08 DLP (2)
Recall
- data elemetns 수 > vector register에 들어가는 수?
- Strip-mining
- 읽어야 할 데이터 길이가 내가 가진 vector reg보다 클 경우, reg 크기만큼 쪼개서 여러 번 읽는 방법
- stride ≠ 1?
- bank가 너무 작거나 stride가 너무 크면 1 cycle만에 읽을 수 X
- stride랑 memory bank 수랑 서로소로 맞추면 모든 bank를 utilize 할 수 있음
- 다만 보통 bank 수는 2^n이라서 저렴한 shift 연산으로 접근 가능하지만, 소수로 하면 비싸고 느린 mod 연산을 써야 함. 그래서 실제론 소수로 하는 데 어려움이 있음
- stride가 1이 아닐 땐 bank 수나 port 수를 그냥 엄청 키우면 됨. 다만 HW cost가 증가함
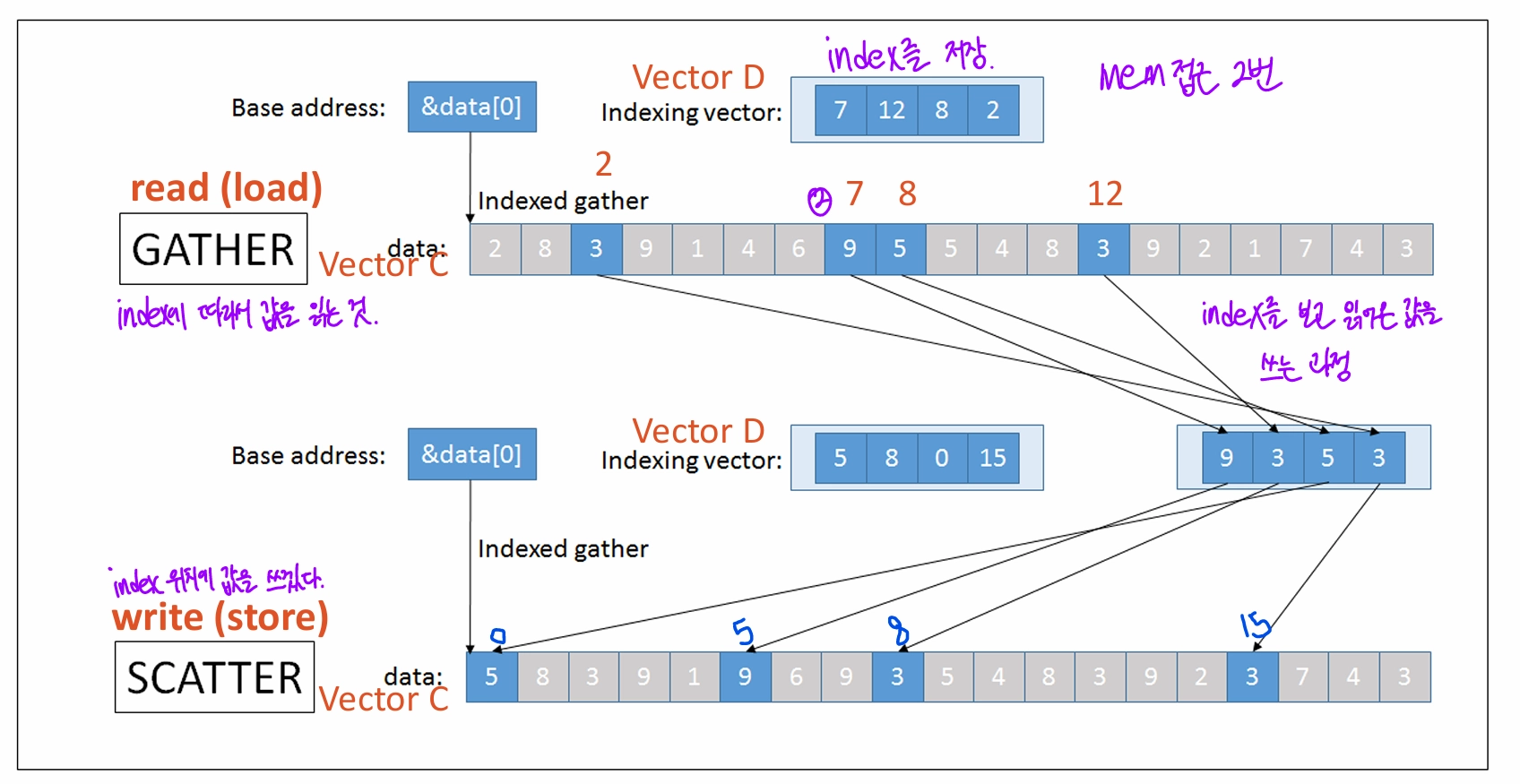
- vector data가 strided fashion으로 저장돼 있지 않으면?
