NLP/LLM
1.Sparse Passage Retrieval

Passage Retrieval (문서 검색) Passage Retrieval은 질의(Query)에 맞는 문서(Passage)를 찾는 과정을 의미한다. 위의 그림을 간단하게 설명하면, Quer
2.Dense Passage Retrieval

모든 단어를 벡터 공간 상에 표현하기 때문에 차원의 수가 매우 크다. (이는 compressed format으로 어느 정도 해결할 수 있음) zero values가 많다.Term overlap으로 측정하기 때문에 유사성을 고려하지 못한다.
3.Passage Retrieval - Scaling Up with FAISS
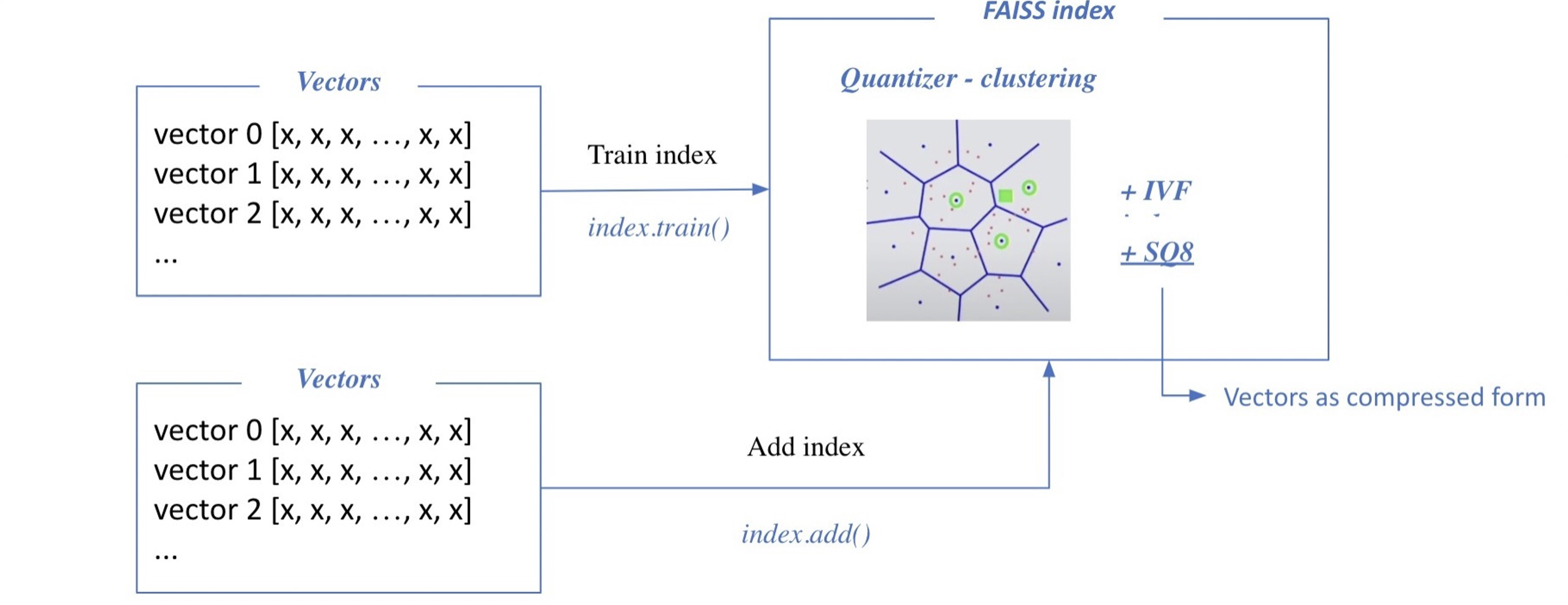
이전 포스팅에서 사용한 검색 방법은 brute-force(exhaustive) search 로, 저장해둔 모든 Sparse/Dense Embedding에 대해 일일이 내적값을 계산하여 가장 값이 큰 passage를 추출하는 방식을 활용했다. 