You Only Look Once: Unified, Real-Time Object Detection
https://arxiv.org/pdf/1506.02640
https://pjreddie.com/darknet/yolo/
Abstract
이전의 obejct detection 연구들은 classifier를 변형하거나 활용하여 detection 작업을 수행했다. 그러나 논문의 저자들은 object detection을 regression problem으로 보고 객체의 위치를 나타내는 bounding box와 class probablities(그 객체가 어떤 클래스에 속하는지를 나타내는 확률)을 예측하는 방식으로 object detection 문제에 접근한다. 또 하나의 중요 특징은 모든 detection pipeline이 single network라는 것이다.
즉 YOLO는 single neural network를 활용하여 전체 이미지에 대한 one evaluation만으로 bounding boxes와 class probabilities를 예측하는 방식을 사용한다.
1. Introduction
R-CNN과 같이 region proposal을 사용하는 approach는 classification을 하고 post-processing과정이 필요하다. 이러한 복잡한 pipeline은 매우 느리고 최적화하기 어려운데 그 이유는 각각의 component가 만드시 별도로 훈련되어야 하기 때문이다.
YOLO의 저자들은 object detection을 single regression problem으로 본다. 즉 single convolutional network가 multiple bounding boxes와 이 boxes들에 대한 class probabilities를 동시에 예측한다. 이 unified model은 다음과 같은 장점을 갖는다.
- YOLO is extremely fast
- YOLO reasons globally about the image when making predictions
(entire image를 보므로 class 예측에 있어 contextual information을 얻을 수 있음) - YOLO learns generalizable representations of objects
(new domain이나 unexpected input에 대해서도 잘 동작한다는 의미)
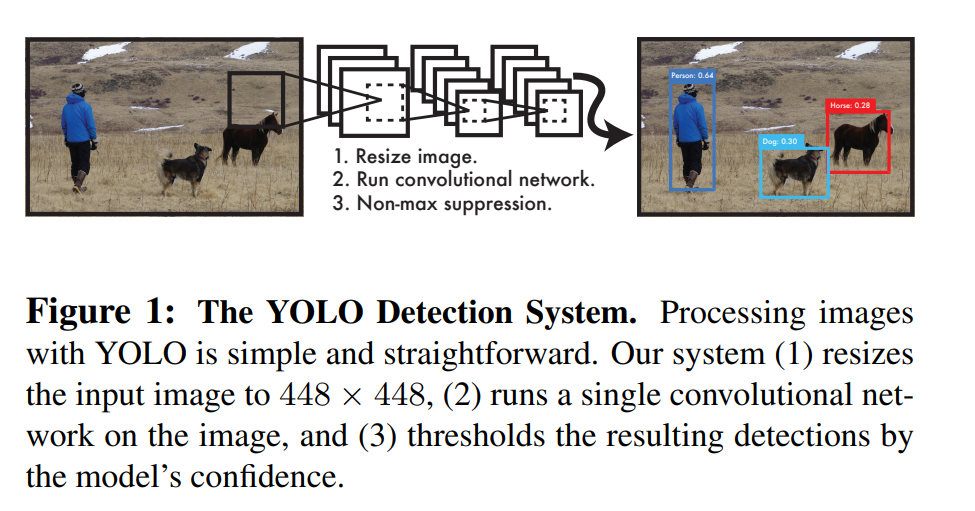
2. Unified Detection
앞서 계속 언급했듯 저자들은 object detection의 분리되어 있던 components들을 하나의 neural network로 unify하였다. 이 system의 detection 과정 중 예측되는 값들은 아래와 같다.
먼저 input image를 S X S grid로 나눈 다음, 각 grid cell은 B개의 bounding box(줄여서 bbox라고 하겠다.)와 confidence score를 계산한다. 이 confidence score는 box가 객체를 포함하고 있는지, 또 얼마나 정확하게 포함하고 있는지의 정도를 반영한다. 그 식은 다음과 같다.
참고로 각 bounding box는 5개의 predictions: 로 구성돼 있다.
- : grid cell을 기준으로 bbox의 중심 좌표 위치
- : bbox의 너비와 높이(전체 image의 W, H에 대해 normalize됨)
- : confidence score
각 grid cell은 $C$, conditional class probabilities를 계산한다. 이 값은 grid cell이 object를 포함하고 있을 때만 계산되는 값이다. box의 개수와는 무관하게 grid cell 1개당 1개의 class probabilities set을 계산한다. 그 식은 다음과 같다.
