다음 내용은 아주대학교 김상훈 교수님 운영체제 강의 및 강의 자료와 Operating Systems: Three Easy Pieces(https://pages.cs.wisc.edu/~remzi/OSTEP/)을 참고하여 작성한 글입니다.
Process Execution Characteristics
-
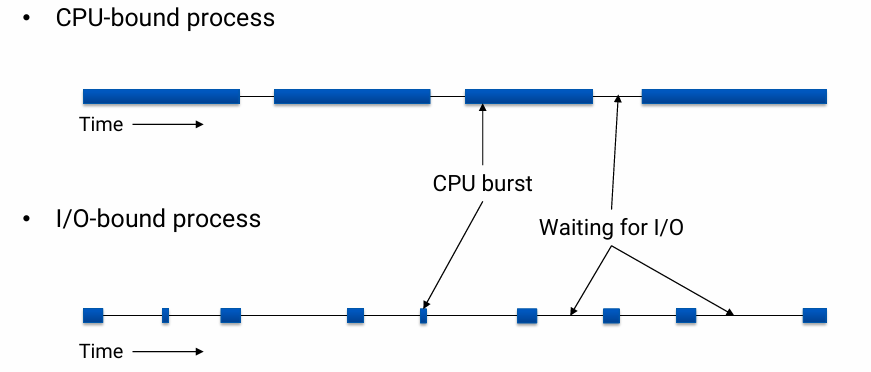
CPU-bound process
- A job that uses the CPU intensively for long periods time
- 오래 걸려도 개의치 않음
-
I/O-bound process
- A job that repeatedly relinquishes the CPU while waiting for input
- interactive 하게 처리되어야 함
Multilevel Queue Scheduling
-
There are different types of jobs in the system thus partition the ready queue into separate queues
-
Assign jobs to the queue according to its characteristics and each queue has its own scheduling algorithm
-
Problem
- would like to optimize turnaround time
but OS doesn't generally know how long a job will run for - would like to minimize response time
but AL like Round Robin reduce response time but are terrible for turnaround time
- would like to optimize turnaround time
Multilevel Feedback Queue
- a number of distinct queues, each assigned a different priority level
- Priority scheduling between queues, round-robin in the same queue
- varies the priority of a job based on its observed behavior
- try to learn about processes as they run, and thus use the history of the job to predict its future behavior
Attempt #1: How to Change Priority
- When a job enters the system, it is placed at the highest priority
- If a job uses up an entire time slice while running, its priority is reduces (i.e., it moves down one queue)
- If a job gives up the CPU before the time slice is up, it stays at the same priority level
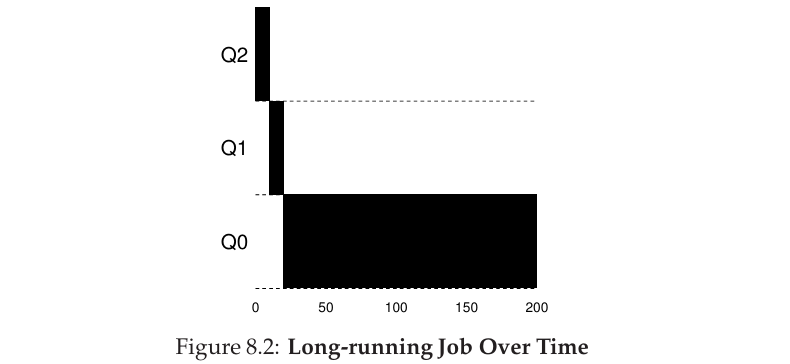
이 job이 short-job인지 long-running job인지 알 수 없다. 따라서 처음에는 short job일 거라 가정하고 제일 priority가 높은 Q2에 배정한다. Q2의 time quantum이 8ms이라고 하자. 8ms이 지나고도 계속 job이 동작 중이면 priority를 감소시키고 Q1로 job을 이동시킨다. Q1의 time quantum을 16ms로 하자. 16ms가 지났음에도 계속 동작 중이면 그보다도 낮은 Q0로 job을 이동시킨다.