그러나 이 방법은 Passa
4.Reducing Training Bias
Inductive bias : 학습 시, overfitting을 막거나 사전 지식을 주입하기 위해 특정 형태의 함수를 선호하는 것을 의미한다.Historical bias : 현실 세계가 편향되어 있기 때문에 모델에 원치 않는 속성이 학습되는 것을 의미한다. Co-occ
5.MRC (Machine Reading Comprehension)
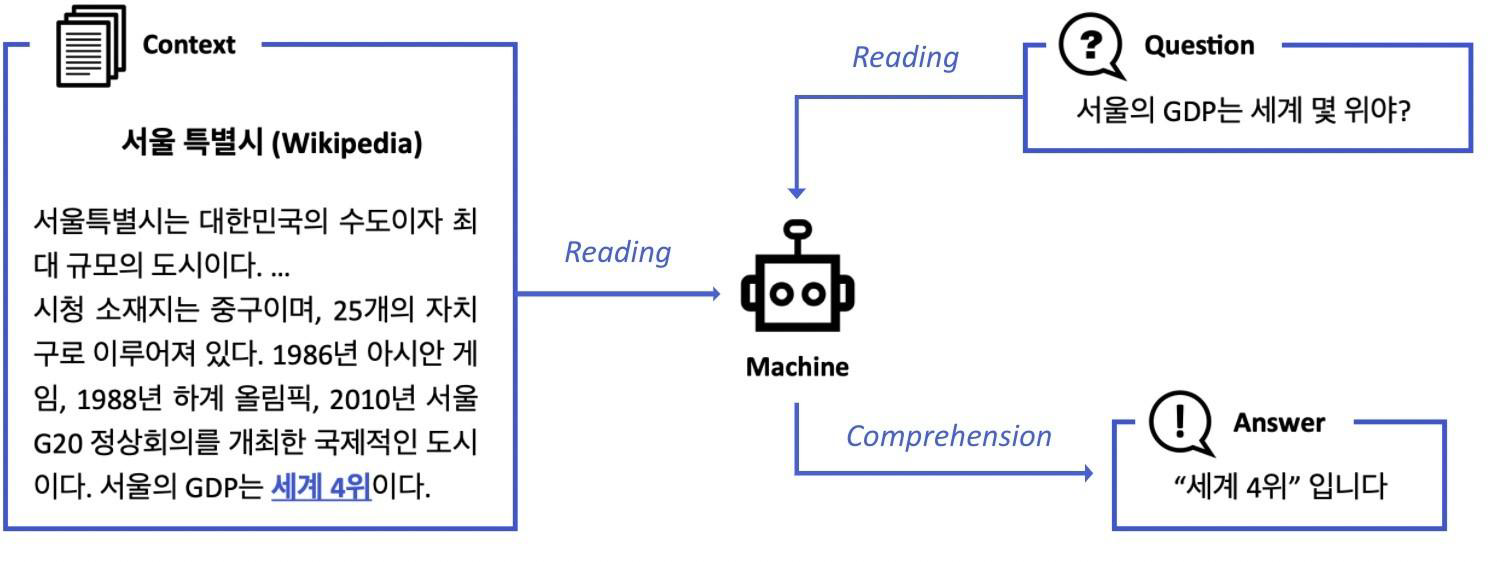
주어진 지문 (context)를 이해하고, 주어진 질의 (Query)의 답변을 추론하는 문제를 MRC라고 한다.이는 검색엔진에서도 활용되는데, 만약 "세상에서 가장 긴 강의 길이는 얼마야?"라는 질의를 던지면, 위의 그림과 같이 6,695km (4,160 miles)라
