08 DLP (1)
Systolic Array
- 특정 연산을 빠르게 수행하도록 설계된 Specialized Accelerator
- FPGAs, ASICs를 사용해서 구현됨
- 명령어를 하나씩 읽고 실행하는 von Neumann과 달리, PE↔PE 사이 register-to-register로 data 전달
- simple, regular design → high concurrency → high performance
- balanced computation and I/O(memory) bandwidth (ld, std, sub 다 골고루 수행하기 위한 목적)
- TPU에 쓰임
pipelining과 다른 점
- pipelining에선 stage 간 dependency가 있지만 PE 간에는 dependency가 X
- systolic array 구조는 non-linear, multi-dimension도 가능함
- PE는 서로 다양한 방향으로 연결 가능함
- pipelining에서 각 stage는 딱 하나의 고정된 연산만 수행하지만, PE는 자신만의 로컬 메모리를 갖고, 하나의 커널 자체를 실행할 수 있음 (pipelining은 {a+b} c 2를 연산 기호 단위로 나눠서 한다고 보면 됨)
연산 예시
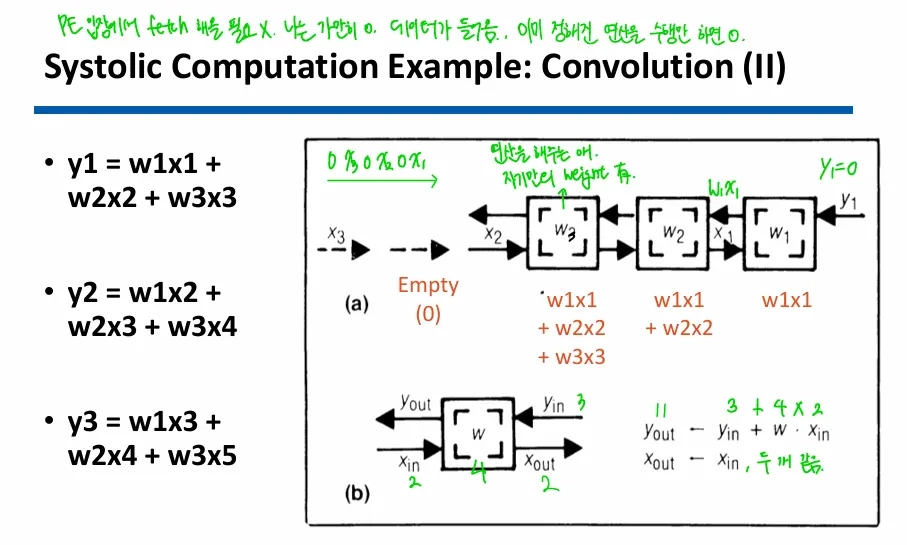
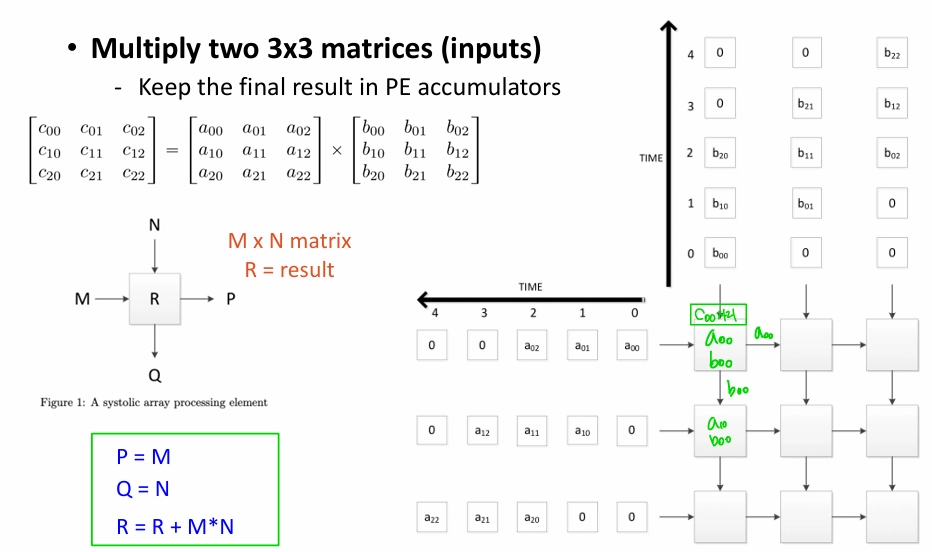
장단점
- instruction fetch, decode 과정이 필요 없음
- 한 번 DRAM에서 로드한 데이터를 PE 내부에서도 사용하고, 이웃 PE에게 전달도 함. → DRAM에서 매번 데이터를 가져오지 않아도 되게 설계. 메모리 대역폭이 적어도 높은 성능을 낼 수 있음.
