개요
GPT API와 Langchain을 활용하여 system instructions으로 역할을 부여하고 memory로 기억장치를 구현하여 효과적으로 과제 첨삭의 역할을 수행하고 결과를 도출해내는 프로그램 개발을 목표로 설정. 이 프로그램은 어떤 타입의 과제든 다양한 시나리오에서 효과적으로 대응.
목적
PT AI의 역할을 다음과 같이 부여하여 사용.
- 문장의 언어적 오류 수정
- 문법, 어법 오류 수정 작성된 과제의 문법 어법적 오류를 수정.
- 문장의 물리적 오류 수정
- 오타, 띄어쓰기 등을 수정
비용
GPT4o-mini 의 100만 토큰당 가격
- 1M input tokens - US$2.50
- 1M output tokens - US$7.50
GPT의 특성상 단순히 API만을 사용해서 수정 결과를 출력하려면 같은 질문, 같은 설정을 포함한 프롬프트를 계속 AI를 사용할 때 마다 입력해야 함. 즉, 동일한 입력을 통해 역할을 부여하는데 지속적으로 토큰이 소모. 이에 따라 아래와 같은 개발이 요구됨
주요 구성 요소
GPT API:
OpenAI에서 제공하는 GPT API를 활용하여 자연어 처리 및 생성 작업을 수행.
역할에 맞는 지침과 메모리를 제공하여 적절한 답변을 생성.
Langchain:
Langchain을 활용하여 시스템 지침 및 메모리를 관리.
GPT API 사용 최적화 및 토큰 소모량 최적화, PDF문서 처리, 데이터 처리등을 담당
요구사항 명세
1. System Instructions 작성
GPT가 원하는 요구를 명확하게 판단하고 role을 부여받아 동작할 수 있도록 system instructions를 작성. Instructions를 어떻게 쓰는지에 따라 GPT의 행동이 변경.
2. Vector History 생성 및 적용
GPT는 이전의 질문과 답변에 대한 기억이 존재하지 않아, instructions의 설정에도 불가하고 오 동작의 가능성이 존재. 이를 또 다른 명령으로 제어할 수 있지만, 다만 이를 기억하기 위해 따로 기억장치를 생성해야 함. 이를 위해 vector History를 생성.
다만, 이 경우 입력이 많아질 수록 토큰 사용량이 증가. 이를 예방하기 위해 vector summary memory로 이전 질문들을 요약하여 기록을 gpt에게 전달.
3. 데이터 추출
일반적으로 GPT API와 Langchain을 활용할 경우 입력은 text가 기본적. 따라서 PDF의 경우 text를 추출하는 과정이 필요. 이를 위해 PDF loader를 사용하여 데이터를 추출.
4. 입력 데이터 분리
입력데이터의 크기가 클 경우 GPT에 모두 한번에 입력이 불가능. 이를 위해 text를 입력 가능한 크기로 분리하고 연속적으로 나누어 입력. 이 과정에서 GPT가 모든 입력 전에 대답을 하지 않도록 제어.
5. 서버 개발
1 ~ 4의 기능을 유지하고 클라이언트에서 들어온 데이터를 처리하여 GPT를 통해 만들어진 결과 데이터를 다시 클라이언트에 반환할 서버의 개발이 필요.
