본 포스팅은 Upstage의 박찬준 마스터님 강의를 바탕으로 작성되었습니다.
Data-Centric AI
AI System
AI system은 모델과 알고리즘에 활용되는 code와 data로 구성되어 있습니다.
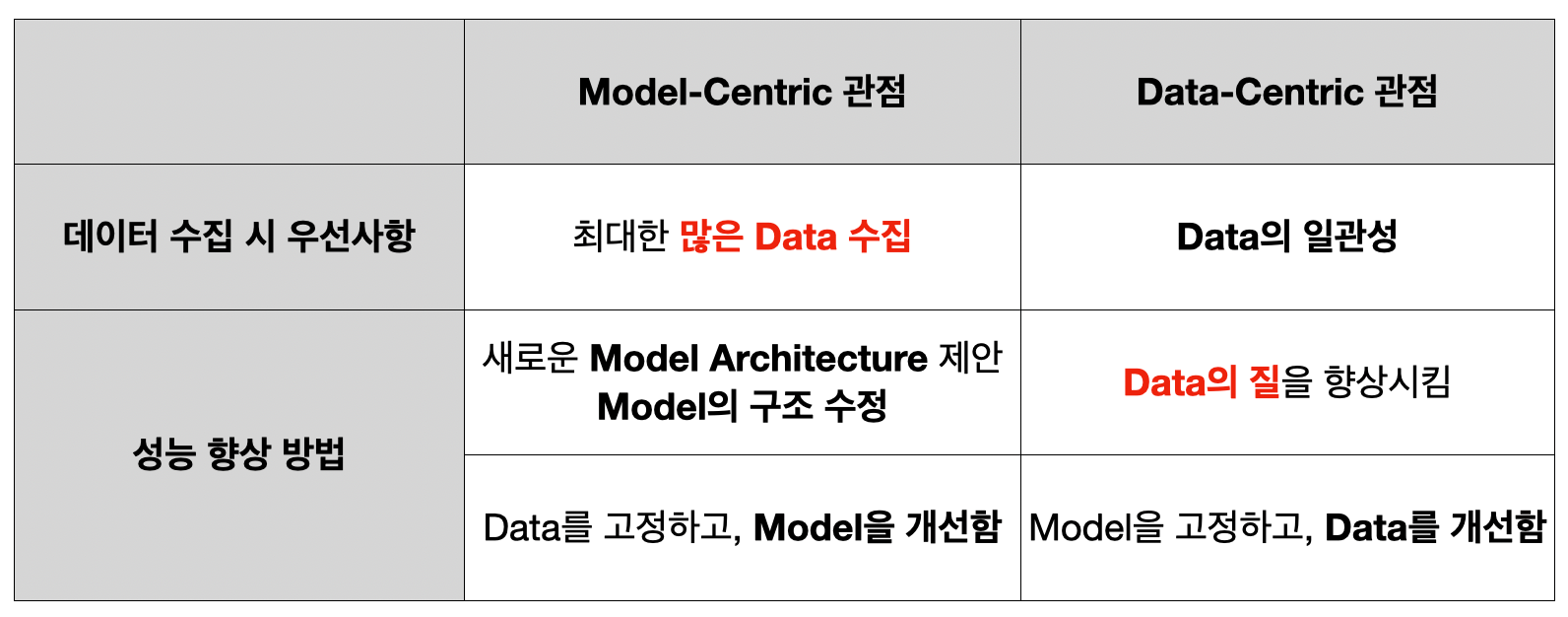
여기서 Data-centric AI는 코드가 아닌 데이터에 집중하여 모델링을 통한 성능 향상이 아닌 데이터를 통한 성능 향상을 하는 방식을 의미합니다.
