
본 포스팅은 서울대학교 강필성 교수님의 강의를 바탕으로 작성되었습니다.
LLM 평가시 고려사항
- LLM 평가는 기존 태스크 수행 능력 평가와 상이
| LLM 평가 | 기존 태스크 수행능력 평가 | |
|---|---|---|
| 평가 목적 | LLM의 범용 태스크 수행능력 | 모델 해당 태스크 수행능력 |
| 평가 데이터 | 범용적 능력 평가 데이터 | 해당(개별) 태스크 데이터 |
| 평가 방법론 | 각 태스크 별 상이 | 태스크 평가 파이프라인 및 계산 방법론 |
LLM 평가 목적
"다양한 태스크에 대해 적절한 답변을 출력할 수 있는가?"와 같은 태스크 수행능력과 "답변 내 위험하거나 편향된 내용은 없는가?"와 같은 Safety(안정성) 평가를 하기 위함
- 수행 태스크 범위
- 이는 한정되어 있지 않지만, 태스크 관점에서 코드 작성, 스토리 생성, 제안서 작성, 자기소개서 수정, 문서 요약, 사용자 감정 공감 등과 같은 태스크를 수행할 수 있는지
- 능력 관점에서 객관적 사실 판단, 논리적 추론, 수학적 추론, 일반 상식과 같은 태스크를 수행가능한지 평가
- 안정성 범위
- 정의하기 모호하지만, 보통 욕설을 사용하는지, 사회적 편향 유무, 유용한 답변을 내리는지를 기준으로 평가
LLM Evaluation Datasets
LLM의 평가 데이터는 평가 목적에 따라 각 데이터를 구축하고 활용
범용 태스크 수행 능력
MMLU(Massive Multitask Language Understanding)
MMLU는 LLM의 범용 태스크 수행 능력을 평가하는 평가용 데이터셋으로, 다양한 평가 목적에 따른 데이터를 수집 및 통합한 데이터 묶음이다. 생물, 정치, 수학, 물리학, 역사, 지리, 해부학 등 총 57개의 태스크로 구성되어 있으며, 아래의 그림처럼 정답 보기를 생성하면 맞추는 객관식 형태로 평가를 진행한다.

일반 상식 능력
HellaSwag
HellaSwag는 사람이 가지고 있는 상식 평가 데이터셋으로, LLM의 일반 상식 보유 능력을 평가한다. 이는 사람이라면 매우 쉽게 해결할 수 있는 태스크로 구성되어 있다. 주어진 문장에 이어질 자연스러운 문장을 선택할 수 있는지 객관식 형태로 평가를 진행한다.

코드 생성 능력
HumanEval
HumanEval은 LLM의 코드 생성 능력을 평가하는 데이터셋으로, 함수명 또는 docstring을 입력하여 LLM이 생성한 코드의 실제 실행 결과물을 용하여 평가를 진행한다. 만약 실행 결과물이 실제값과 일치하면, 정답으로 간주한다. (*docstring: 해당 함수의 수행 과정 및 의도하는 결과물 명시)
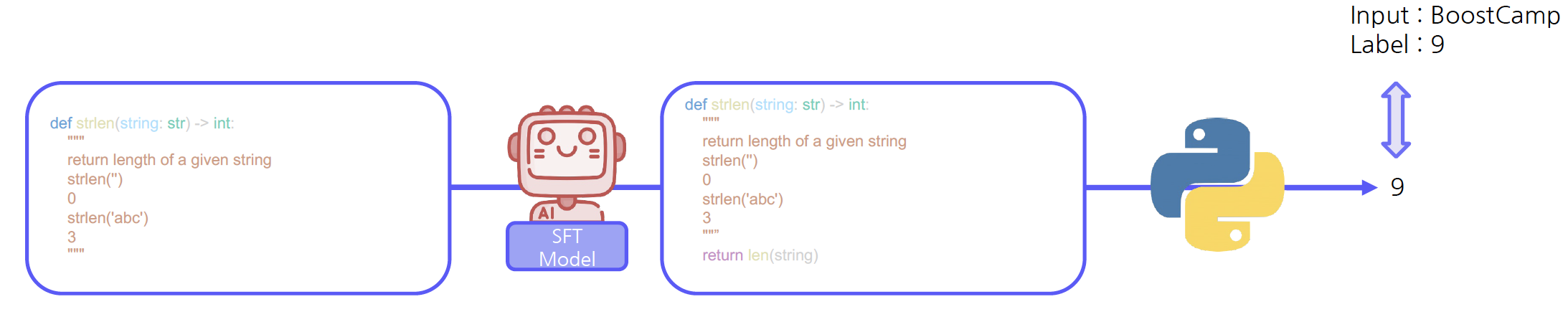
LLM Evaluation Harness
LLM-evaluation-harness는 LLM 평가 방법론 중 하나로, 자동화된 LLM 평가 프레임워크이다. MMLU, HellaSwag, HELM 등 다양한 benchmark 데이터를 이용하여 평가를 할 수 있다.
