본 포스팅은 서울대학교 강필성 교수님의 강의를 바탕으로 작성되었습니다.
AE (AutoEncoder)
Encoder 와 Decoder 로 구성되어 입력 이미지를 다시 복원하도록 학습하는 모델 구조이다.
-
Encoder 는 입력 이미지를 저차원 잠재공간(latent space)으로 매핑하여 잠재변수 로 변환한다.
- 여기서 잠재변수 는 반드시 입력 데이터보다 차원이 낮아야 한다. 그래야 정보의 압축과 효율성이 일어난다.
-
Decoder 는 잠재변수를 입력으로 사용하여 원본 이미지를 복원한다.
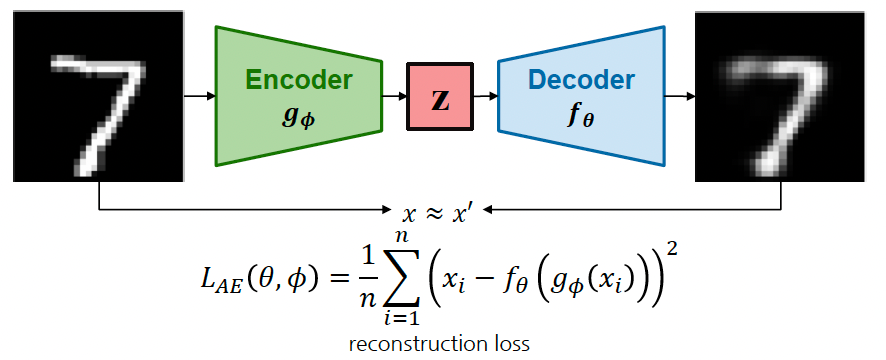
위의 수식에서 와 는 학습되는 파라미터를 의미하고, 라는 객체를 주었을 때는 라는 인코더에 넣어서 잠재변수를 만드는 것이다. 잠재변수를 디코더에 투입하여 원본을 복원했을 때, 원래 데이터와 복원된 데이터 사이의 차이를 가장 최소화시키는 것이다.
모델 학습을 위한 목적함수로는 reconstruction loss를 사용한다. 일반적으로 MSE(Mean Squared Error) 또는 MAE(Mean Absolute Error)를 활용한다.
VAE (Variational AE)
VAE는 Autoencoder와 동일하게 Encoder와 Decoder로 구성되어 있지만 잠재공간의 (가우시안) 분포를 가정하여 학습하는 구조이다.
Encoder를 학습했을 때, 가 가질 수 있는 가우시안 분포의 평균, 분산을 학습하게 되고, 노이즈를 주어 이 세 가지를 합쳐 를 샘플링을 한 다음에 다시 디코딩을 하는 과정을 거친다.
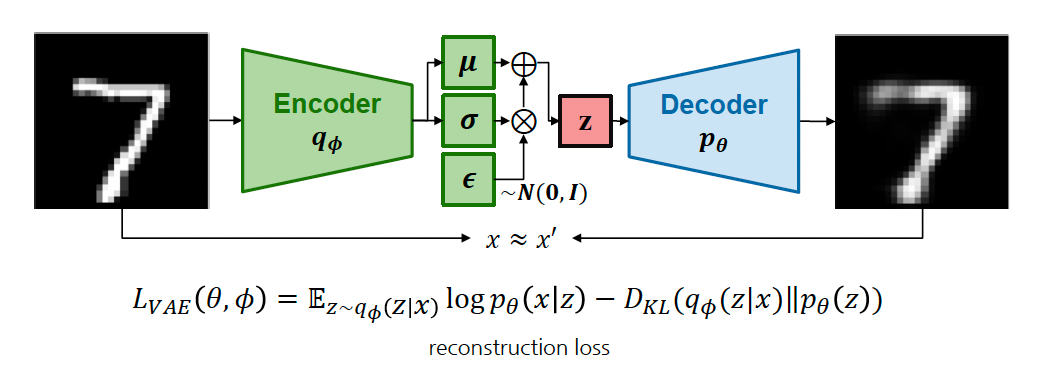
가 주어졌을 때, 가 만들어질 확률이 가장 높은 부분 (reconstructed loss)과 에 대한 의 확률과 가 주어졌을 때 잠재공간의 에 대한 확률밀도함수가 가깝게 하기 위해 KL divergence도 함께 사용한다.
정리하면, 모델 학습을 위한 목적함수로는 reconstruction loss 뿐만 아니라 사전에 정의한 잠재공간에 대한 분포를 학습에 반영하기 위해 KL divergence를 함께 정의한다.
VQ-VAE (Vector Quantized-VAE)
VQ-VAE는 연속적인 잠재공간이 아닌 이산적인 잠재공간을 가정하여 학습에 사용한다. 이산적인 잠재공간(0, 1)은 이미지 뿐만 아니라 텍스트, 음성과 같은 데이터에 더 적합하게 사용하는 방식이다.
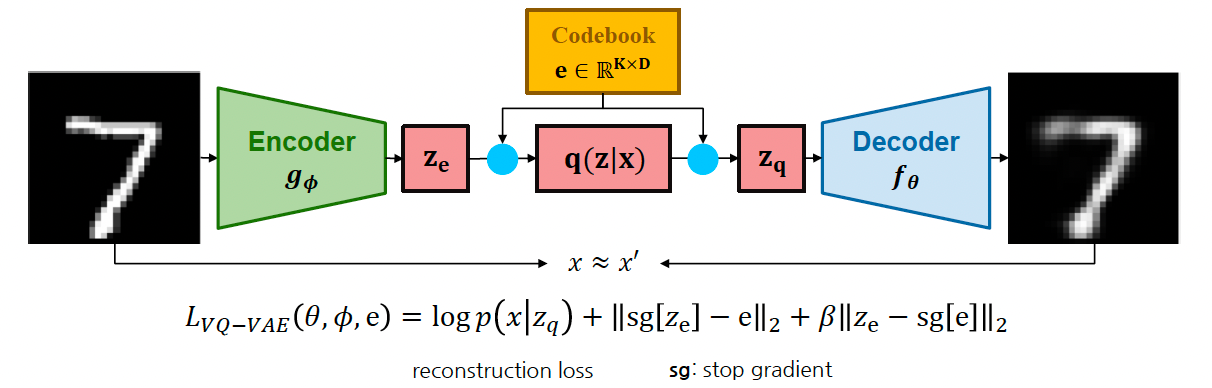
라고 하는 개의 차원에 대한 codebook을 사용하며, 이 codebook은 학습을 하고자 하는 대상이다.
VQ-VAE에서 정의한 잠재공간(Codebook)은 사전에 정의한 K개의 임베딩으로 정의된다. 모델 학습을 위한 목적함수로는 reconstruction loss에 추가로 e와 encoder를 stop-gradient를 통해 따로 계산한다.