Test time 때는 각 box에 대해 conditional class probabilites와 confidence score를 곱한다. 이 class-specific confidence score는 특정 class가 box에서 나타날 확률과 얼마나 box가 object를 fit하게 예측하는지의 정도를 나타낸다.
잠깐 용어 정리를 하고 넘어가자.
confidence score: bbox에 물체가 있을 확률과 그 bbox가 Ground Truth와 일치하는 정도인 IoU의 곱.
conditional class probabilities: grid cell이 object를 포함하고 있을 때 계산되는 특정 클래스에 대한 확률 집합
class-specific confidence score: 특정 클래스에 속하는 물체가 해당 bbox 내에 있을 확률과 그 bbox의 IoU의 곱.
논문에서는 PASCAL VOC dataset을 사용하여 YOLO를 평가할 때, 값을 사용하였다. 즉 이미지를 7X7, 49개의 grid cell로 나누고, 1개의 grid cell당 2개의 bbox를 예측했다는 것이다. 또 PASCAL VOC dataset에는 20개의 labelled class가 있기 때문에 는 20개의 class에 대한 possibilities 값을 포함한다.
최종적으로 1개의 셀마다 2개의 bbox(10개의 predictions)와 1개의 값을 가지므로 final prediction은 7 X 7 X 30 tensor가 된다.
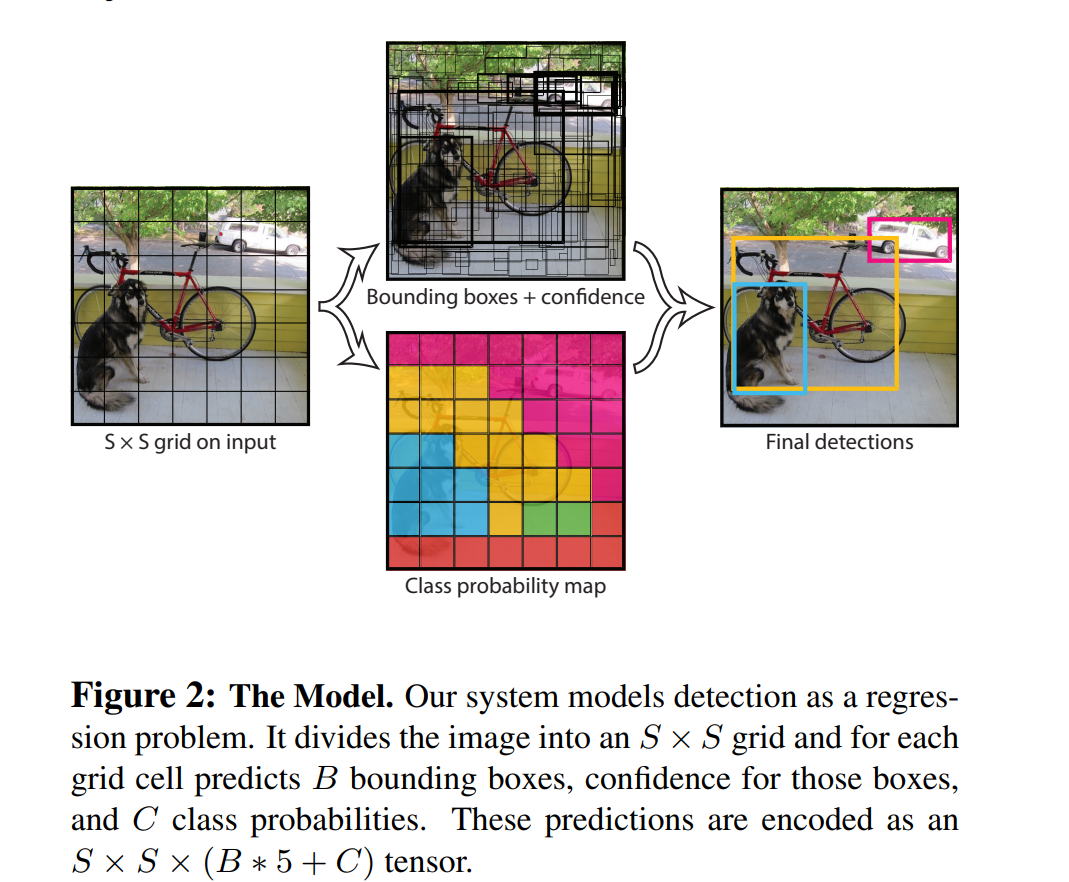
2.1. Network Design

YOLO의 network architecture는 GoogLeNet model에 영감을 받아 24개의 convolutional layer와 2개의 fully connected layer로 구성되었다. 다만 GoogLeNet의 inception module 대신 3 X 3 convolutional layer 뒤에 1 X 1 reduction layer이 추가됐다.