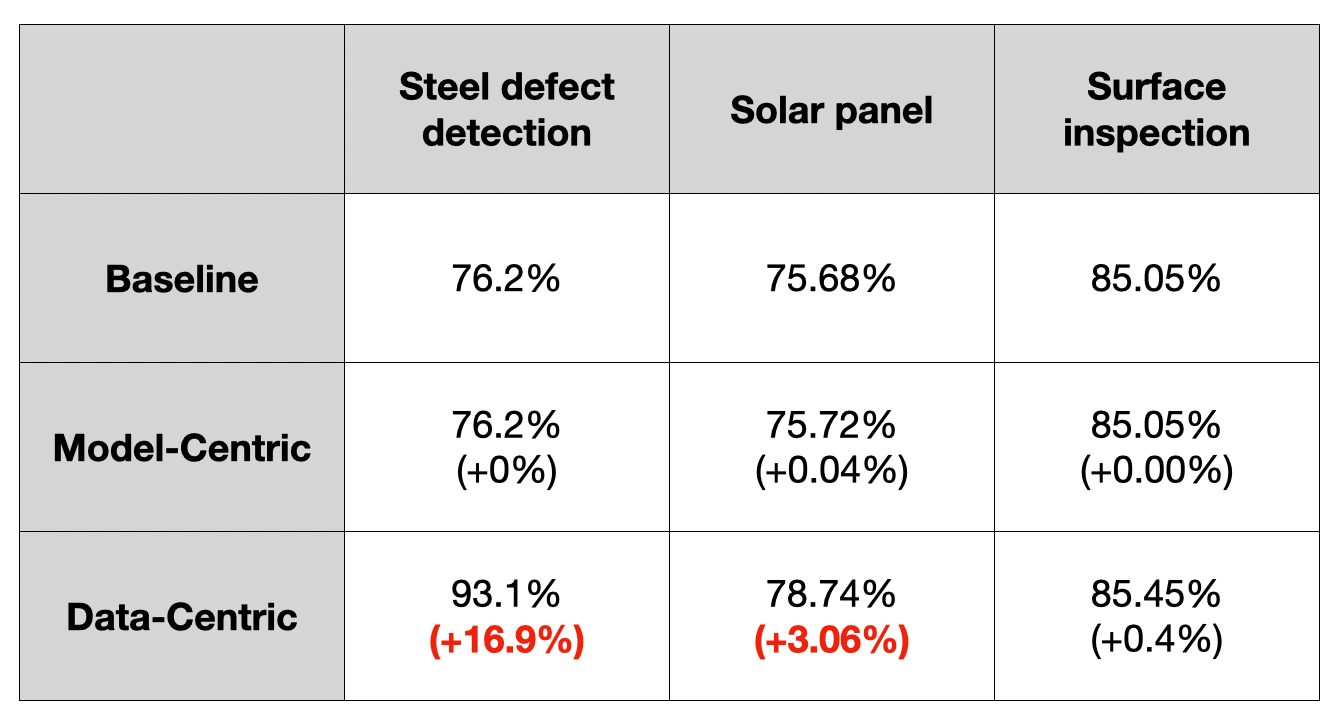
위의 표는 Model-centric과 Data-centric의 성능 향상을 비교한 것입니다. 표에서 확인할 수 있듯이, 모델링보다 데이터 중심으로 한 것이 성능 향상에 훨씬 더 도움을 줄 수 있음을 보여줍니다.
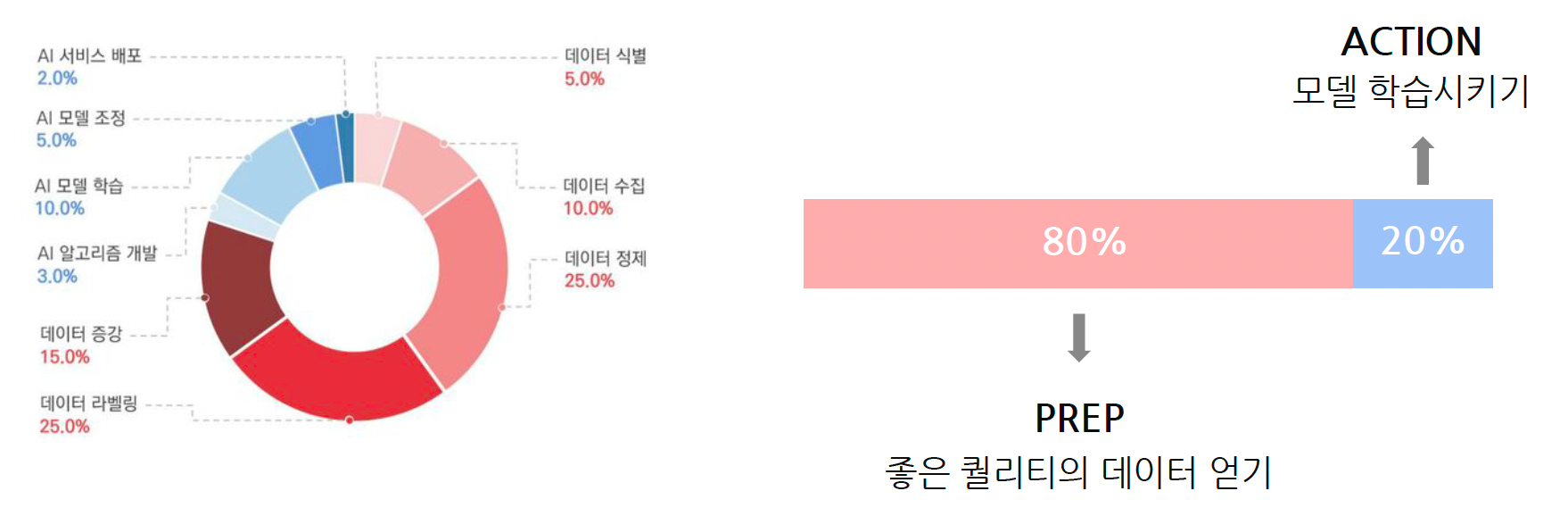
AI 프로젝트를 진행하기 위해서는 데이터 식별, 데이터 수집, 데이터 정제, 데이터 라벨링, 데이터 증강과 같은 데이터 단계와 AI 알고리즘 개발, 모델 학습, 모델 조정, AI 서비스 배포와 같은 모델링 단계를 거쳐야 합니다. 위의 그림에서 알 수 있듯이, 전체 프로세스 중 80%가 데이터 단계가 차지할 정도로 좋은 퀄리티의 데이터를 얻는 것이 중요합니다.
개발 사이클
AI service의 개발 사이클은 크게 4가지 단계로 나눌 수 있습니다.
1. Project Setup : 프로젝트 정의
2. Data Preparation : 데이터셋 준비
3. Model Training : 모델 학습 및 디버깅
4. Deploying : 설치 및 유지보수
Definition of Data-Centric AI
-
성능 향상을 위해 Data 관점에서 고민하는 것. (즉, 코드와 알고리즘은 수정없이 고정해놓는 것)
-
Model Modification 없이 모델의 성능을 향상시키는 방법을 의미
-
Data-Centric Evaluation