- indirection 이용 (값이 있는 곳의 위치를 따로 저장)
- Gather: index 위치에 있는 값을 읽는 것
- Scatter: index 위치에 값을 쓰는 것
-
if 문이 있다면?
- Masked operation 사용 (VMASK register)
- Simple implementation: 연산은 다 하고 나중에 VMASK 확인해서 값을 실제로 쓸지 말지 결정. 효율은 안 좋으나 간단함
- Density-time implementation: VMASK를 보고 실제로 연산을 할지 안 할지 결정. HW 복잡성 증가

-
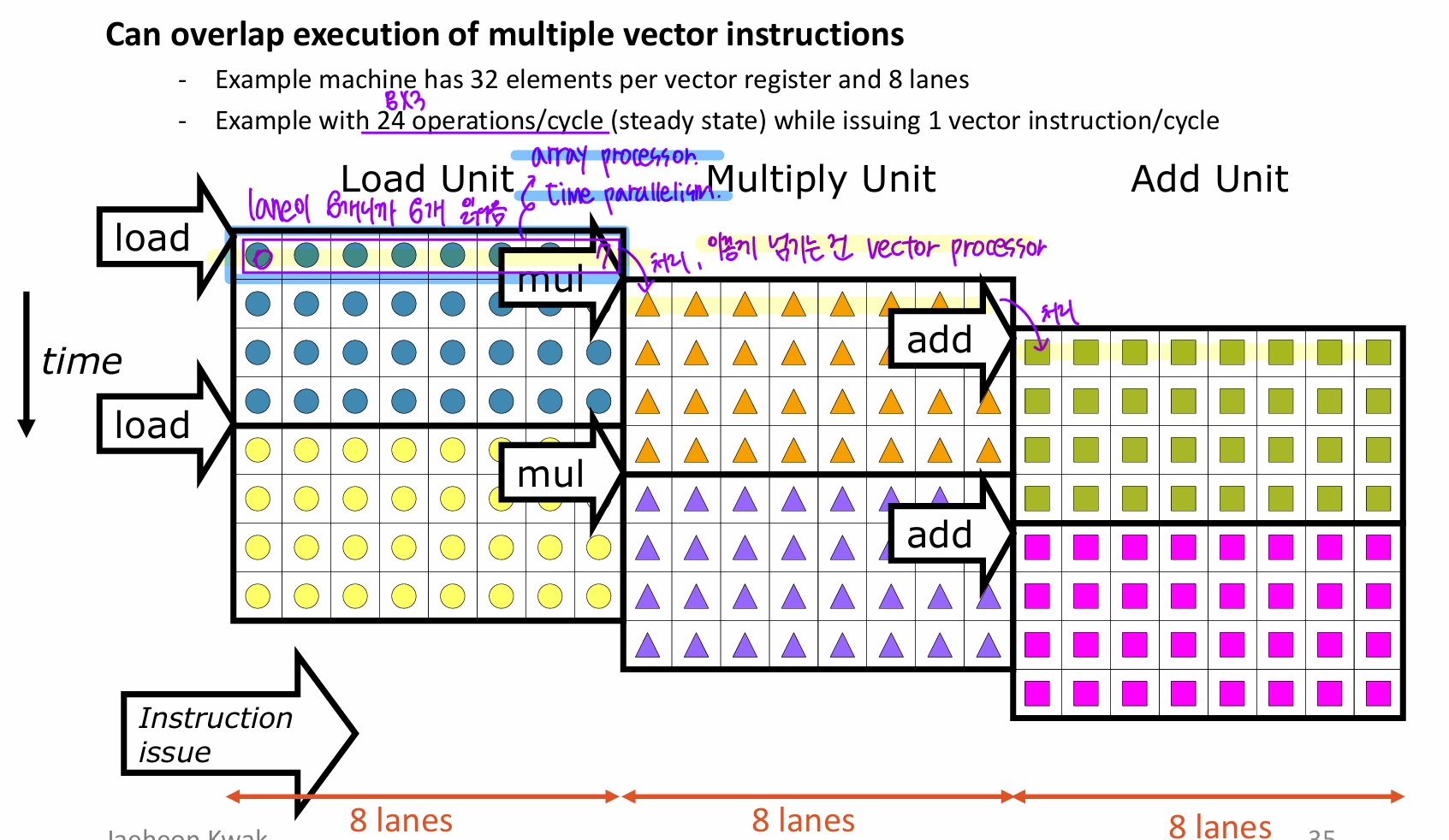
vector porcesso는 lane(PE) 수가 많아지면 spatial parallelism뿐만 아니라 time parallelism도 생김