1 X 1reduction layer를 사용하는 이유는 공간상의 패턴을 잡을 수는 없지만 깊이 차원에 따라 놓인 패턴을 인식할 수 있음과 동시에, 여러 필터를 연속적으로 쓰면 파라미터 수가 급증하게 되는데, 중간에 1 X 1 layer를 놓으면 그 파라미터 수를 줄일 수 있는 bottlenect 구조가 형성될 수 있다고 생각했다.
2.2. Training
저자들은 처음 20개의 convolutional layer를 1000개의 competition dataset(224 X 224)을 보유한 ImageNet을 이용해 pretrain시켰다. 그런 다음 detection을 수행하기 위해 4개의 convolutional layer와 2개의 fully connected layer를 추가한다. 또 detection 과정에서는 종종 fine-grained visual information을 필요로 한다. fine-grained 정보가 필요하다는 것은, 이미지에서 물체의 세부적인 패턴, 질감, 색상, 모양 등의 미세한 차이까지 구별해야 한다는 것을 의미한다. 예를 들어, 고양이와 호랑이를 구별하거나, 같은 종류의 새라도 서로 다른 종을 구분하는 작업이 이에 해당된다. 따라서 저자들은 더 많은 픽셀을 확보함으로써 세밀한 정보를 더 잘 보존하고 탐지하기 위해 이미지의 resolution을 448 X 448로 키웠다.
YOLO의 마지막 layer는 class probabilities와 bounding box 좌표를 예측한다. 앞에서 언급했듯, bbox의 width와 height는 전체 이미지의 width와 height에 대해 normalize 되어 0~1 값을 갖고, x와 y 좌표 또한 특정 grid cell에 대한 offset이므로 0~1의 값을 갖는다.
또한 final layer에서는 linear activation을 쓰지만 다른 모든 layer에서는 leaky rectified linear activation(if x > 0: x, otherwise: 0.1x)을 사용한다.
YOLO에서는 sum-squared error를 쓰는데, 이는 AP를 최대화하려는 저자들의 의도에는 잘 부합하지 않는다. SSE 방식은 다음과 같은 문제가 있다.
- Localization Error와 Classification Error의 가중치 문제
이 방식은 localization error와 classification error를 동일한 중요도로 취급하지만, 이 방식이 항상 이상적이진 않다. 때로는 위치를 조금 틀리게 예측하더라도 분류가 정확하다면 localization error가 큰 문제가 되지 않을 것이다. 반대로 위치는 정확하지만 분류가 틀렸다면 classification error의 문제가 부각될 것이다. - 물체가 없는 grid cell들의 영향이 초래한 학습 방해
image cell에는 아무런 객체를 포함하지 않는 cell이 있을 수 있다. sum-squared error 방식은 이러한 cell들의 confidence score를 0으로 만들어 종종 객체를 포함하고 있는 cell의 gradient보다 더 큰 영향력을 끼친다. 이는 model의 불안정성을 초래하고, 모델이 충분히 학습할 수 없게 만든다.
저자들은 이를 완화하기 위해 bbox의 좌표를 잘못 예측했을 때의 loss를 증가시키고, object를 포함하지 않은 box의 confidence predictions에 대한 loss를 감소시켰다. 이를 실현하기 위해 로, 로 설정하였다
- large box와 small box의 weights error 문제
large bbox에서는 약간의 오류가 있어도 실제로 물체 위치가 크게 달라지지 않을 수 있지만, small bbox에서는 작은 오류도 물체 위치가 크게 달라질 수 있다. 그러나 SSE는 large bbox에서 위치가 조금 틀리는 것과, small bbox에서 위치가 조금 틀리는 것을 동일하게 다룬다.
저자들은 이를 부분적으로나마 완화하기 위해 bbox의 width와 height 값을 직접 사용하는 대신 bbox의 width와 height에 square root 값을 씌운 값을 사용했다.
또 YOLO는 grid cell 당 여러 개의 bbox를 사용하지만, 실제 training time에서는 각 object에 대한 detection을 책임 지는 하나의 bounding box predictor를 선택한다. 이 bbox는 ground truth와 가장 높은 IOU 값을 갖는 bbox이다. 저자들은 이 bbox predictor를 object를 detect 하는 데에 있어 'responsible'하다고 표현한다.
마지막으로 YOLO의 loss function에 대해 살펴보자.