Problems With Our Current MLFQ
- Starvation
: if there "too many" interactive jobs in the system, they will combine to consume all CPU time and thus long-running jobs will never receive any CPU time - Game the scheduler
: trick the scheduler into giving you more than your fair share of the resource
(e.g., before the time slice is over, issue an unimportant I/O operation and thus relinquish the CPU; remain in the same queue)
(예시, time slice가 다 끝나기 직전에 중요하지 않은 I/O operation을 실행하여 cpu를 놓음으로써 원래라면 더 낮은 priority queue로 이동해야 할 job이 현재 queue에 머무름) - Change its behavior over time
Attempt #2: The Priority Boost
- After some time period S, move all jobs in the system to the topmost queue
- Processes are guaranteed not to starve + if a CPU job has become interactive, the scheduler treats it properly
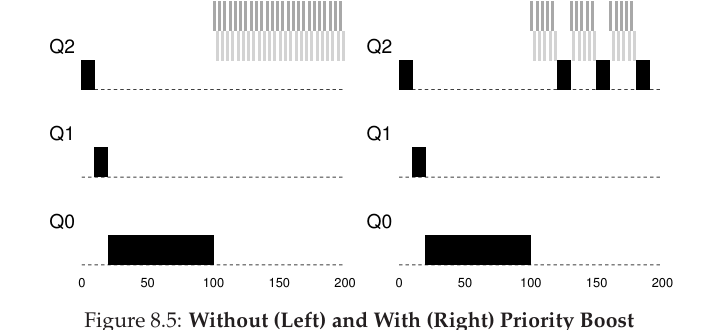
왼쪽은 cpu batch job들에 대해 starvation이 발생하지만, 오른쪽은 cpu batch job들도 priority boost로 인해 interactive job들과 번갈아 가며 scheduling 되는 것을 알 수 있다. 그러나 이 S를 정하는 일 자체가 너무 복잡하고 어렵다는 문제가 있다.
Attempt #3: Better Accounting
- Once a job uses up its time allotment at a given level (regardless of how many times it has given up the CPU), its priority is reduced (i.e., it moves down one queue)
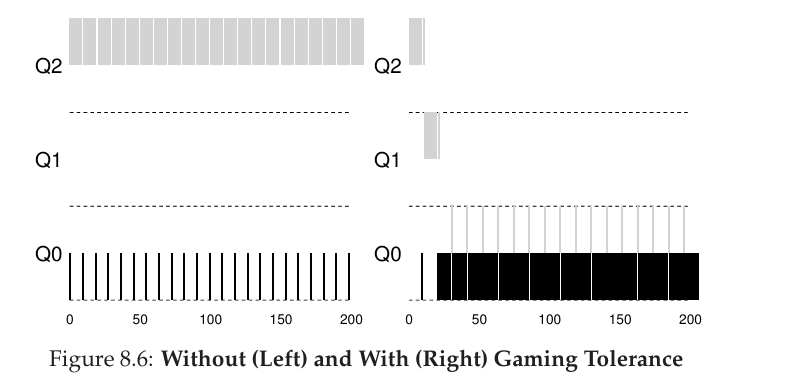
오른쪽 예시는 process의 I/O behavior과는 무관하게, 해당 queue에서 배당된 time slice를 다 쓰면 그보다 낮은 priority의 queue(Q2->Q1->Q0)로 job이 이동하는 것을 나타낸다.
Other issues
No easy answers to these questions...
- How many queues should there be?
- How big should the time slice be per queue?
- How often should priority be boosted in order to avoid stavation and account for chages in behavior
Proportional Share Scheduling
- instead of optimizing for turnaround time or response time, a scheduler might instead try to guarantee that each job obtain a certain percentage for CPU time
- 예를 들어, 앞에서 배운 MLFQ에 PSS를 적용하자면, MLFQ를 priority를 가지고 scheduling 하되 starvatioin 등으로 고려하기 위해, 각 queue마다 일정 비율의 실행 시간을 보장해 주는 방식이다.