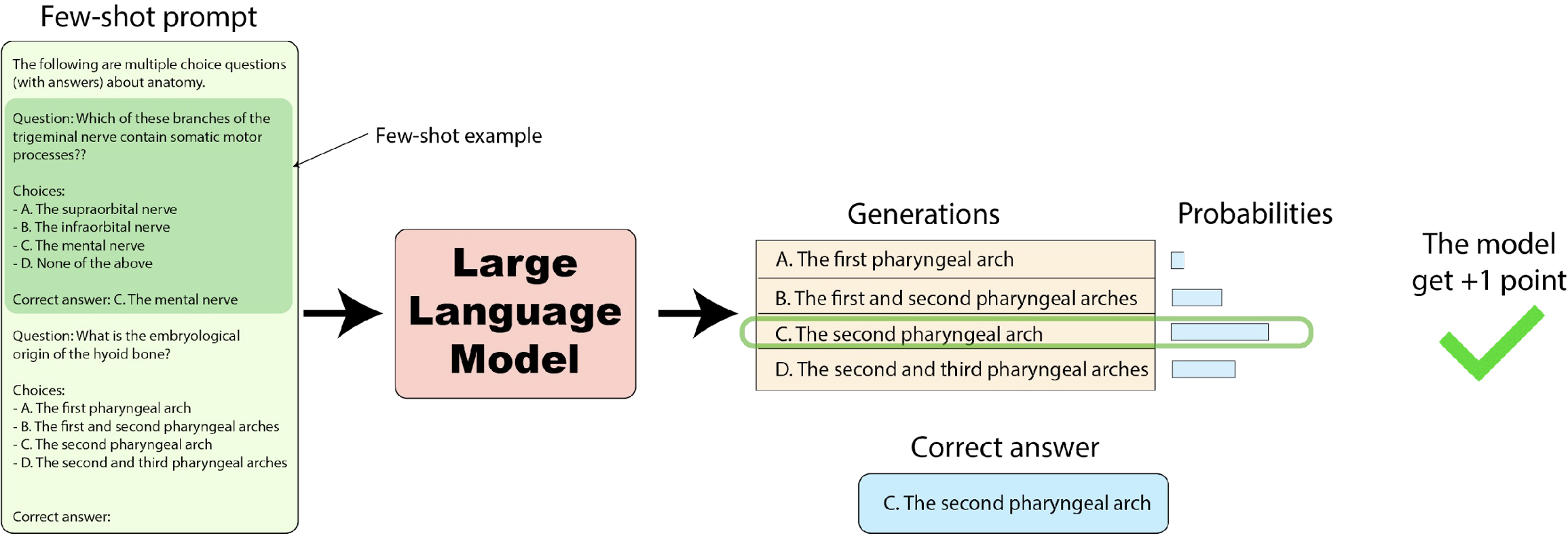
1) K-Shot example과 함께 LLM을 입력하고, 2) 각 보기 문장을 생성할 확률을 계산하여, 3) 확률이 가장 높은 문장을 예측값으로 사용하여 정답 여부를 확인하는 방식으로 평가를 진행한다.
평가 데이터셋을 구성할 때 필요한 요소는 아래와 같다.