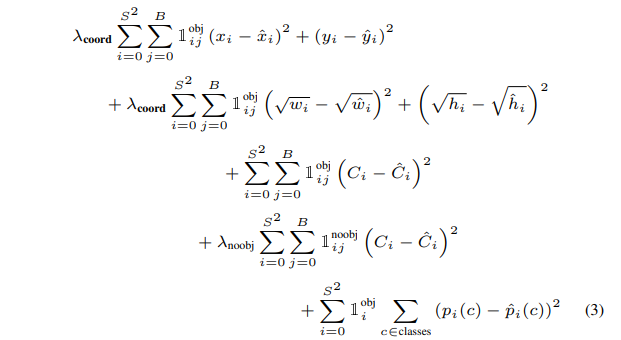
는 object가 cell i에 나타나는지를 의미하고 는 cell i의 j번째 bbox가 responsible함을 나타낸다. 주목할 점은 loss function은 객체가 해당 그리드 셀에 있을 때만 classification error에 대해 페널티를 부과한다는 것이다. 따라서 물체가 없는 셀은 classfication error에 대해 페널티를 받지 않는다. 앞서 논의했던, 물체가 없는 cell들이 학습 과정에서 불필요한 영향을 미치지 않도록 하기 위함이라고 생각해도 무방할 것 같다. 또한 주목할 점은 responsible bbox일 때만 bounding box coordinate error에 대해 페널티를 부과한다는 것이다. 실제 물체에 대해 가장 잘 감지한 bbox에만 좌표 오류에 대해 학습하도록 하여, 모델의 학습을 더 효율적으로 만드는 구조라고 생각해도 무방할 것 같다.
loss function의 첫 줄부터 살펴보면 각각 다음을 의미한다.
(1): 그리드에 있는 객체의 바운딩 박스 중 x, y 좌표의 오차
(2): 그리드에 있는 객체의 바운딩 박스 중 w, h 좌표의 오차
(3): 객체가 있는 경우에 대한 신뢰도 오차
(4): 객체가 없는 경우에 대한 신뢰도 오차
(5): 클래스별 확률값 오차
2.3. Inference
YOLO의 Inference 과정은 훈련할 때와 마찬가지로, 테스트 이미지에 대한 detection를 예측하는 데에는 one network evaluation만을 필요로 한다. 또한 몇몇 큰 물체나 여러 개의 cell에 걸쳐 있는 object는 Nom-maximal suppresion으로 해결할 수 있다고 한다.
2.4. Limitations of YOLO
- strong spatial constraint
YOLO는 오직 하나의 cell당 2개의 box와 1개의 class만을 예측한다. 이러한 spatial constraint limit로 인해 YOLO는 작은 object나 새떼가 있는 image에 대해서는 detection을 잘 수행하지 못한다. - struggles to generalize to objects in new or unusual aspect ratios or configurations
bbox의 형태가 training data를 통해서만 학습되므로 새로운 형태의 경우 정확히 예측하지 못한다. - loss function limit
YOLO의 손실 함수가 small bbox와 large bbox의 예측 오류를 동일하게 처리한다.
3. Comparision to Other Detection Systems
Defromable parts models
- use a disjoint pipeline (static feature 추출하고, region 분류하고, bbox 예측하는 과정)
- YOLO는 이 disjoint parts를 single convolutional neural network로 대체함
R-CNN
- complex pipeline must be precisely tuned independently and it is very slow
- selective search를 이용하여 이미지당 2000개의 bbox 생성
- YOLO는 grid cell마다 spatial constraints를 적용하기 때문에 같은 object에 대한 multiple detection 완화 가능
Fast and Faster R-CNN
- fast by sharing computation and using neural network + bad real time performance
- YOLO는 기존의 pipeline을 제거하고, 처음부터 빠른 처리를 염두에 두고 설계됨
Deep MultiBox
- MultiBox는 general object detection에 있어 훌륭한 성능을 보이지 못함
- large detection pipeline의 일부임, image patch classification을 필요로 함
- YOLO는 COMPLETE detection system임
4. Experiments
4.1. Comparison to Other Real-Time Systems
PASCAL VOC dataset에 대한 YOLO와 Real-Time Detetectors간의 비교이다. DPM을 제외한 다른 비교군은 real-time 성능에 있어 저조하지만 상대적인 mAP나 speed를 비교하고자 포함했다고 한다.
