다음 내용은 아주대학교 김상훈 교수님 운영체제 강의 및 강의 자료와 Operating Systems: Three Easy Pieces(https://pages.cs.wisc.edu/~remzi/OSTEP/)을 참고하여 작성한 글입니다.
Competely Fair Scheduler
- aims to spend very little time making scheduling decision
- No default time quantum anymore
- process마다 time quantum을 제공하면 process 개수가 늘어나고 줄어드는 상황이 발생할 때, process들의 reschdule되는 시점까지의 time interval을 fix 할 수 없음.
- Instead, CFS calculates how long a process should run according to the number of runnable processes
Basic Operation
- virtual runtime (vruntime)
- As each process runs, it accumulates vruntime (which increses in proportion with physical time)
- When a scheduling decision occurs, CFS will pick the process with the lowest vruntime to run next
- sched_latency (targeted latency)
- period during which all runnable processes should be scheduled at least once
- typical value: 48ms
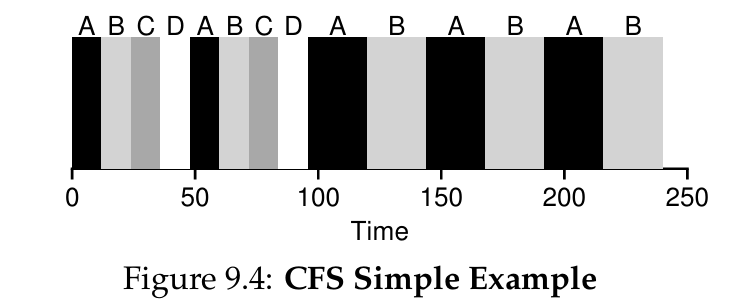
divides this value by the number(n) of processes running on the CPU- if n = 4(A, B, C, D), time slice per process: 12ms
- if n = 2(A, B), time slice per process: 24ms
- Minimum granularity
- floor of the time slice
- typical value: 6ms
- if n = 10, time slice per process: 6ms not 4.8ms
- 위 상황에서는 targeted latency가 지켜지지 않지만 targeted latency는 target으로 하는 값일뿐 꼭 이 값에 맞춰야 한다 이게 아니다
Weighting (Niceness)
- enables controls over process priority using nice level of a process
- nice parameter can be set from -20 to +19, with a default of 0
- positive nice value -> lower priority
- negative nice value -> higher priority
- Calcuation
- CFS maps the nice value of each process to a weight

- accounting for their priority differences
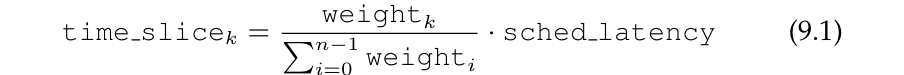
예를 들어, priority가 높은 job A와 priority가 낮은 B가 있다고 하자. 그리고 각각 nice value -5와 0을 받았다고 하면 는 3121, 는 1024가 될 것이다(table 참고). 이 값고 위 수식을 이용하여 각 job의 time slice를 계산하면, A의 time slice는 sched_latency(48ms) = 36ms가 될 것이고 B의 time slice는 sched_latency(48ms) = 12ms가 될 것이다.
vruntime을 계산하는 공식은 아래와 같이 변경될 것이다.
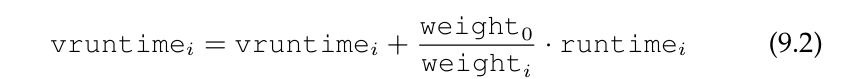
A의 weight가 3121이고 B의 weight가 1024였다. 따라서 A의 vruntime은 실제 runtime의 로 계산될 것이다. CFS는 vruntime이 가장 낮은 process를 골라 실행시킨다는 점을 떠올려 보면, priority가 높은 A가 schedule 될 빈도가 늘어남을 알 수 있다.