- (optional) 고정된 Few-Shot Example
- 강건한 평가를 위해 동일한 예시를 사용
- Instruction
- 해당 태스크에 대한 묘사
- Choices
- 정답 문장을 포함하는 보기 문장 (MMLU/HellaSwag와 동일)
- Correct Answers
- 정답 문장
이러한 방법론은 하나의 모델에 대한 평가가 가능하다. 특정 LLM에서 특정 Task에 대한 지표를 산출할 수 있고, 각 모델 간의 지표를 비교할 수 있다.
G-Eval
LLM-evaluation harness 방법론은 정답 문장을 이용하여 평가를 진행하는데, LLM 활용의 대부분은 정답이 존재하지 않는 태스크이다. 예를 들어 자기소개서 수정, 광고 문구 생성, 어투 변경과 같은 태스크는 창의적 글쓰기 태스크에 해당하는데, 위의 방법론으로는 평가하기가 어렵다. 또한 human evaluation을 통해 정성적인 품질 평가를 해야 하므로, 높은 비용과 긴 시간이 소모되어 다양한 모델에 대한 평가가 어렵다.
이러한 태스크들을 평가하기 위한 방법론이 바로 G-Eval이다. G-Eval은 GPT-4를 이용한 생성문 평가 방법론으로, 창의성 및 다양성이 중요한 태스크에 활용이 가능하다. 또한 정답문(reference)가 존재하지 않아도 평가를 할 수 있다.
요약 태스크를 예시로 평가 방법에 대해서 알아보자.
-
평가 방식에 대한 Instruction을 구성
[Instruction] 다음 문장은 뉴스 기사에 대한 요약문입니다. 당신은 요약문에 대해 하나의 점수로 평가해야 합니다. 반드시 뉴스 원문과 요약문을 자세히 읽고 이해해주세요. 요청 사항에 대해 항상 고려하면서 평가를 진행해주세요.
-
평가 기준 제시
[Evaluation Criteria] 일관성(1점~5점) - 문장 전반의 품질
모든 문장은 잘 구조화되어 있고, 유기적으로 연결되어야 합니다. 요약문은 관련 정보를 단순히 나열하는 것이 아니라 중요 주제에 대해 통일된 정보를 연결하여 문장으로 구성해야 합니다. -
평가 단계 생성: Auto CoT를 통해 모델이 스스로 평가 단계를 정의
=> Auto CoT는 모델 스스로 추론 단계를 구축하는 프롬프트 방식임[Auto CoT] 1. 뉴스 원문을 주의 깊게 읽고 주제와 키 포인트를 탐색합니다.
2. 요약문을 읽고, 원문과 비교합니다. 이때 요약문이 주제와 키 포인트를 잘 포착하고 있는지 확인합니다. 또한 문장이 논리적이며 명확한지 확인합니다.
3. 일관성 점수를 1점에서 5점으로 부여합니다. 평가 기준에 따라 1점이 가장 낮은 점수이며 5점이 가장 높은 점수입니다. -
위의 3가지를 프롬프트로 사용하여 GPT-4에 입력으로 주고 각 요약문에 대한 평가를 진행하여 점수를 생성한다.
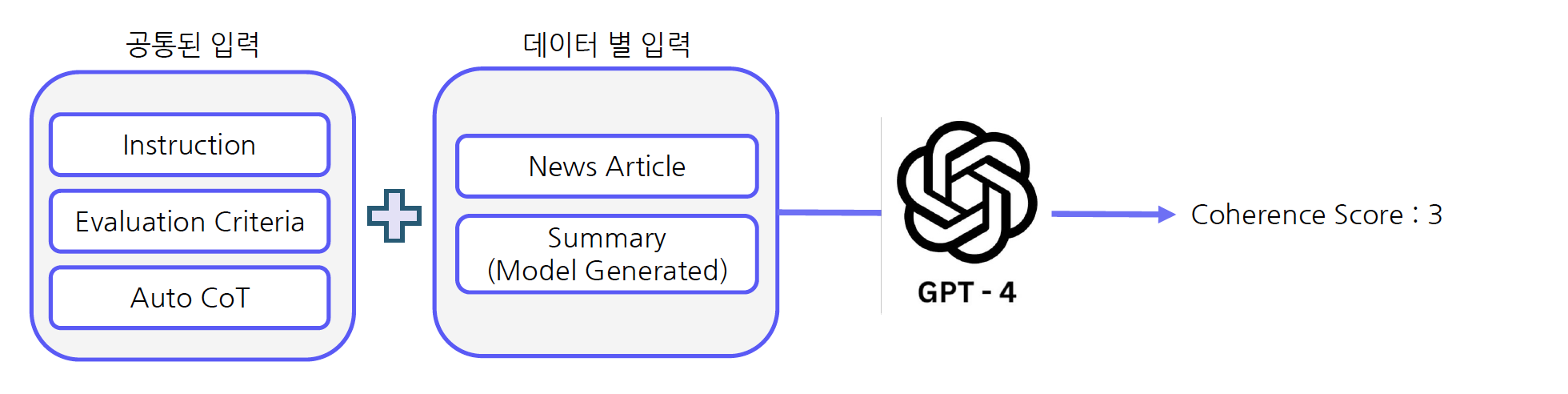
해당 방식은 평가 기준 설정만 수행하면 창의적 글쓰기 능력에 대한 평가가 가능하며, GPT-4 API 비용으로 정성적인 점수를 산출해낼 수 있다.