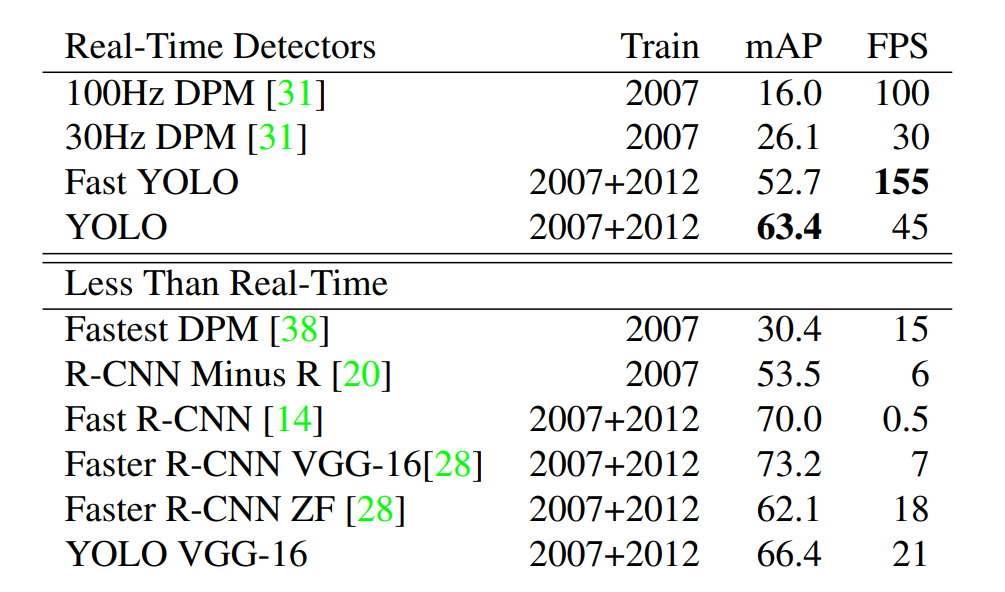
보이는 것처럼, 다른 fast detectors의 성능과 속도와 비교했을 때 Fast YOLO가 약 2배의 mAP인 52.7를 기록하고 있고, 가장 빠른 detector라는 것을 알 수 있다. 또한 YOLO는 less than real-time 모델들과 비교했을 때 비등비등한 mAP를 기록하며 동시에 real-time 성능 또한 훌륭함 보여주고 있다.
4.2. VOC 2007 Error Analysis
저자들은 좀 더 VOC 2007 dataset을 이용하여 YOLO와 Fast R-CNN을 비교하여 아래의 각 error type에 대한 분석을 진행하였다.
- Correct: correct class and IOU > .5
- Localization: correct class, .1 < IOU <.5
- Similar: class is similar, IOU > .1
- Other: class is wrong, IOU > .1
- Background: IOU < .1 for any object
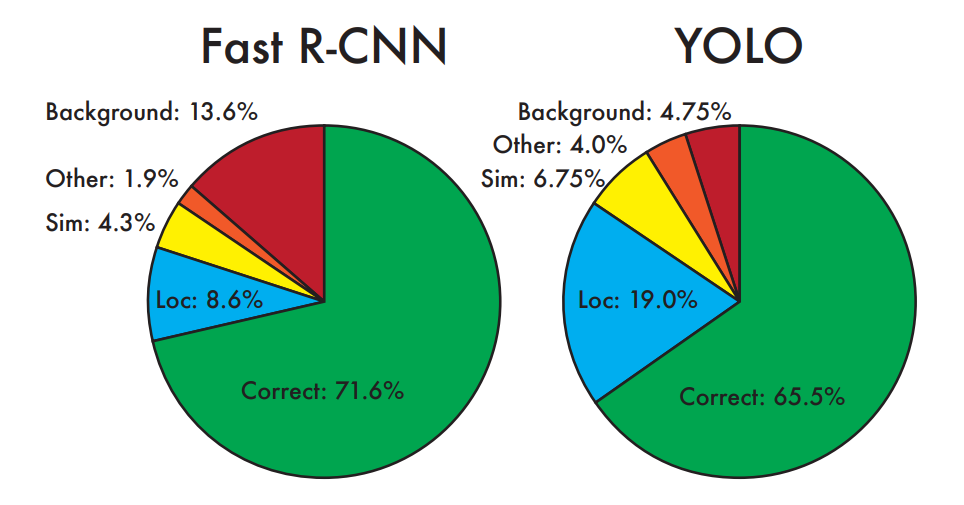
보이는 것처럼 YOLO는 object localization을 Fast R-CNN만큼 잘 해내지 못한다. 반면 Fast R-CNN은 YOLO와 비교했을 때 background error를 훨씬 많이 만든다.