- not generally applicable
- 코드를 파이프라인화한 pipeline-parallel program (특히 video processing)에서도 사용 가능.
SIMD
Flynn’s Taxonomy
- SISD: scalar processor / add, mul
- SIMD: Array processor, Vector processor
- MISD: systolic array processor (data stream을 대상으로 +, x 여러 연산 수행)
Data parallelism
- 같은 연산을 여러 data에 동시에 적용하는 것 (SIMD나 벡터의 내적)
- Array proc이 vector proc보다 PE가 더 많이 필요하지만 성능 측면에선 좋음
- Very Long Instruction Word (VLIW)라고, word size를 instruction 여러 개로 한 것도 나옴, ILP
Array Processor
- single insturction으로 여러 data를 동시 처리 하되, 시간 상에서 모든 PE는 동일한 명령 실행
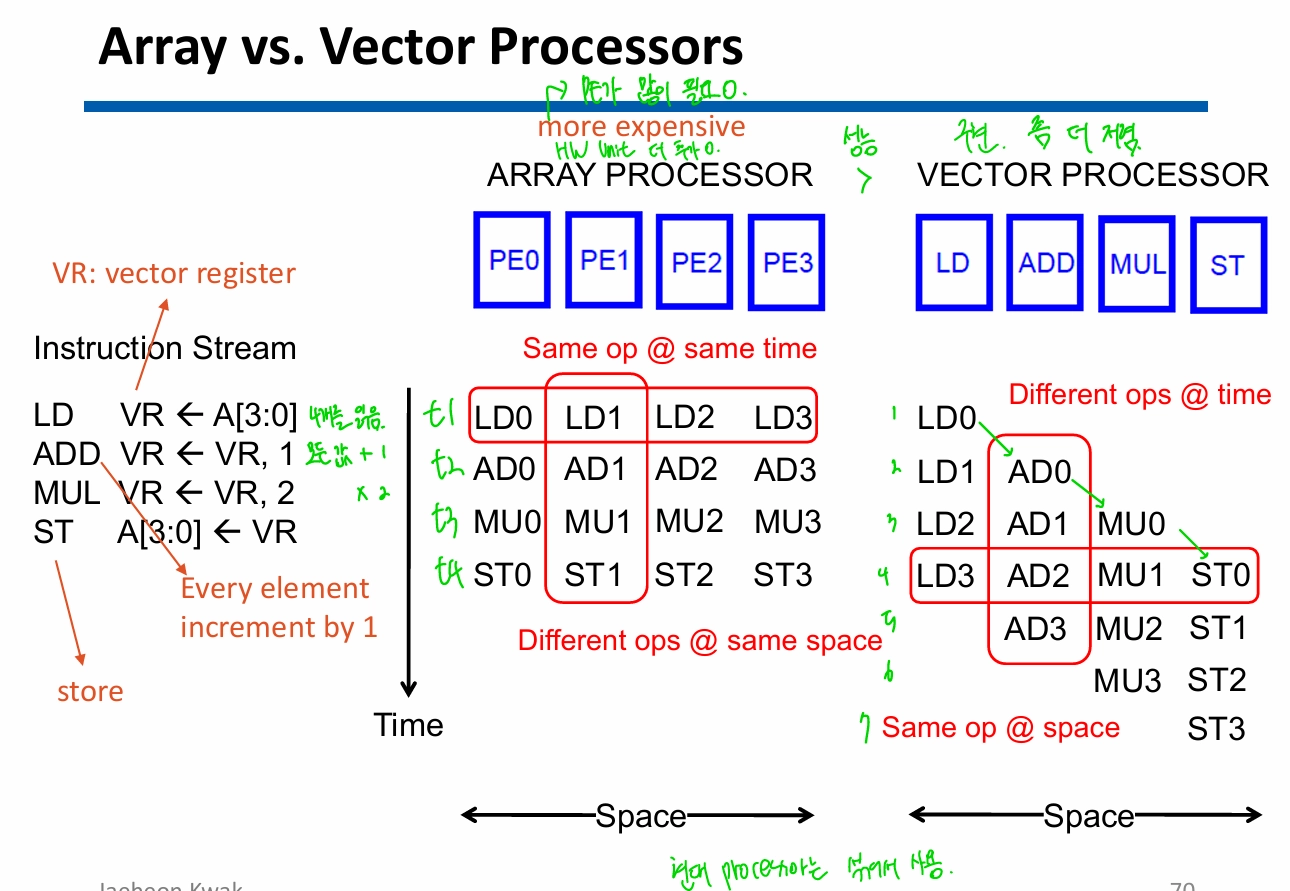
Vector Processor
- 같은 공간 상에서 모든 PE는 동일한 명령 수행
- Basic requirements
- vector register: 여러 값을 저장
- vector length (VLEN): vectors of different lengths, vector 길이
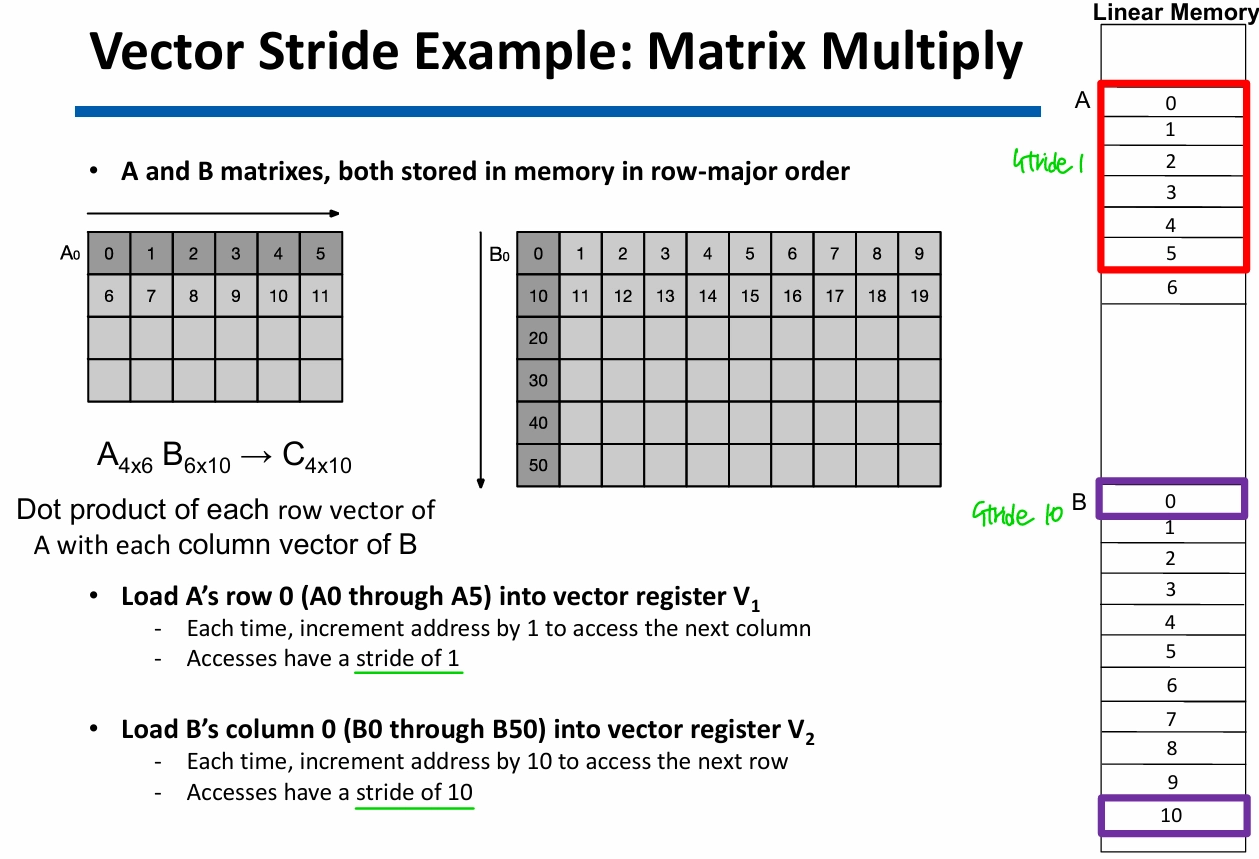
- vector stride register (VSTR): vector를 이루는 element 간의 간격4
- vector mask register (VMASK): element에 operation을 적용시킬 건지 아닌지