- CFS maps the nice value of each process to a weight
Process Selection
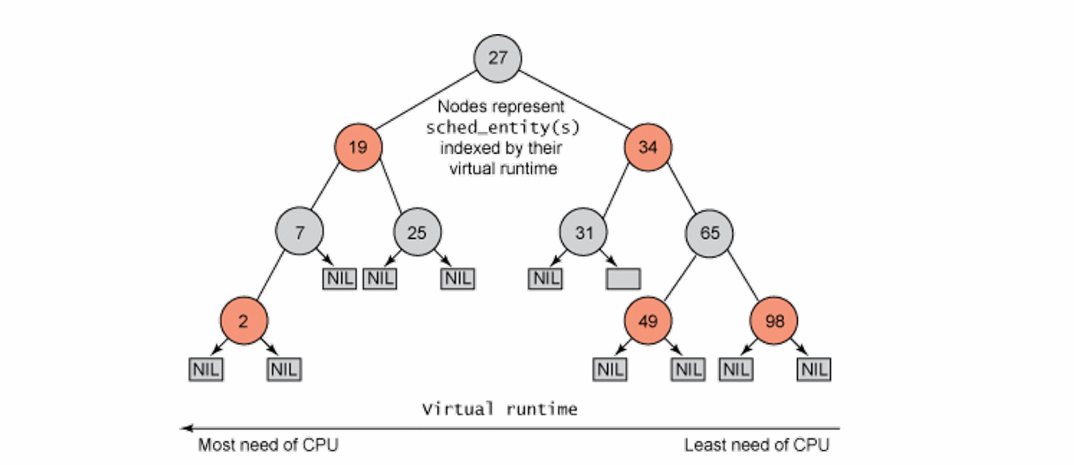
- processes를 list로 관리하자니 process의 수가 방대할 때, searching 과정이 매우 비효율적이다. 그렇다고 그냥 binary tree를 이용하자니, 최악의 경우(skewed) searching 시간이 O(n)이 된다. 그래서 balanced tree가 필요한 것이다.
- CFS indexes tasks using a red-black tree with its vruntime
- 어떠한 경우에도 time complexity가 O(logn)으로 보장된다.
- Schedule the task with the smallest vruntime
Multiple-Processor Scheduling
Multiple-Processor scheduling
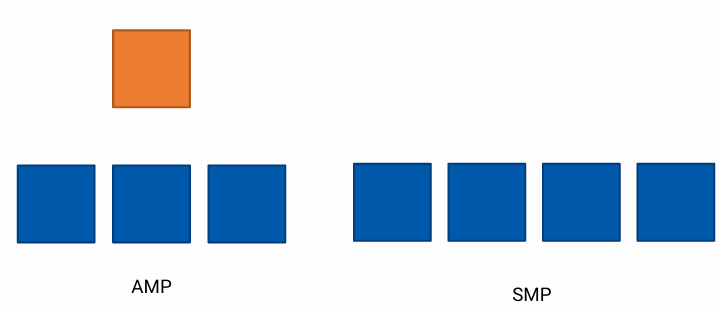
- Asymmetric multiprocesing
- Master node makes decision on load balancing
- Bad Scalability
- master는 task 분배 후 추가 작업을 하지 않으면 slave만 바쁜 상황이 되어 버린다. 반면, 많은 slave node가 동시에 작업을 마치고 master에게 보고할 경우 master가 과부화 상태가 되어 slave가 idle 해질 수 있다.
- Symmetric multiprocesing
- Each processor is self-scheduling
- processor 간 synchronization 문제로 인해 AMP보다 구현이 어렵다.
- 한 processor가 task를 게을리하거나 정지하면, workload가 다른 processor에게 분산되어, 전체 시스템의 성능에 부정적인 영향을 미칠 수 있다.
Load balancing
- Attempts to keep workload evenly distributed
- 공평하게 일을 나눠 가지려고 하지만 어느 정도 tolerance도 존재한다.
- Push migration
- Periodic task checks load on each processor, and if found pushes task from overloaded CPU to other CPUs
- 안 그래도 task가 많은 core가, task를 push할 만한 다른 core도 찾는다? => overhead가 큼
- Pull migration
- Idle processors pull waiting task from busy processors
- 대개 많이 쓴다. idle한 core가 다른 core들의 상황을 살피므로 overhead가 적다.
NUMA and CPU Scheduling
- Uniform Memory Access architecture (UMA)
- Single memory controller is used
- memory access time is balanced or equal
- Non-Unifrom Memory Access architecture (NUMA)
- providing each processor with its own local memory
- memory access time is not equal
- 보통 chip을 여러 개 꽂을 수 있으면 NUMA라고 한다.
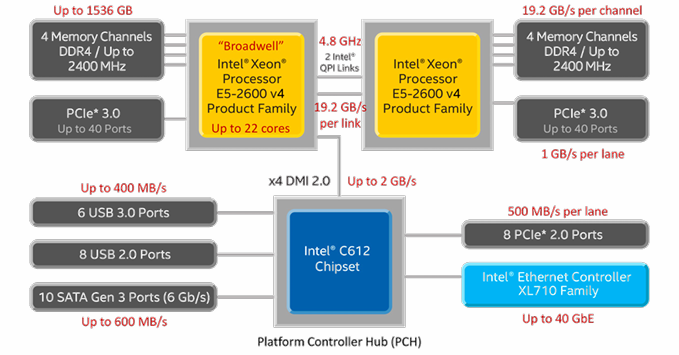 오른쪽 CPU에서 돌아가는 process A가 있었다고 하자. A 입장에서는 A의 local memory(바로 옆에 연결된 메모리)에 접근하는 게 A의 remote memor(왼쪽 CPU와 연결된 memory)에 접근하는 것보다 빠르다. 그러나 오른쪽 CPU가 pull migration을 해서 A가 왼쪽 CPU에서 돌아가게 되면 A의 memory 접근 성능은 급격히 저하될 것이다.