4.3. Combining Fast R-CNN and YOLO
이 error type breakdown을 마친 저자들이 다음으로 한 것은 YOLO와 Fast R-CNN을 combine하는 것이다. YOLO가 잘 해내지 못하는 object detection을 Fast R-CNN이 보완하고, Fast R-CNN이 잘 해내지 못하는 background detection을 YOLO가 보완해 줄 수 있기 때문이다. 과정은 이러하다. R-CNN이 예측한 모든 bbox에 대해 YOLO 또한 비슷한 box를 예측했는지 확인한다. 만약 그렇다면, 우리는 YOLO가 예측한 확률과 두 bbox 사이의 overlap 정도에 따라 해당 예측을 보강한다.
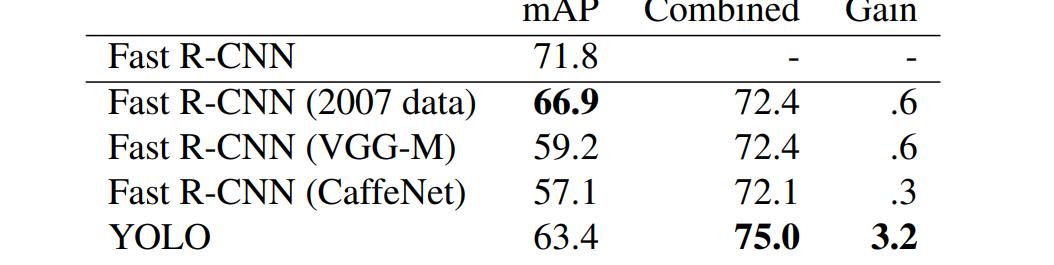
결과를 보면 Fast R-CNN과 다른 모델을 combine 했을 땐 향상도가 미미하지만, YOLO와 combine 했을 땐 상당한 performance boost가 생겨났음을 알 수 있다. 그러나 이 combined 모델은 YOLO가 원래 제공하는 빠른 속도의 장점을 활용하지 못한다. 각각의 모델을 개별적으로 돌리고 결과를 합쳤기 때문이다. 그러나 YOLO가 매우 빠르기 때문에 computational time에는 큰 변동이 없다고 한다.
4.4. VOC 2012 Results
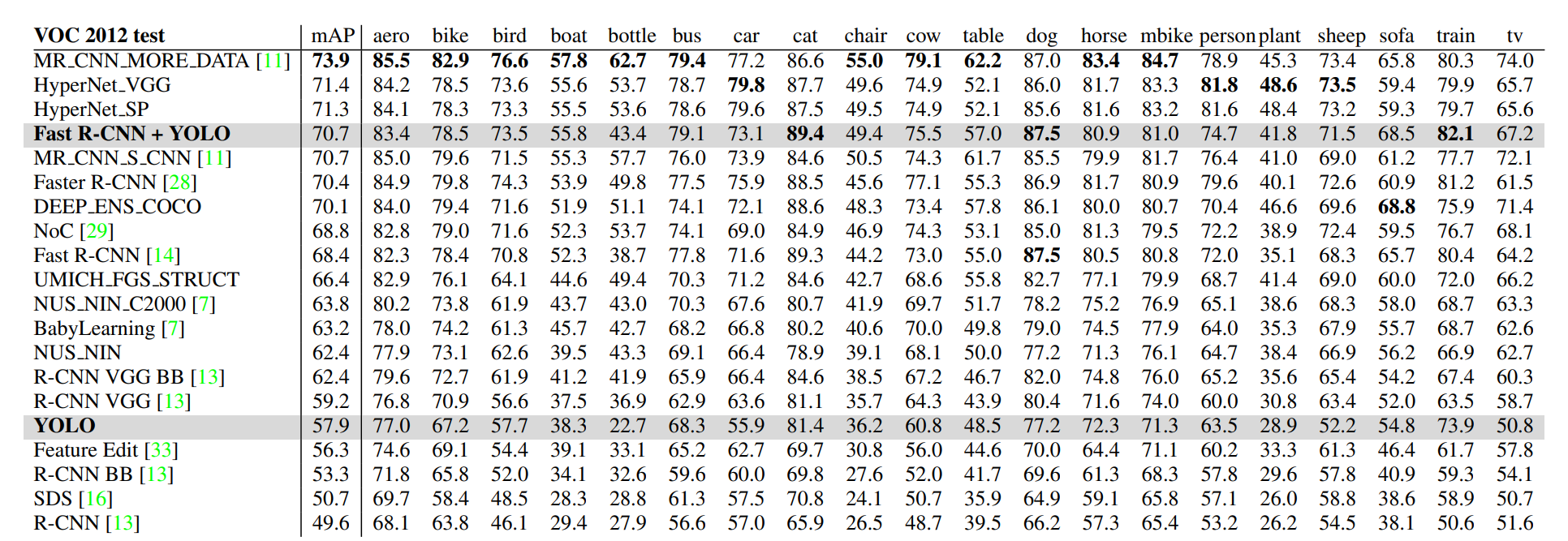
VOC 2012 train set에 대해 YOLO는 57.9% mAP를 기록했다. 이는 YOLO가 bottle, sheep, tv/monitor와 같은 category에 속하는 작은 objects들을 잘 detect하지 못하기 때문이라고 저자들은 밝혔다. 반면 앞서 언급했던 Fast R-CNN + YOLO 모델은 꽤나 훌륭한 mAP를 기록했다.
