0. Vector Similarity
기계가 계산하는 문서의 유사도의 성능은 각 문서의 단어들을 어떤 방법으로 수치화하여 표현했는지(DTM, Word2Vec 등), 문서 간의 단어들의 차이를 어떤 방법(유클리드 거리, 코사인 유사도 등)으로 계산했는지에 달려있다. => 전자의경우 단어의 (수치화)표현방법 / 후자의경우 vetor similarity
1. Cosine similarity
- 코사인 유사도 : 두 벡터 간의 코사인 각도를 이용하여 구할 수 있는 두 벡터의 유사도
cosine similarity
딥러닝이든 머신러닝이던간에 vector표현 (행렬) 은 중요한 기초 개념인 듯 해
복습겸 한번 돌아보자
내적의 의미는 다음과 같다.
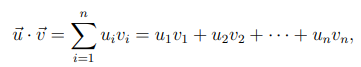

(증명)

- 기본적인 의미는 각 성분들의 곱의 합.
@ 두 기저(basis)가 수직일 때, ex) (0,1) / (1,0) => 성분 곱의 합은 0이다.
=>각 성분의 유사성이 떨어진다
@ 두 기저(basis)가 평행일 때, 그냥 직관적으로 같다. 정규화했을 때 ex) ( (1/(2)^(1/2)),(1/(2)^(1/2)) ) 성분곱이 1이다. => 각 성분의 유사성이 높다
- 기하학적으로 두 벡터가 이루는 사잇각의 코사인값과 벡터크기곱
두기저 수직일 시 => 한 벡터(A)가 다른 벡터(B)에 projection했을 때, A의 길이는 0이된다. 유사성이 0이라고 볼 수 있음.
두 기저 평행일 시 =>projection했을 때 길이가 보존된다(공간이 비슷)
=>vector는 결국 cosine각이 유사성 판단 기준이 될 수 있다. (크기는정규화)
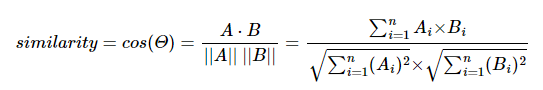
similarity = cosine각 = (A·B)/(||A||*||B||)=성분곱의합/벡터크기곱
cosine similarity 적용 예
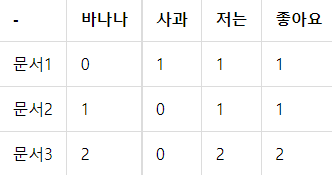
3개의 문서,
문서1 : 저는 사과 좋아요
문서2 : 저는 바나나 좋아요
문서3 : 저는 바나나 좋아요 저는 바나나 좋아요에 대해
from numpy import dot
from numpy.linalg import norm
import numpy as np
def cos_sim(A, B):
return dot(A, B)/(norm(A)*norm(B))
doc1=np.array([0,1,1,1])
doc2=np.array([1,0,1,1])
doc3=np.array([2,0,2,2])
print(cos_sim(doc1, doc2)) #문서1과 문서2의 코사인 유사도
print(cos_sim(doc1, doc3)) #문서1과 문서3의 코사인 유사도
print(cos_sim(doc2, doc3)) #문서2과 문서3의 코사인 유사도
#---------------------------------#output
0.67
0.67
1.00
=> doc2,3은 크기만 다를 뿐 방향이 같은 벡터이기 때문에 유사도가 1.
3. cosine 유사도 이용 추천시스템 example)
간단하게 tf-idf지수의 cosine similarity를 통해 영화 제목-줄거리overview간 유사성을 파악하는 결과를 보여주는 예제.
(1) 데이터 로드
data ) https://www.kaggle.com/rounakbanik/the-movies-dataset
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import linear_kernel
import os
from google.colab import drive
drive.mount('/content/drive') #googledrive mount
data = pd.read_csv('./drive/MyDrive/movies_metadata.csv', low_memory=False) #data load
data.head(2)
| i | ... | original_title | overview | ... | title | video |
|---|---|---|---|---|---|---|
| 0 | ... | Toy Story | Led by Woody, Andy's toys live happily in his ... 중략 ... | ... | Toy Story | False |
| 1 | ... | Jumanji | When siblings Judy and Peter discover an encha ... 중략 ... | ... | Jumanji | False |
데이터셋은 kaggle의 The Movies Dataset이며,
cosine similarity 대상feature는 title column과 overview column.