6.Data-Centric NLP

본 포스팅은 Upstage의 박찬준 마스터님 강의를 바탕으로 작성되었습니다.AI system은 모델과 알고리즘에 활용되는 code와 data로 구성되어 있습니다. 여기서 Data-centric AI는 코드가 아닌 데이터에 집중하여 모델링을 통한 성능 향상이 아닌 데이터
7.[NLP] Encoder-Decoder Model
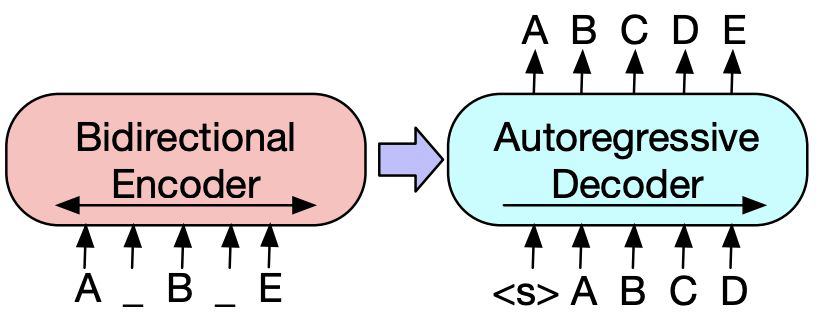
본 포스팅은 이준범 마스터님의 강의를 바탕으로 작성되었습니다.주로 Transformer, BART, T5 등에서 Encoder-Decoder 모델을 사용하고 있다. Encoder에서 정보를 해석하고, Decoder에서 생성하는 형태로 구성되어 있다. (즉, Encode
8.[NLP] Encoder-Only Model
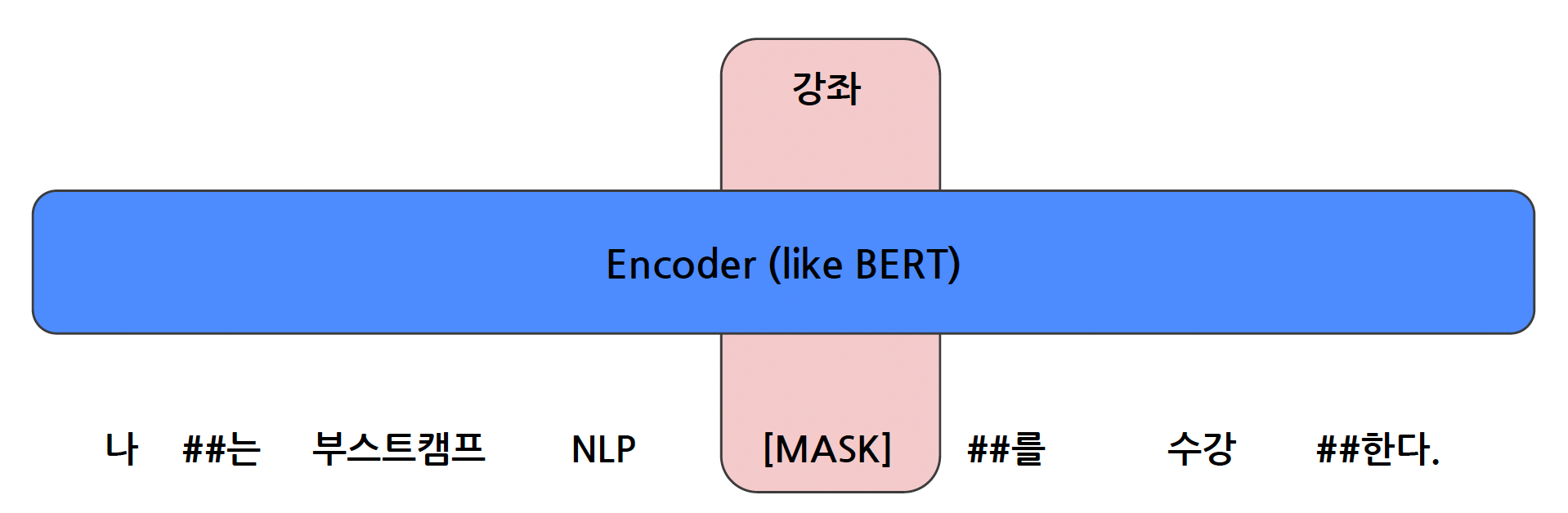