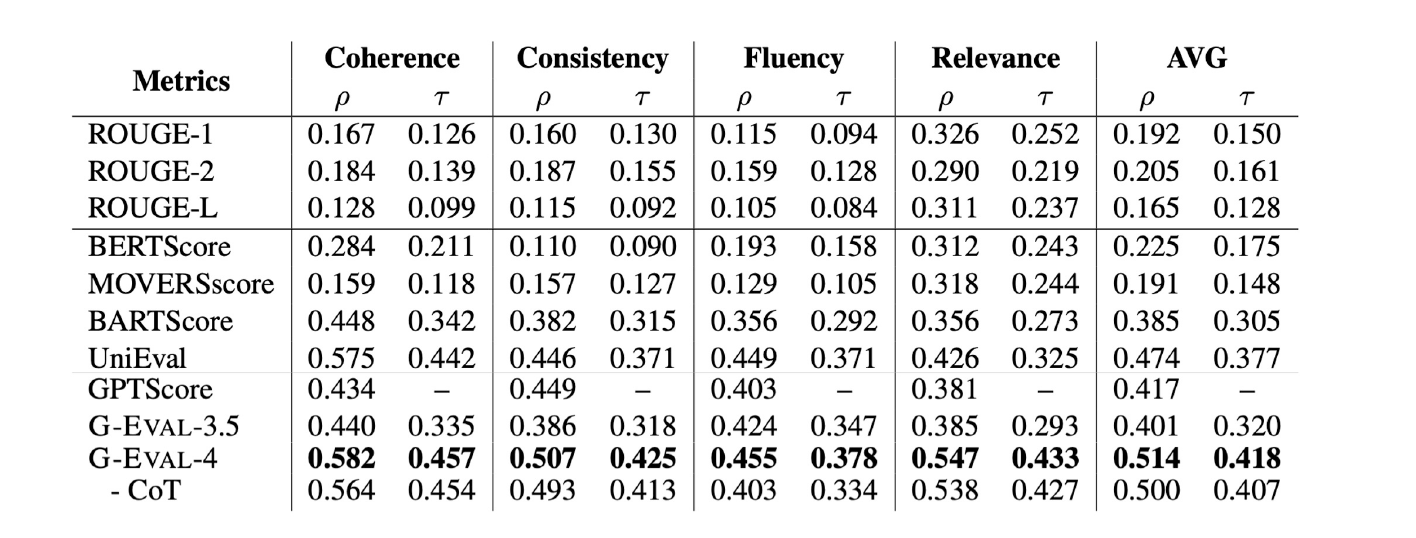
G-Eval을 Human evaluation score와 correlation을 측정했을 때, 기존 평가 방법론 대비 높은 correlation을 보였다. 또한 GPT-4를 사용했을 때, GPT-3.5보다 높은 성능을 기록하는 것을 확인할 수 있다.
주의할 점은 명확한 평가 기준을 정하고, 안정적인 결과물을 산출할 수 있는 적절한 평가 모델 선택, 평가 점수 신뢰도 확보를 위한 일부 데이터의 검수가 필요하다는 것이다.