=> goal은 영화 입력 시 해당 영화의 줄거리와 줄거리가 유사한 영화를 찾아서 추천하는 시스템
(2) 데이터 샘플 및 결측치 제거
data = data.head(20000)
data['overview'].isnull().sum() #135
# overview에서 Null 값을 가진 경우에는 Null 값을 제거
data['overview'] = data['overview'].fillna('')
sample 데이터 20000개로 추린 후 결측치 제거(NULL to 공백)
(3) tf-idf
tfidf = TfidfVectorizer(stop_words='english')
# overview에 대해서 tf-idf 수행
tfidf_matrix = tfidf.fit_transform(data['overview'])
#print(tfidf_matrix.shape) # (20000, 47487)tf-idf를 구한다. => 이 때 TfidfVectorizer를 이용 overview docs에서 token split -> token과 문서간 빈도수 행렬인 tf행렬생성 -> idf계산->tfidf_matrix 해줌.
아래는 tfmatrix 대략적인 생김새 ( 0번문서와 809번 token tf-idf=0.1506886..)
(0, 809) 0.15068863901965732
(0, 210) 0.15068863901965732
(0, 1657) 0.11703946979728948
(0, 998) 0.1211799516296032
(0, 904) 0.13979786049282722
(0, 2042) 0.13207073015643328
(0, 2557) 0.15068863901965732
(0, 524) 0.13979786049282722
(0, 2145) 0.15068863901965732
(0, 1332) 0.13207073015643328
(0, 2122) 0.11703946979728948
(0, 1725) 0.13979786049282722
(0, 106) 0.15068863901965732
(0, 2510) 0.13979786049282722
..
.. (4) cosine similarity & index
cosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)
indices = pd.Series(data.index, index=data['title']).drop_duplicates() #타이틀 입력시 인덱스 리턴 용도
print(indices.head()) #5개만 출력
--------------------------------------------
title
Toy Story 0
Jumanji 1
Grumpier Old Men 2
Waiting to Exhale 3
Father of the Bride Part II 4
dtype: int64sckit learn의 from sklearn.metrics.pairwise import linear_kernel을 이용해
cosine similarity 계산.
#cosine_sim
(20000, 20000)
[[1. 0.01575748 0. ... 0. 0. 0. ]
[0.01575748 1. 0.04907345 ... 0. 0. 0. ]
[0. 0.04907345 1. ... 0. 0. 0. ]
...
[0. 0. 0. ... 1. 0. 0.08375766]
[0. 0. 0. ... 0. 1. 0. ]
[0. 0. 0. ... 0.08375766 0. 1. ]]20000개 샘플셋에 대해 각 데이터간 cosine similarity를 구해 저장한 행렬. cosine_sim[n][m]은 n번째 데이터셋과 m번째 데이터셋의 overview의 consine similarity.
(5) cosine smilarity 이용해 overview 유사한 10개의 영화 return하는 함수
def get_recommendations(title, cosine_sim=cosine_sim):
# 선택한 영화의 타이틀의 인덱스 저장
idx = indices[title]
# 모든 영화에 대해서 해당 영화와의 유사도 구함
sim_scores = list(enumerate(cosine_sim[idx]))
# 유사도에 따라 영화 정렬
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# 가장 유사한 10개의 영화
sim_scores = sim_scores[1:11]
# 가장 유사한 10개의 영화의 인덱스
movie_indices = [i[0] for i in sim_scores]
# 가장 유사한 10개의 영화의 제목을 리턴
return data['title'].iloc[movie_indices](6) overview가 유사한 영화 찾기
get_recommendations('The Dark Knight Rises')
------------------------------------------------
12481 The Dark Knight
150 Batman Forever
1328 Batman Returns
15511 Batman: Under the Red Hood
585 Batman
9230 Batman Beyond: Return of the Joker
18035 Batman: Year One
19792 Batman: The Dark Knight Returns, Part 1
3095 Batman: Mask of the Phantasm
10122 Batman Begins
Name: title, dtype: object