본 포스팅은 이준범 마스터님의 강의를 바탕으로 작성되었습니다.Mask 토큰을 예측하는 형태로 모델을 학습시키는 방식으로, Masked Language Model 중 하나이다.Self-supervised learning 방식을 활용하여, 입력 문장에 Mask 토큰을 넣어
9.[NLP] Decoder-Only Model, LLM

본 포스팅은 이준범 마스터님의 강의를 바탕으로 작성되었습니다.Causal Language Model 방식으로 학습이 됐다.이는 앞 토큰 및 문맥을 통해서, 그 이후의 토큰을 예측하는 "Next Token Prediction" 방식을 통해서 학습되는 것을 의미한다.BER
10.[NLP] Decoder-Only Model, LLaMA
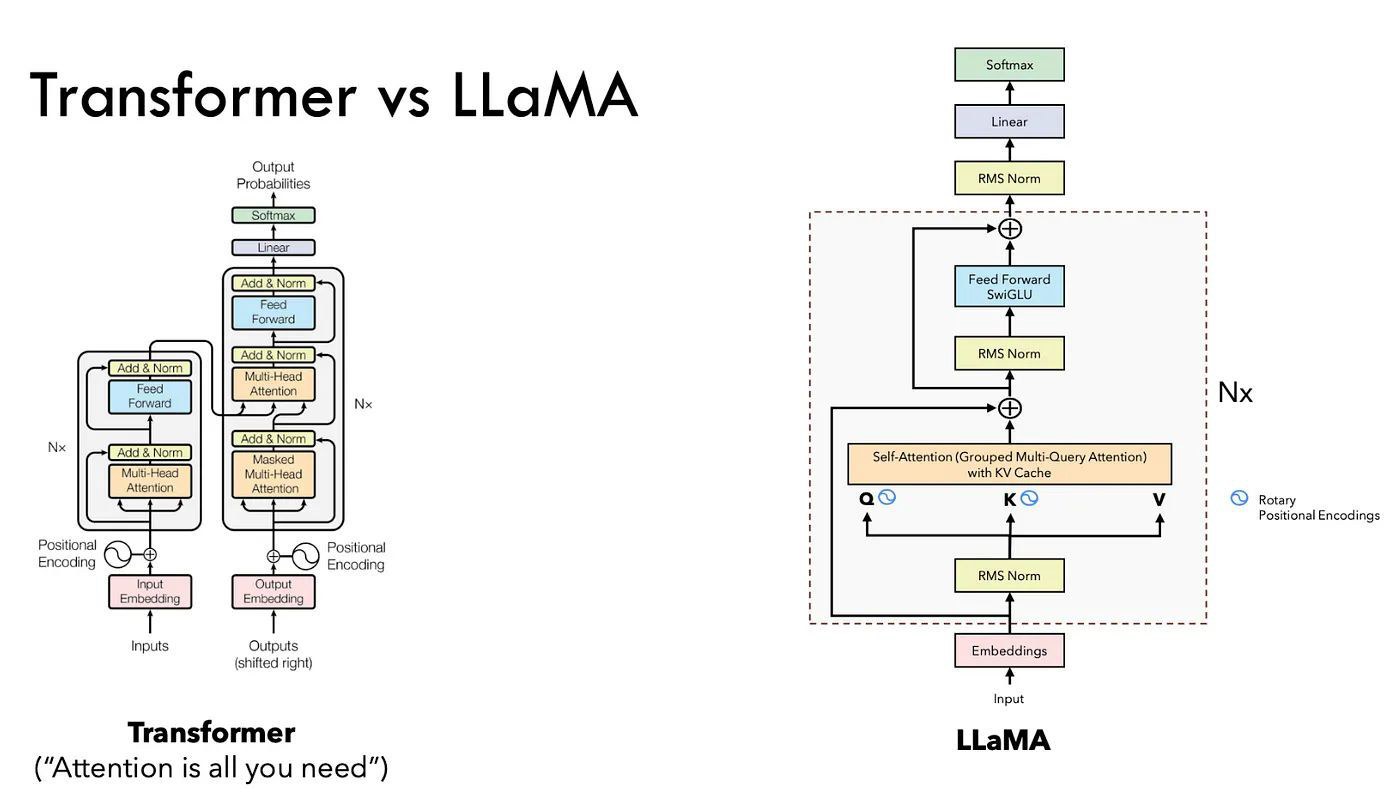