Lottery Scheduling
- tickets: represent the share of resource that a process should receive
- The scheduler generates a random number from 1..N (lottery)
- Schedule the process having the number (winning the lottery)
 lottery scheduling은 job이 소유한 ticket의 범위 내에 속한 번호를 무작위로 추출하여 해당 job을 실행한다. lottery scheduling은 확률에 기반한 shceduling 방식이다. scheduling 횟수가 적을 때는 그 확률이 보장되지 않을 수도 있다. 예시를 보면 B는 25% 비율로 schedule 되지만, result를 보면 B가 20% 비율로 schedule 된 것을 알 수 있다. 그러나 scheduling 횟수가 많아질수록 그 비율이 더 잘 보장된다고 한다.
lottery scheduling은 job이 소유한 ticket의 범위 내에 속한 번호를 무작위로 추출하여 해당 job을 실행한다. lottery scheduling은 확률에 기반한 shceduling 방식이다. scheduling 횟수가 적을 때는 그 확률이 보장되지 않을 수도 있다. 예시를 보면 B는 25% 비율로 schedule 되지만, result를 보면 B가 20% 비율로 schedule 된 것을 알 수 있다. 그러나 scheduling 횟수가 많아질수록 그 비율이 더 잘 보장된다고 한다.
Ticket Mechanism
-
ticket currency
: the system automatically converts said currency into the correct global value

user A는 total 1000개의 ticket을 500개씩 A1과 A2에게 나눠주고, user B는 total 10개의 ticket을 B1에게 전부 나눠준 상황이다. 이럴 때 system은 scheduling 시킬 job을 결정하기 위해, global ticket currency를 적용하여 A1, A2, B1의 ticket 수를 변경한다
. -
ticket transfer
: a process temporarily hand off its ticket to another process
user가 server한테 일을 빨리 처리해 달라는 목적으로 자신의 ticket을 server에게 줄 수 있다. server가 모든 일을 마친 후, user가 pass 했던 ticket은 다시 user에게 돌아간다. -
ticker inflation
: a process temporarily raise or lower the number of tickets it owns
comtetitive scenario에서는 안 좋다. 그러나 group의 process들이 서로를 신뢰하고 있는 상황에서는 CPU time이 더 필요한 process가 자신의 ticket value를 boost 시킴으로써 일을 더 효율적으로 처리할 수 있다.
Ticket implemention
lottery scheduling은 구현이 간단하다. user에게는 good random number generator와 process를 track할 data structure와 ticket의 total number만 있으면 된다.

위 예시는 티켓의 총합이 400일 때 Job A (100개 티켓): 0 ~ 99, Job B (50개 티켓): 100 ~ 149, Job C (250개 티켓): 150 ~ 399를 가정한다. 이 상황에서 winner number로 300을 뽑았다고 가정하자. 그런 다음 process list를 traverse 하며 counter 값을 updatate(100->150->400)시킨다. counter 값이 400으로 update 됐을 때 loop를 break 하고 C를 winnner로 정한다.
Why Not Deterministic?
- randomness gets us a simple and approximately correct scheduler, it occasionally will not deliver the exact right proportions, especially over short time scales
- for this reason, Waldspurger invented stride scheduling, a deterministic fair-share scheduler
- Each job in the system has a stride, which is inverse in proportion to the number of tickets it has
- pick the process to run that has the lowest pass value
- every time a process runs, we'll increment a counter for it (called its pass value) by its stride to track its global progress

stride scheduling 이해를 도울 예시 사진이다.
A, B, C는 각각 100, 50, 250개의 ticket을 받았다. stride는 큰 수, 여기서는 10,000을 각각의 ticket 수로 나눈 값이다. stride scheduling에서는 pass 값이 가장 작은 job을 run 시킨다. 각 job의 pass value 초깃값은 0이다. 이 상황에서는 랜덤으로 job을 run 시킨다. 이후 run 시킨 job의 pass value에 stride 값을 더해준다. 다시 pass 값이 가장 작은 job을 골라 run 시킨 후 그 job의 pass 값을 update 시켜준다.
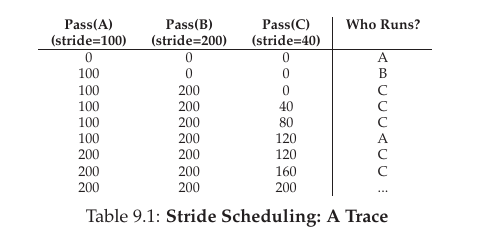
- gets the proportions exactly right at the end of each scheduling cycle
- 예시에서 job A는 100, B는 50, C는 250개의 ticket을 가지고 있었고 scheduling 결과 A는 2번, B는 1번, C번 5번 run 되었다. ticket value의 proportion 비율과 일치하는 것을 알 수 있다.
- problem: A new job entering in the middle of scheduling; what should its pass value be?
- 0 -> monopolize the CPU