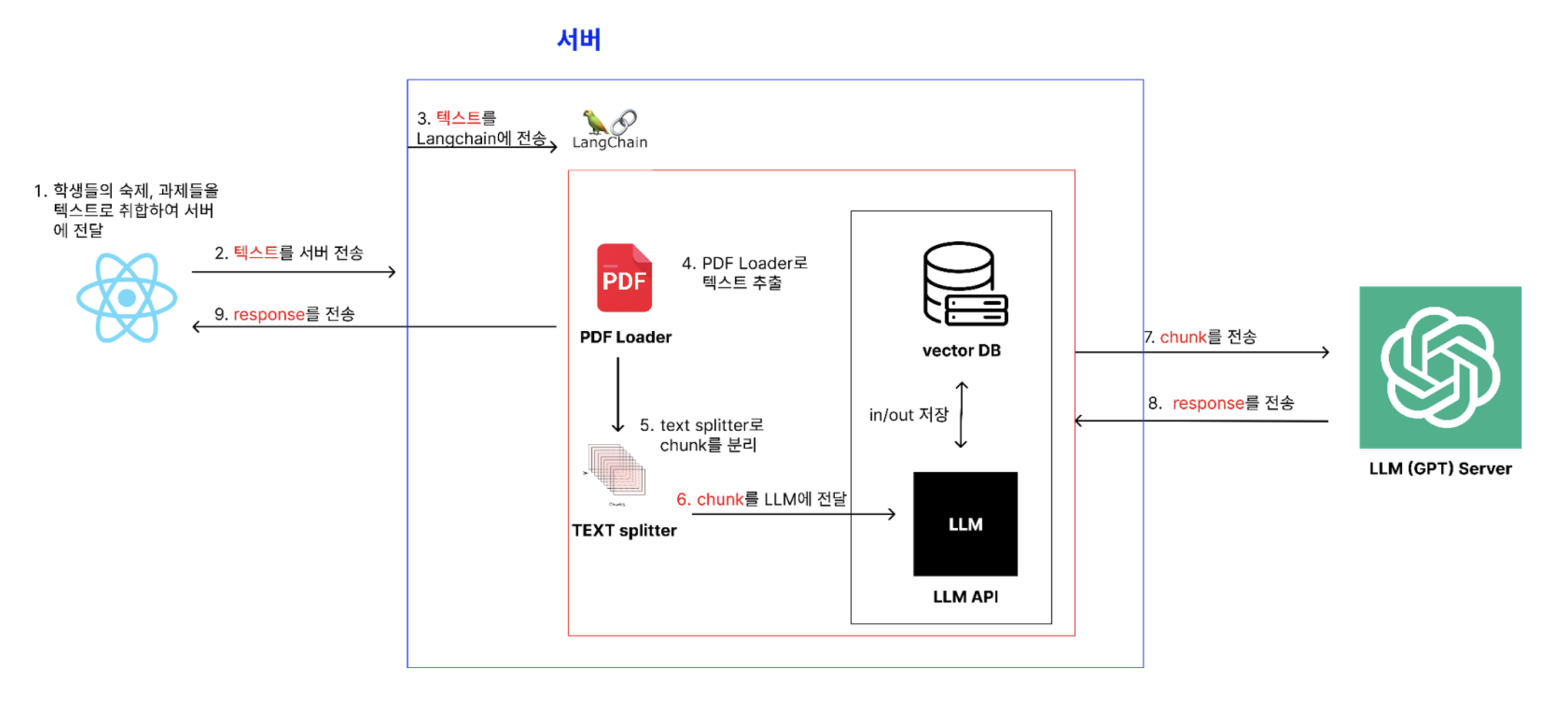
ACTION FLOW
- 학생들의 숙제, 과제들을 텍스트로 취합하여 서버에 전달
React 애플리케이션이 학생들의 숙제와 과제를 텍스트로 변환하여 서버에 전달.- 텍스트를 서버 전송
서버가 텍스트를 수신.- 텍스트를 LangChain에 전송
서버가 수신한 텍스트를 LangChain 모듈에 전송.- PDF Loader로 텍스트 추출
LangChain 내의 PDF Loader가 텍스트를 추출.- Text Splitter로 Chunk를 분리
추출된 텍스트를 Text Splitter를 사용하여 Chunk로 분리.- Chunk를 LLM에 전달
분리된 Chunk를 LLM(대형 언어 모델) API에 전달- Chunk를 전송
서버가 LLM 서버로 Chunk를 전송.- Response를 전송
LLM 서버가 Chunk를 처리하고 응답을 반환.- Response를 서버로 전송
서버가 LLM 서버로부터 응답을 수신하고, 최종적으로 React 애플리케이션에 전달.