Auto Regressive : 이전에 생성된 토큰을 기반으로 한 순차적 예측Self-Attention : 시퀀스 내 단어들 간의 관계에 집중Causal Masking : 이후 토큰을 차단하여 순차적 생성 순서를 보장Meta에서 출시한 오픈소스 LLMAutoRegres
11.[NLP] Evaluation for LLM
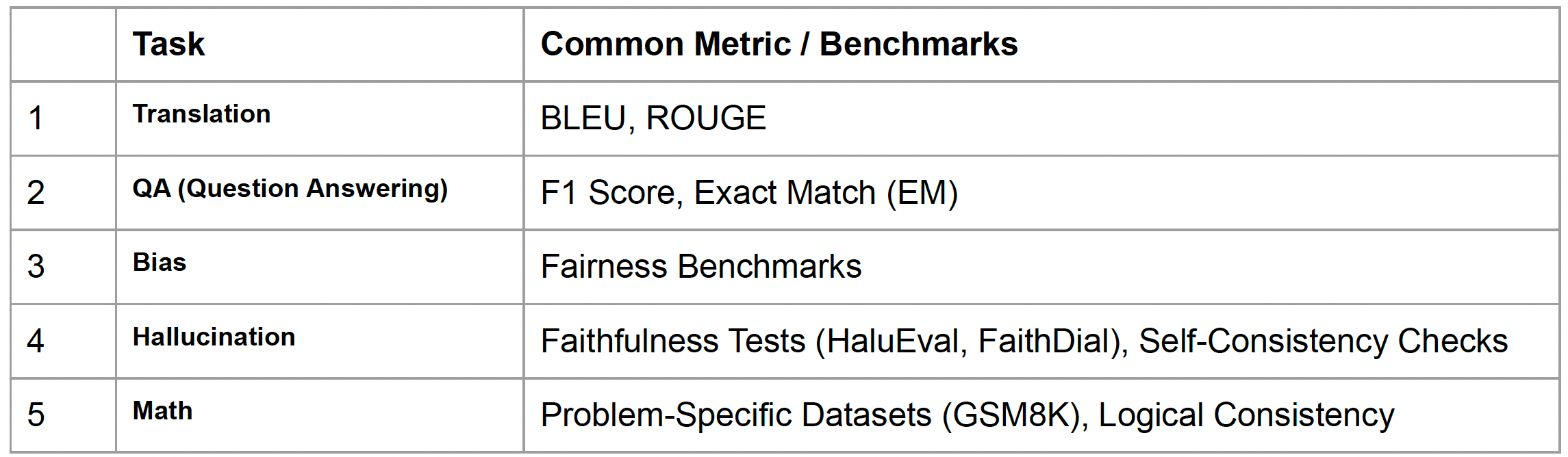
본 포스팅은 이준범 마스터님의 강의를 바탕으로 작성되었습니다. LLM은 굉장히 범용적이기 때문에, Translation, QA, Bias, Hallucination, Math 등 여러 분할된 Task를 종합적으로 확인해야 한다. 아래의 표처럼 각 Task 별로 다양한
12.[NLP] Long Context
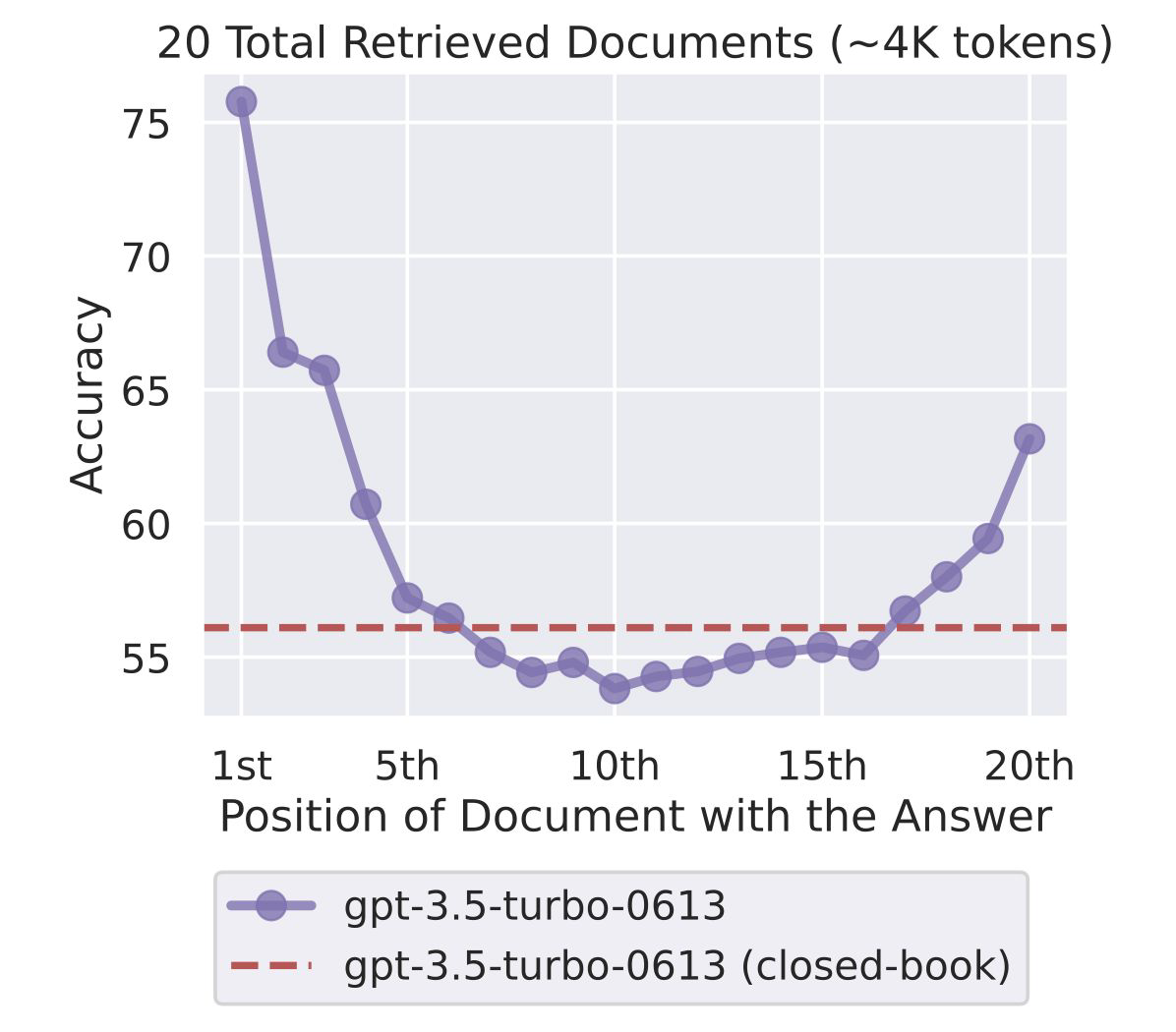
본 포스팅은 이준범 마스터님의 강의를 바탕으로 작성되었습니다. Long Context Models Long Context LLM In-Context Learning 같은 경우, few-shot을 사용하는데 이 자체가 input context로 사용되기 때문에, con
