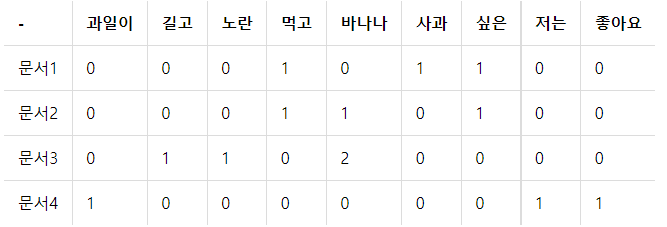
위에서
tf값 = 특정 문서d에서 단어t의 빈도수 : 위의 dtm행렬과 동일.
idf =
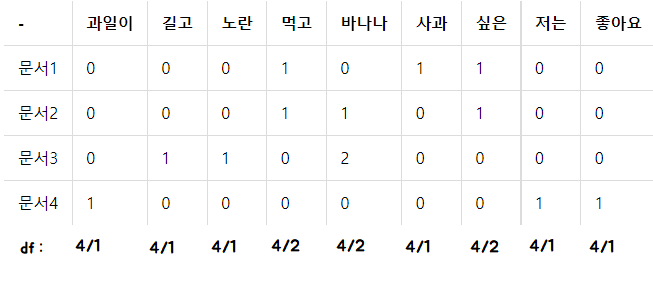
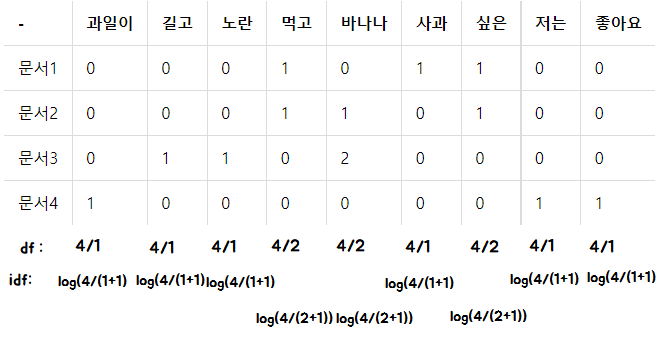
(위에서 4/1은 df가 4/1이라는게 아니라 4문서중 1개라는 의미. df는 각 1,1,1,2,2,1,2,1,1이다)

위의 값으로
문서 1에서는 사과
문서 2에서는 -
문서 3에서는 길고/노란/바나나
문서 4에서는 과일이/저는/싫어요
라는 얼추 키워드가 추려진 결과를 볼 수 있다.
python example(sklearn)
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'you know I want your love',
'I like you',
'what should I do ',
]
vector = CountVectorizer()
print(vector.fit_transform(corpus).toarray()) # 코퍼스로부터 각 단어의 빈도 수를 기록한다.
print(vector.vocabulary_) # 각 단어의 인덱스가 어떻게 부여되었는지를 보여준다
---------------------------------------
[[0 1 0 1 0 1 0 1 1]
[0 0 1 0 0 0 0 1 0]
[1 0 0 0 1 0 1 0 0]]
{'you': 7, 'know': 1, 'want': 5, 'your': 8, 'love': 3, 'like': 2, 'what': 6, 'should': 4, 'do': 0}
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'you know I want your love',
'I like you',
'what should I do ',
]
tfidfv = TfidfVectorizer().fit(corpus)
print(tfidfv.transform(corpus).toarray())
print(tfidfv.vocabulary_)
---------------------------------------
[[0. 0.46735098 0. 0.46735098 0. 0.46735098 0. 0.35543247 0.46735098]
[0. 0. 0.79596054 0. 0. 0. 0. 0.60534851 0. ]
[0.57735027 0. 0. 0. 0.57735027 0. 0.57735027 0. 0. ]]
{'you': 7, 'know': 1, 'want': 5, 'your': 8, 'love': 3, 'like': 2, 'what': 6, 'should': 4, 'do': 0}