- 모델의 성능 평가 지표 개발
- Data Measurement
Examples
- Outlier Detection and Removal
- Error Detection and Correction
- Data Augmentation
- Feature Engineering and Selection
- Establishing Consensus Labels
- Active Learning
- Curriculum Learning
In the Wild (in Real-World)
실제 현업이나 기업에서는 Data-Centric AI를 어떻게 활용하는지에 대해서 살펴보겠습니다.
(1) Data-Flywheel
Data-Flywheel은 데이터를 수집하고 학습하여 모델 성능을 향상시키고, 이를 통해 얻어진 성능이 다시 데이터를 더 많이 수집할 수 있는 기회를 만드는 방식입니다. 즉, Data-Centric 방식으로 반복적인 개선 과정에 초점을 맞춘 선순환 구조를 의미합니다.
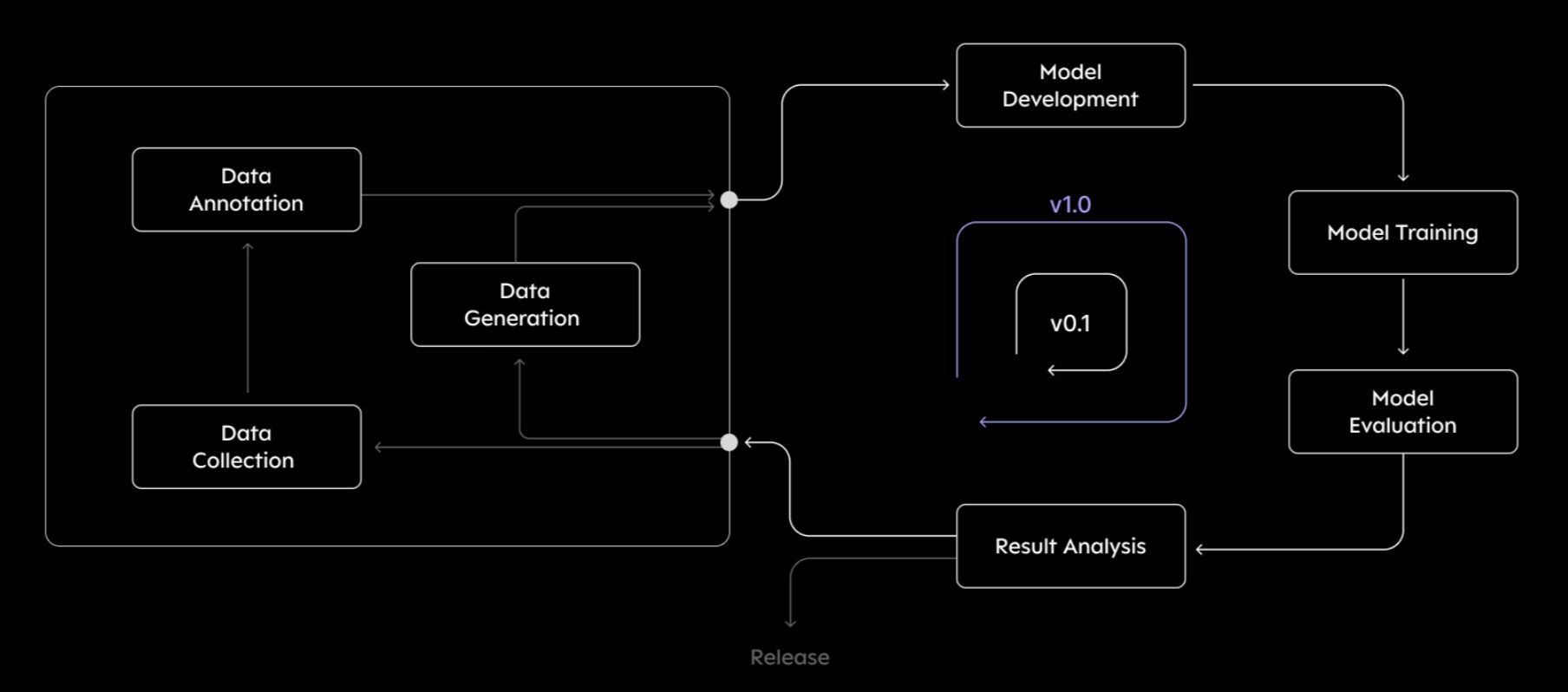
이렇게 Data-Flywheel은 데이터가 많아질수록 모델이 점점 더 개선되며, 이를 통해 시스템 성능을 최적화할 수 있는 강력한 전략이 됩니다. AI 모델을 운영하는 기업에서 주로 사용되며, 특히 추천 시스템, 광고 시스템, 검색 엔진 등에서 높은 성과를 내는 데 도움이 됩니다.
(2) DMOps (Data Management Operations)