13.[NLP] Inference System①: Text Generation
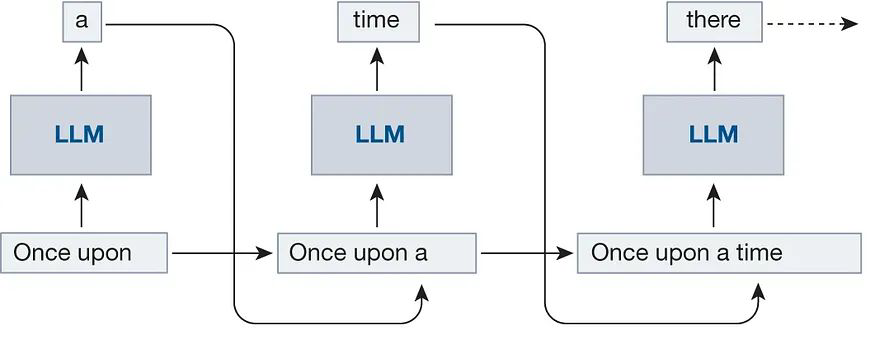
본 포스팅은 이준범 마스터님의 강의를 바탕으로 작성되었습니다.LLM은 다음 토큰을 예측하도록 학습되는데, 기본적으로 CLM 방식으로 학습되기 때문에 Next token prediction 방식과 동일하게 inference를 수행한다. Decoding은 압축된 벡터에서
14.[NLP] Inference System②: 추론 최적화
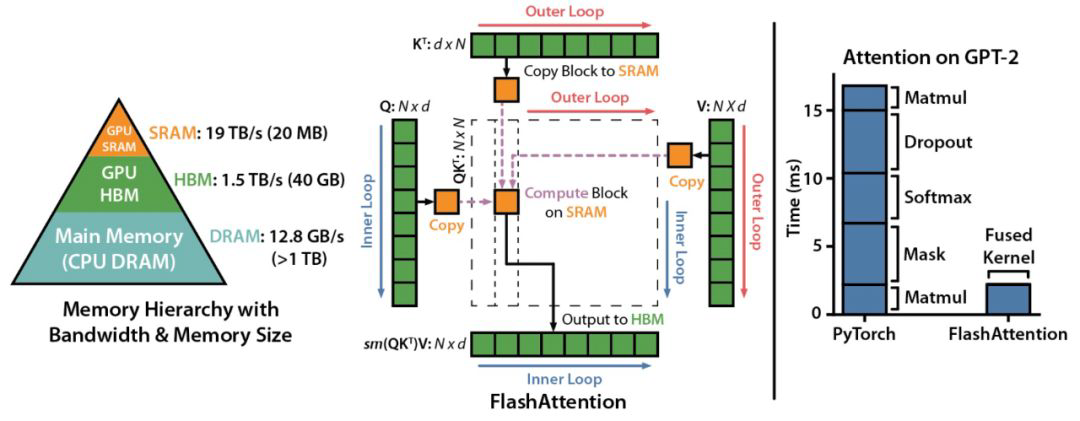
본 포스팅은 이준범 마스터님의 강의를 바탕으로 작성되었습니다.Attention 계산 시 HBM으로의 access 과정에서 생기는 비효율을 해결하기 위해 등장하였다.구체적으로 IO communication (HBM과 SRAM 사이)에서 bottleneck이 발생하는 문제