- vector 내부 element 간 dependency가 존재 X → 더 깊은 pipelining이 가능 (hazards나 forwarding을 크게 고려 X) → 한 stage를 한 cycle에 처리하는데 그 stage 자체가 더 작아져서 clock frequency도 높아짐 → 이상적으로는 더 나은 performance에 도달할 수 있음
- 각 instruction이 더 많은 computation을 포함하되, fetch나 decode overhead는 줄어듦
- for loop 이용하지 않아도 됨
- 높은 regular memory access pattern (이건 세모)
- vector operation에선 좋지만, 링크드 리스트는 메모리 접근이 불연속적이라 stride로 다 따라갈 수 X
- vector processor에서는 메모리를 한 번에 많이 갖고 오는 게 중요하므로, memory bandwidth가 되게 중요함. 결국 computation과 memory operation 간 balance를 맞추는 게 중요한데 여기서는 memory bandwidth 제약이 큼. data가 memory bank에 적절히 잘 나뉘어 존재해야 함.
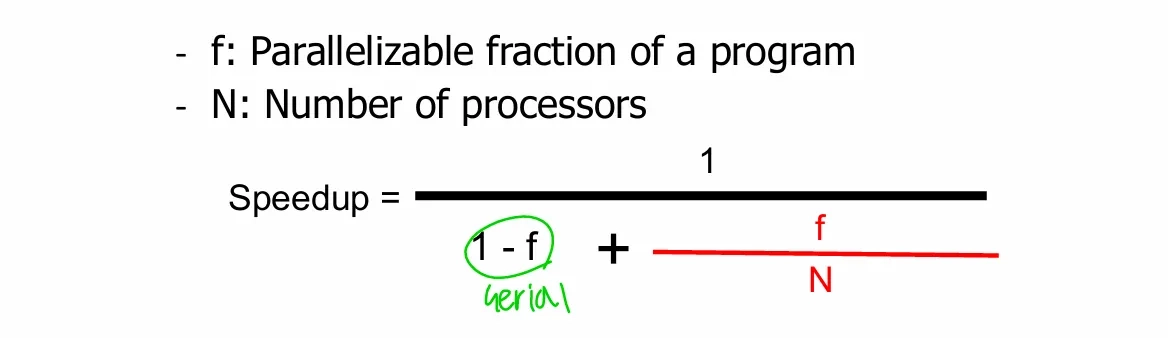
Amdahl’s Law
- serial 부분 때문에 SIMD도 결국 성능 향상에 제약이 있음
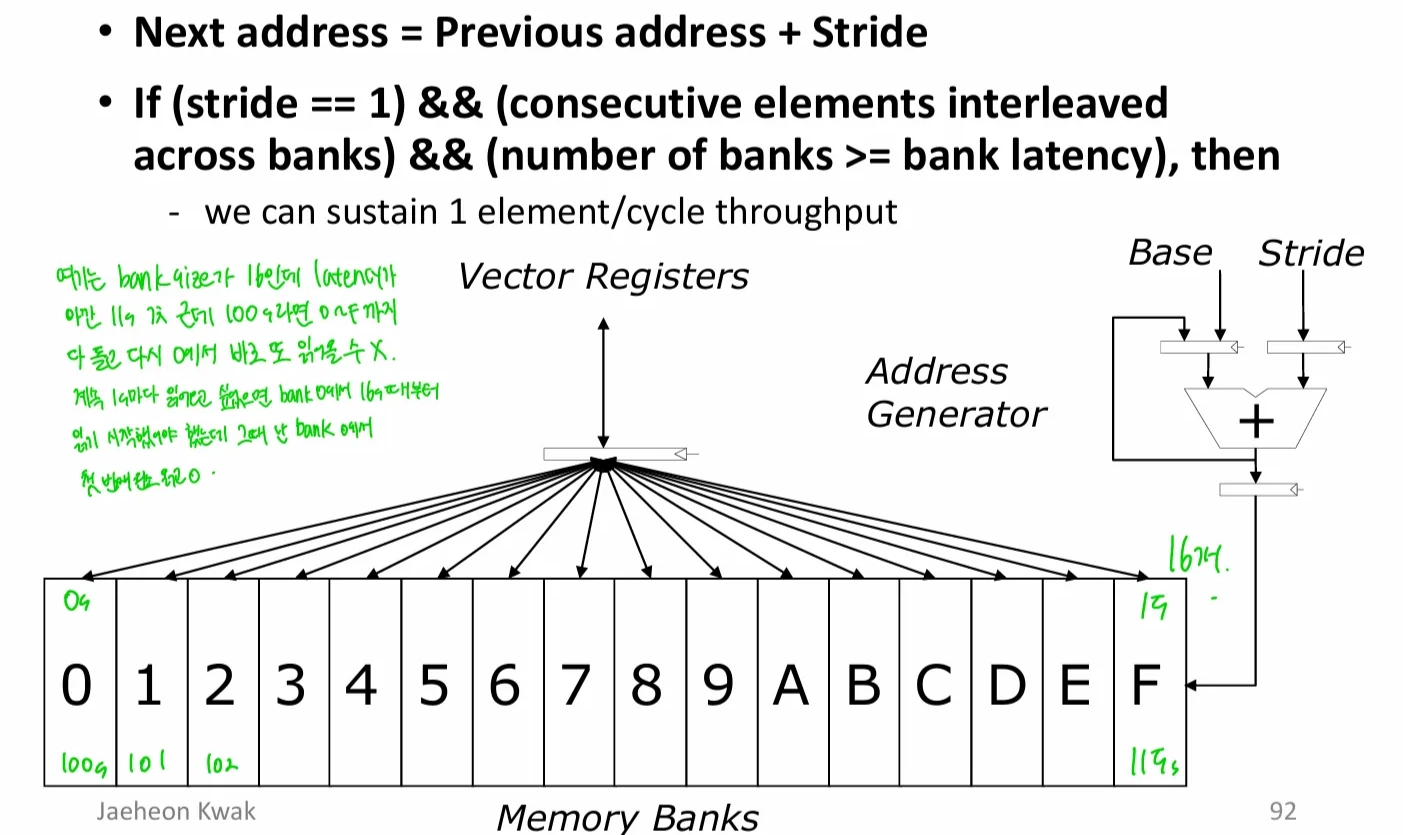
Memory Banking
- stride가 1이고, 접근해야 하는 연속적인 element가 bank에 골고루 저장돼 있고, bank 수가 bank latency보다 크다면, 처음을 제외하고 1 cycle마다 데이터를 받아올 수 있음
- 매 cycle마다 각 bank에 1개씩 요청을 보낼 수 있음. 단, 같은 bank에 두 번 보내면 conflict 발생
- 그래서 만약 latency가 100이라면, 0~F까지 다 도는 데에 15s밖에 안 걸렸으니까 16s 때 0번 bank에서 값을 읽을 수 없음
- vector memory system