4.5. Generalizability: Person Detection in Artwork
4.5.에서는 Picasso Dataset과 People-Art Dataset을 활용하여 YOLO가 다른 detection model에 비해 person detection을 얼마나 잘 수행하는지 비교하였다. 보다시피 YOLO는 다른 model들과 비교하였을 때 AP의 감소 정도가 상대적으로 적음을 알 수 있다.
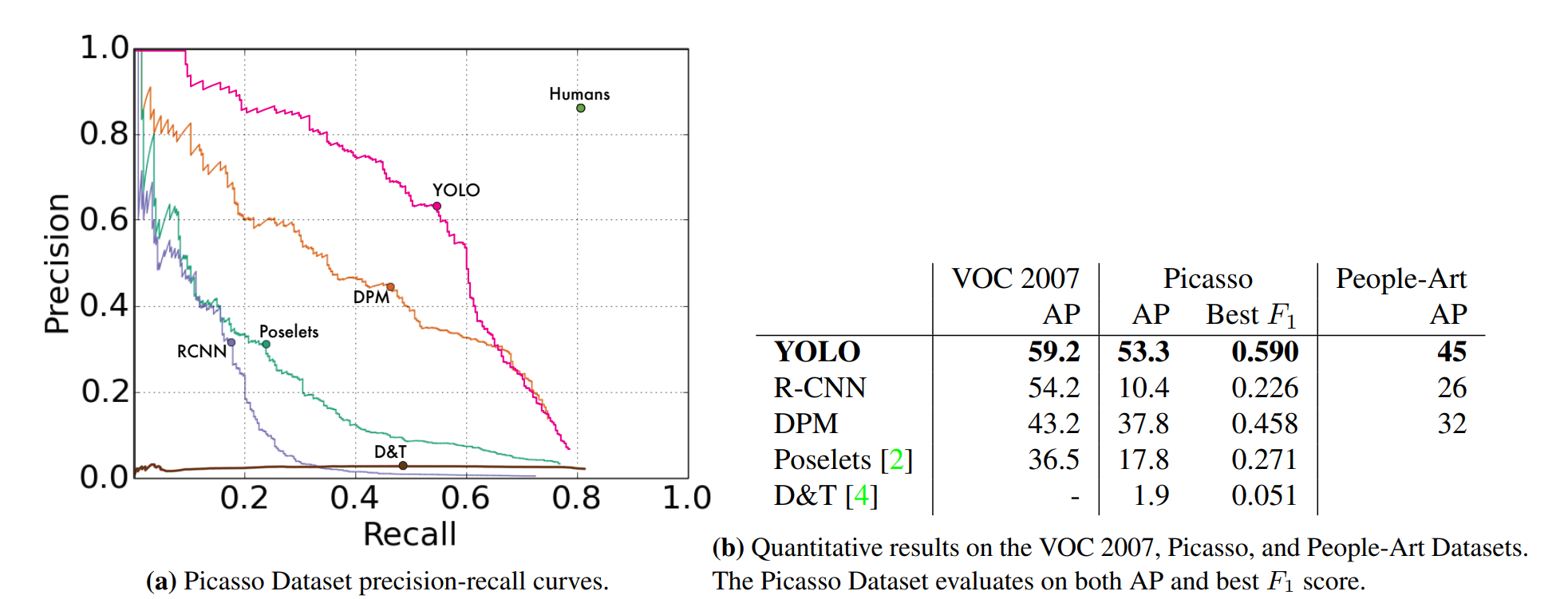
YOLO는 object가 특정한 크기나 형태로 자주 나타나는 패턴이나, 특정 위치에 있을 가능성이 높은 패턴을 학습한다. artwork나 natural image의 픽셀 수준은 매우 다르지만, object의 크기와 형태 측면에서는 유사하기 때문에 YOLO는 여전히 좋은 바운딩 박스와 탐지를 예측할 수 있다고 저자들은 설명한다.