DMOps는 데이터의 수집, 저장, 처리, 관리, 보안, 거버넌스 등을 포괄적으로 관리하여 데이터의 품질과 활용성을 높이는 일련의 작업을 의미합니다. MLOps, DevOps 등과 유사하게 데이터와 관련된 모든 운영 프로세스를 효율적으로 통합하고 자동화하여 데이터 기반 프로젝트의 성과를 극대화하는 데 초점을 둡니다. 이를 통해 데이터 팀은 데이터 관리에 필요한 일상적인 작업을 보다 빠르고 신뢰성 있게 수행할 수 있습니다.
구체적인 내용에 대해서는 다음 포스팅에서 다룰 예정입니다.
(3) Data Labeling Tool
Data labeling tool은 모델 학습에 필요한 데이터를 수동 또는 자동으로 라벨링할 수 있도록 돕는 도구입니다. 해당 도구는 Labelbox, SuperAnnotate, Amazon SageMaker Ground Truth, Scale AI 등이 있으며, 이들은 라벨링 효율성을 높이고 품질을 보장하여 고품질 학습 데이터를 구축하는 데 도움을 줍니다.
(4) ChatGPT
In Academia
학계에서는 기업과 현업에서와 달리 데이터를 다루기 힘든 여러 가지 이유가 있습니다.
-
좋은 데이터를 많이 모으기 힘들고, 데이터는 아직 미지의 영역이다.
-
라벨링 작업에 대한 명확한 정답이 없고 비용이 크다.
- 라벨링을 하는 것은 주관성이 들어가기 때문에 라벨링의 개수가 많아질수록 정확도가 올라가는 것이 아닙니다.
- 또한 라벨링 기준이 모두 다르기 때문에, 비용이 많이 발생합니다.