- lane은 functional unit 여러 개를 묶은 단위.
- lane이 PE이고, PE 안에 여러 functional unit (load, mul, add 등이 존재)
- PE가 8개라서 값을 8개씩 읽어오고 chaining을 통해 다른 unit으로 넘김
SIMD Operations in Modern ISAs
-
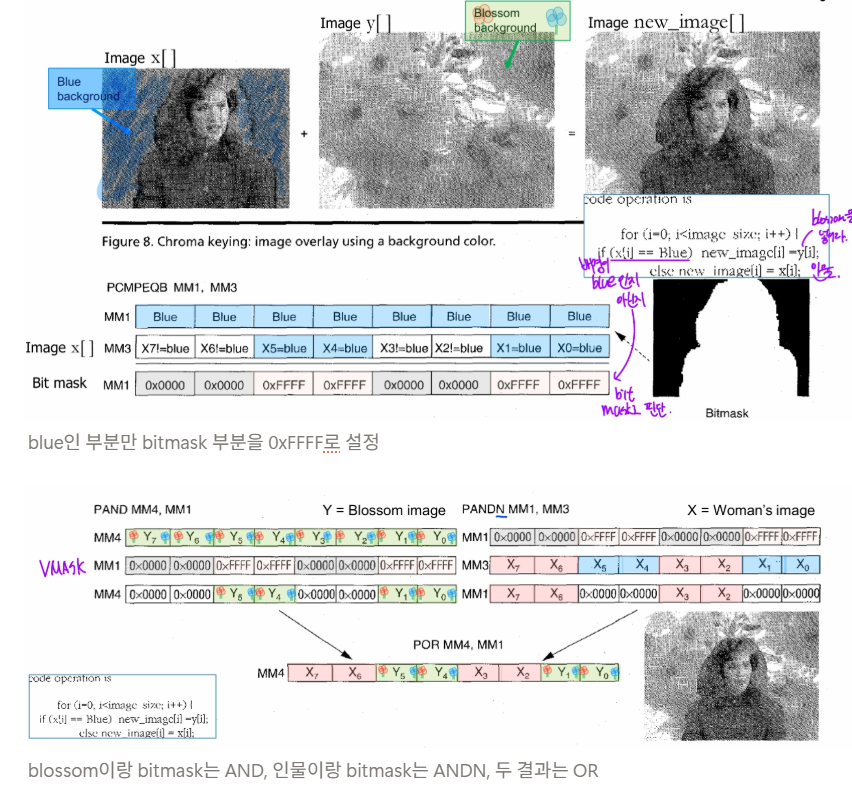
Intel Pentium MMX
- 32bit register를 8bit 씩 쪼개서 연산 4개를 동시에 (SIMD) 가능

- Image Overlaying
- 32bit register를 8bit 씩 쪼개서 연산 4개를 동시에 (SIMD) 가능