5. Real-Time Detection In The Wild
YOLO를 webcam에 활용해 만든 resulting system은 마치 tracking system처럼 잘 작동한다고 한다. 다음 사이트에서 source code를 확인할 수 있다. https://pjreddie.com/darknet/yolo/
6. Conclusion
YOLO를 unified model로 소개한 만큼, YOLO는 구축하기도 간단하고 full image를 활용해 학습시킬 수도 있다. 또한, YOLO는 속도와 성능 면에서 뛰어나며 다양한 분야에 적용될 수 있어, 신속하고 안정적인 object detection이 필요한 다양한 applications에도 적합하다.
느낀 점
실전! 프로젝트로 배우는 딥러닝 컴퓨터 비전을 읽던 중 직접 논문을 살펴볼 필요성을 느껴서 찾아보게 되었다. 확실히 Faster R-CNN보다는 좀 더 이해하기 수월했던 것 같다.
논문을 다 읽고 기억에 남는 건 세 가지 정도가 있었다. 먼저 YOLO의 loss function이다. loss function의 한 줄 한 줄을 살펴 보면 (1)bbox를 잘못 예측했을 때의 loss와 object를 포함하지 않은 box의 confidence predictions에 대한 loss의 영향을 다르게 설정하려는 노력과 (2)large box와 small box의 weights error를 해결하려는 노력과 (3)해당 그리드 셀에 객체가 있을 때만, resposible bbox일 때만 오류를 학습하게 하여 모델의 학습을 효율적으로 만들고자 한 것이다. 정말 '꼼꼼하게' loss function을 설계했음이 느껴졌다.
두 번째로는 YOLO와 Faster R-CNN model을 combine하여 향상된 결과가 단지 서로 다른 두 모델을 'ensemble'했기 때문이 아니라고 설명한 부분이다. 저자는 오히려 향상된 결과가, Fast R-CNN과 YOLO가 서로 다른 종류의 mistake를 만들기 때문에 둘을 combine 했을 때 서로의 취약점을 서로가 보완하여 나온 결과라고 덧붙였다. 이 구절을 읽고 떠오른 경험이 있었다. 이전에 참여했던 해커톤에서 성능 향상을 위해 여러 model을 결합하였을 때 결합한 모델의 성능이 단일 model의 성능과 비슷하게 나온 적이 있었다. 그때 해커톤이 끝나고 왜 그런지 이유를 찾아보며 너무 비슷한 계열의 model들을 앙상블하면 성능 향상이 미미할 수 있음을 알아냈다. 그때 당시엔 강력한 모델끼리 앙상블하는 게 당연히 결과가 더 좋아질 것 같았는데 이번 Fast R-CNN과 YOLO의 combination을 읽으면서 모델이 강력한 것도 중요할 수 있지만, 서로의 취약점을 서로가 보완할 수 있는 모델을 결합하는 게 모델 성능 향상에 더욱 도움이 될 수 있음을 다시금 느끼게 되었다.
마지막으로는 좀 신기했던 점인데 YOLO가 strong spatial costraints로 인해 작은 objects이나 새떼처럼 무리 지어 등장하는 objects를 잘 구별하지 못한다는 설명이 있었다. 이 설명을 읽을 때만 해도 왜 이렇게 spatial constraints를 강하게 설정했을까 싶었는데, 나중에 YOLO와 R-CNN을 비교하는 단락을 읽으며, 이 spatial constraints 덕에 같은 object에 대해 multiple detection을 하는 것을 완화할 수 있다는 점을 알게 되었다. strong spatial constraints가 multiple detection을 해결하는 데 기여하면서도, 다른 측면에서는 detection 성능에 제한을 두는 것을 알게 되고 나서는 이후의 모델에서는 이 constraint의 장점은 살리면서 어떻게 limit을 극복해 나갈지 궁금해졌다.
확실히 velog에 논문 리뷰 글을 작성하려니 논문을 더 꼼꼼하게 읽게 되는 것 같다. 아직은 논문 리뷰 경험이 많이 없어서 그런지 읽는 시간, 이해하는 시간, 정리하는 시간이 생각보다 훨씬 많이 들었다.