-
High Quality Data가 필요하다.
- 즉, 데이터의 양이 중요한 것이 아닌, 데이터의 질을 높여야 합니다.
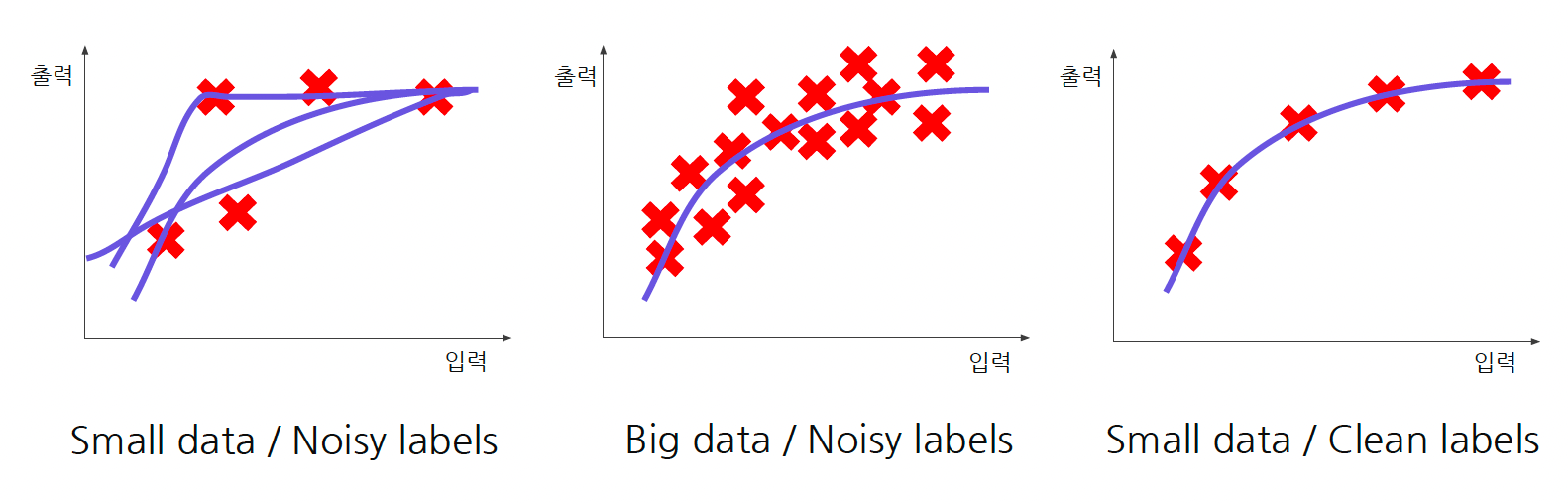
- 즉, 데이터의 양이 중요한 것이 아닌, 데이터의 질을 높여야 합니다.
-
데이터의 균형이 맞아야 한다.
- 비록 데이터의 양이 적을지라도, 데이터가 골고루 있어야 합니다. (balance)
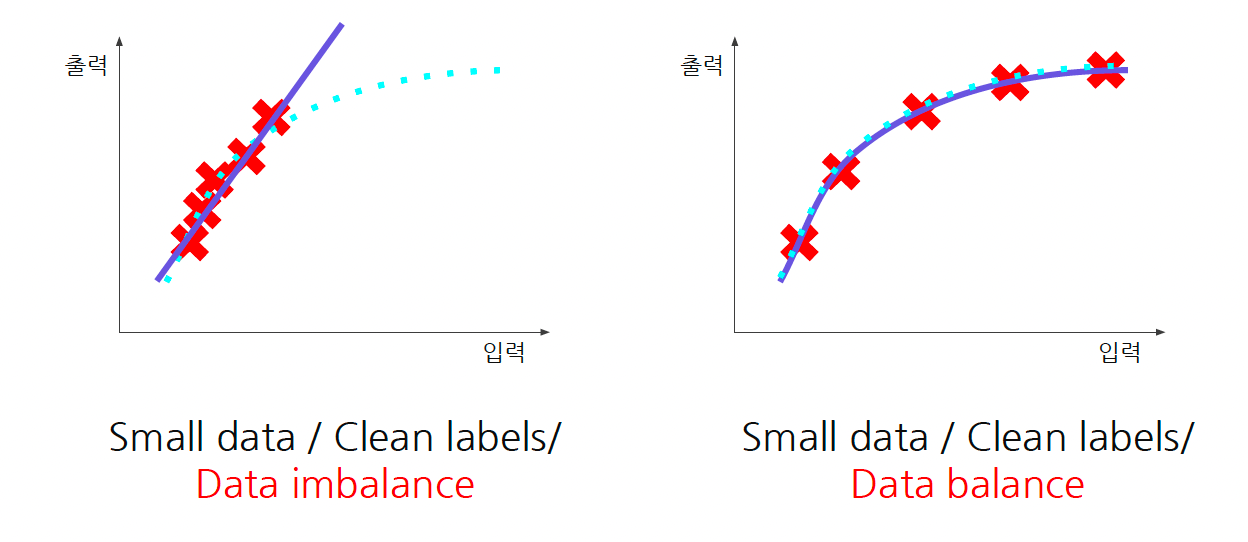
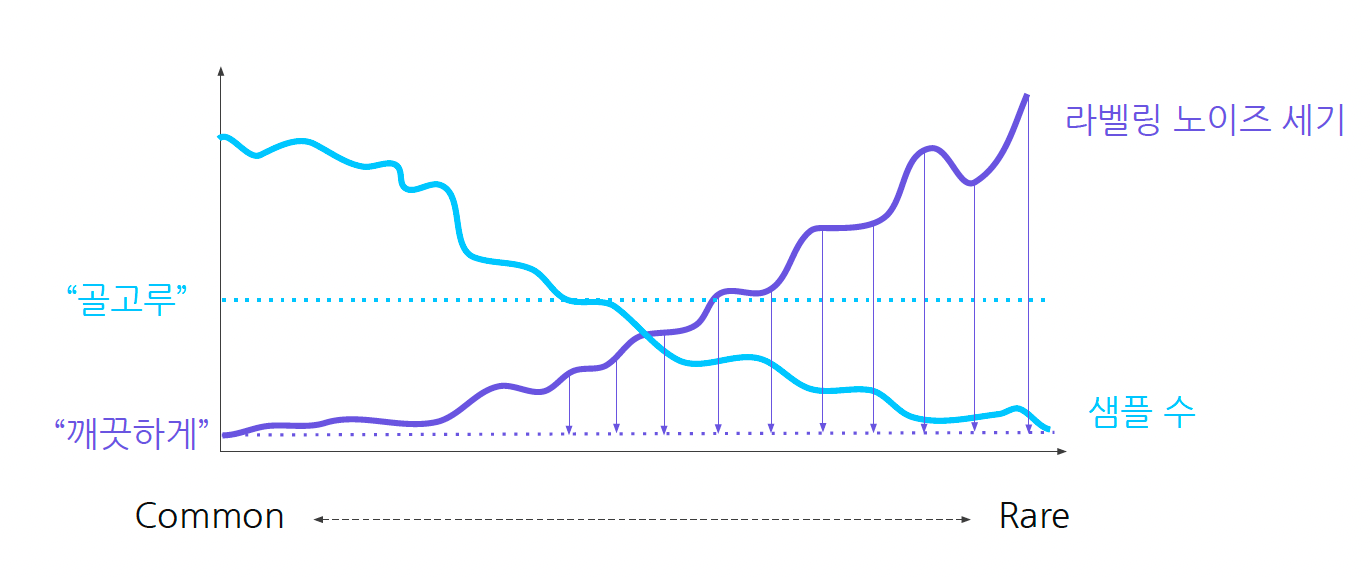
- 비록 데이터의 양이 적을지라도, 데이터가 골고루 있어야 합니다. (balance)
-
학계는 정해진 테스트셋 내에서 경쟁하는 방식이다.
- 그러나 현실 세계에서는 주어진 요구사항에 맞춰 성능을 향상합니다.
- 또한 서비스 요구사항에 맞는 데이터셋만을 필요로 합니다.
Good Data
좋은 데이터는 보통 아래와 같은 데이터를 지칭합니다. 따라서, 좋은 데이터셋을 구성하기 위해서는 특이 케이스를 발견하여 해당 샘플들을 모으고, 아래의 기준을 포함한 라벨링 가이드를 만들어야 합니다.
- 일관성 있게 라벨링된 데이터
- 중요한 케이스가 포함된 데이터
- 예상치 못한 케이스까지 포함한 데이터
- 적절한 크기의 데이터