오른쪽 CPU에서 돌아가는 process A가 있었다고 하자. A 입장에서는 A의 local memory(바로 옆에 연결된 메모리)에 접근하는 게 A의 remote memor(왼쪽 CPU와 연결된 memory)에 접근하는 것보다 빠르다. 그러나 오른쪽 CPU가 pull migration을 해서 A가 왼쪽 CPU에서 돌아가게 되면 A의 memory 접근 성능은 급격히 저하될 것이다.
UMA vs NUMA 참고 https://www.geeksforgeeks.org/difference-between-uniform-memory-access-uma-and-non-uniform-memory-access-numa/
Processor Affinity
- Process has affinity for processor on which it is currently running
- 개발자가 내 process는 특정 processor를 선호합니다 선언
- Soft affinity: No guarantees that process will run on same processor
(고려해 달라 이 정도의 느낌) - Hard affinity: Process can specify what processor to use
(나 걔 아니면 안 돼의 느낌)
Multiprocessor Systems Classification
- basic concept
- 참고 https://iosdevlime.tistory.com/entry/iOSCombine-CPU%EC%99%80-%EC%BD%94%EC%96%B4-%EA%B7%B8%EB%A6%AC%EA%B3%A0-%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4%EC%99%80-%EC%8A%A4%EB%A0%88%EB%93%9C%EC%9D%98-%EA%B0%9C%EB%85%90
- CPU: 기억, 연산, 제어 등 컴퓨터의 논리적 사고를 담당
- Core: 각종 연산 작업을 담당하는 CPU의 주요 연산 회로
- 싱글 코어: CPU 1개 + Core 1개
- 듀얼 코어: CPU 1개 + Core 2개
- 멀티 코어: CPU 1개 + Core n개
- Thread: Core가 할 수 있는 최소 단위의 일
-
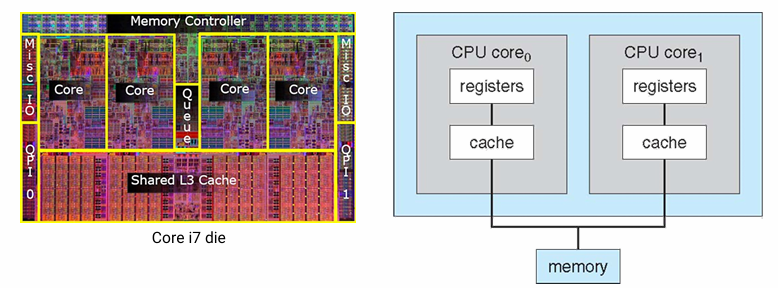
Single-chip multiprocessor (a.k.a. multicore)
- Chip 한 개에 core가 여러 개
- 여러 core가 가까이 위치해 있고, resource를 공유함으로써 시스템의 성능과 효율성을 높일 수 있음
-
Scheduler shoud consider such a core organization to fully utilize the benefit of multicore architecture
-
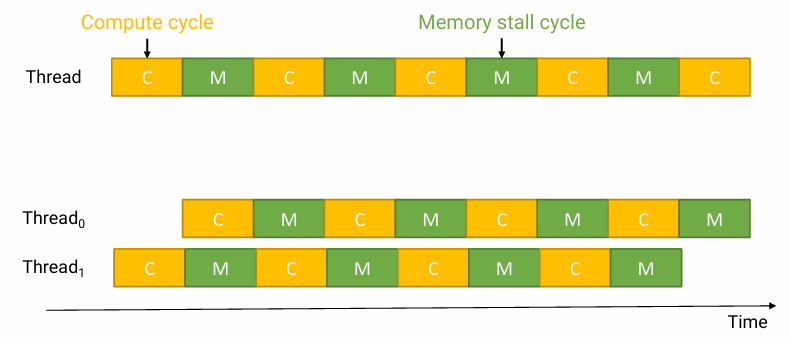
Multiple threads per core
- Takes advantage of memory stall to make progress on another thread while memory retrieve happens
- memory stall: process holds still until a memory becomes available
- cpu가 메모리에서 데이터를 가져오는 동안 발생하는 memory stall을 활용하여 다른 thread에서 작업을 수행할 수 있다는 의미이다.
- Takes advantage of memory stall to make progress on another thread while memory retrieve happens