15.[NLP] Inference System③: 추론 시스템
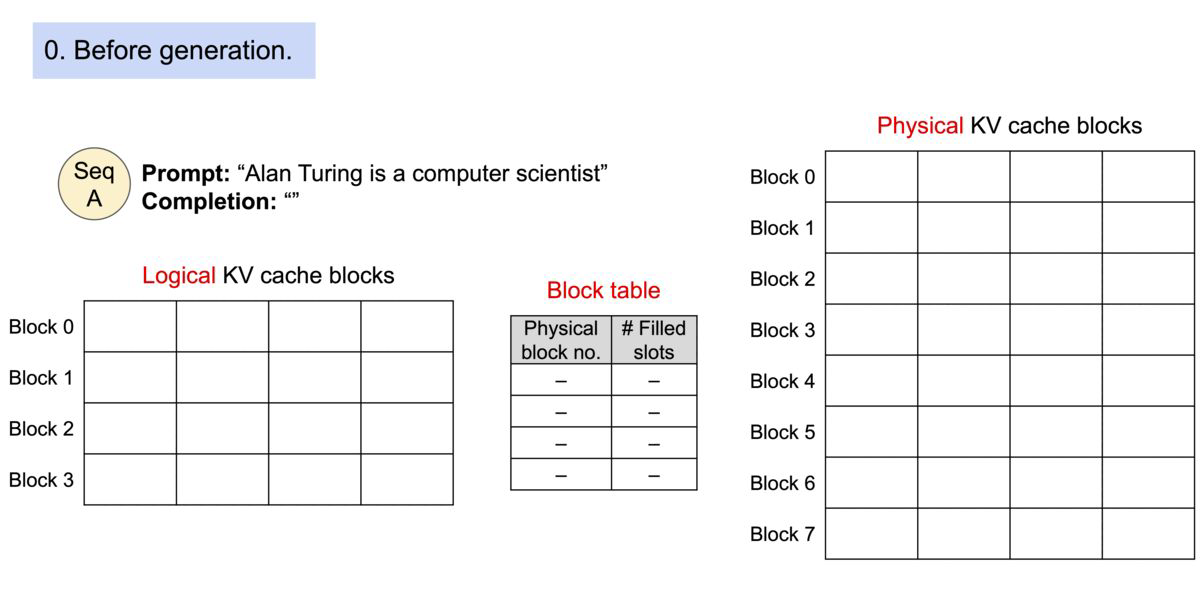
본 포스팅은 이준범 마스터님의 강의를 바탕으로 작성되었습니다.LLM을 위한 고성능 추론 프레임워크Python 기반 개발PagedAttention을 통한 Attention Key, Value 메모리의 효율적인 관리FlashAttention을 통합한 최적화된 CUDA ke
16.[NLP] LLM Evaluation Methods

본 포스팅은 서울대학교 강필성 교수님의 강의를 바탕으로 작성되었습니다. LLM 평가시 고려사항 LLM 평가는 기존 태스크 수행 능력 평가와 상이 | |LLM 평가|기존 태스크 수행능력 평가| |:---:|:---:|:---:| |평가 목적|LLM의 범용 태스크 수행