먼저 본포스트는 보물찾기님의 블로그와 데이터 사이언스 스쿨을 많이 참고하여 제 언어로 정리하였음을 밝힙니다. 아래 reference를 확인하여 함께 공부하면 도움이 되겠습니다.
Classification and Regression
이번 포스트에서는 분류와 회귀를 아우른다는 점에서 공통점이 있는 Logistic Regression과 Gradient decent algorithm에 관해 공부해보고자 한다. 시작하기에 앞서, 아직 분류와 회귀에 대해 잘 모르는 분들이라면 위에 북마크 처럼 되어 있는 Machine Learning 카테고리 시리즈에서 분류와 회귀 편을 찾아 읽거나 각각 여기와 여기를 클릭하여 보고 오시는 것을 추천드린다.
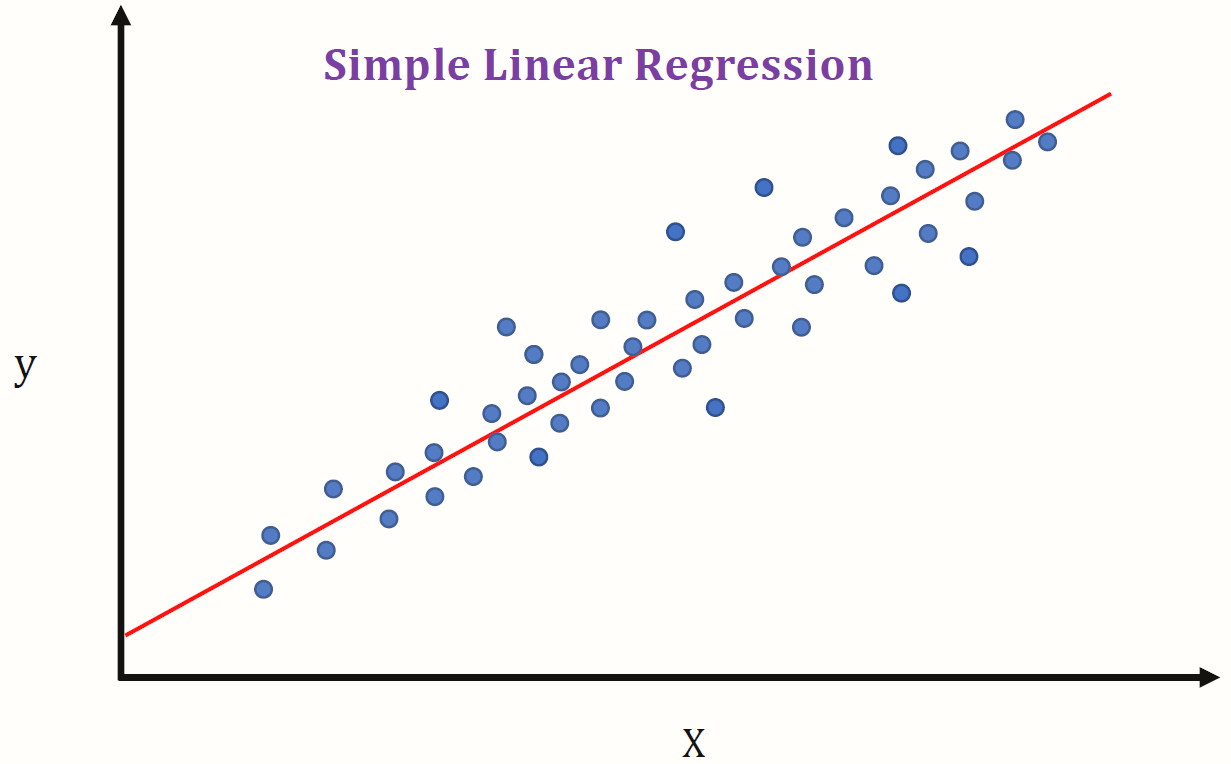
회귀에 대해 공부할 때 일반적인 선형 회귀(Ordinary Linear Regression)은 설명변수 X와 연속형 결과값을 가지는 종속변수 y 간의 선형 관계가 성립함을 가정하고 이를 가장 잘 표현할 수 있는 회귀 계수 β를 데이터로 부터 최소제곱법 등의 방법을 이용하여 추정하는 모델이라고 하였다. 그 근간이 되는 선형방정식은 다음과 같다.
y^=i=1∑Nwixi+b⇒y=Xβ^+ϵ
이를 그래프로 나타내면 회귀의 경우 다음과 같이 나타난다.
IMG source from medium blog
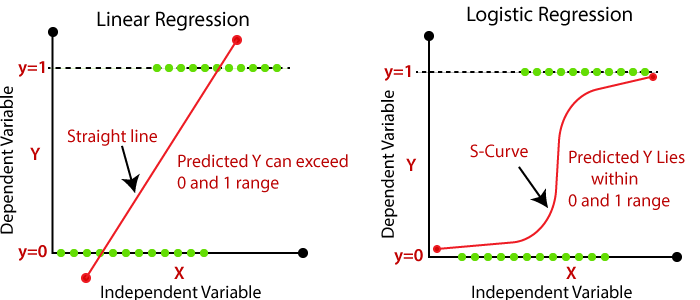
이는 앞서 말했듯 종속 변수 y가 연속형 데이터 값을 가질 때 그리는 그래프인데, 만약 종속 변수가 아래와 같이 0과 1, yes/no, True/False라면 어떻게 되고 이는 어떻게 설명할 수 있을까? IMG source from jinseob2kim.github
왼쪽 그림이 선형방정식을 이용해서 linear regression 으로 접근했을 때인데 잘 보면 직선 하나로 데이터의 분포를 명확하게 설명할 수가 없다. 또한 영어 설명에 나와있듯 예측변수 Y^가 정답레이블인 0과1을 초과해버리기 때문에 올바르게 회귀된 것이 아님을 알 수 있다. 이러한 문제를 개선하고자 한 것이 Logistic Regression이며, 그 형태는 오른쪽 그림과 같다.
Logistic Regression
일단 회귀라는 말이 들어가서 회귀인 것 같은데... 라고 생각이 들 수 있지만, 명칭과 달리 회귀 뿐만 아니라 분류에서도 사용되고, 오히려 입력데이터를 통해 특정 분류로 결과가 나오기 때문에 분류에 더 가까운 방식이다. 먼저 가장 쉽게 접근하기 위해 위키피디아에 정의된 logistic regression의 개념을 살펴보자.
로지스틱 회귀는 1958년 미국의 통계학자인 David Cox가 제시한 확률 모델이고, 독립 변수의 일차결합(Linear combination)을 이용하여 사건의 발생 가능성을 예측하는 통계 기법이라고 정의 된다. 일반 회귀 분석과 동일하게 독립변수 X와 종속 변수 Y의 관계를 구체적인 함수로 나타내어 예측 모델에 사용하는데, 종속 변수가 연속형이 아닌 범주형(명목형) 데이터로 그 범위가 0과 1사이의 확률값으로 나온다는 점에서 회귀와 분류의 두가지 면모를 동시에 지닌다. 의료, 통신, 데이터마이닝과 같은 다양한 분야에서 분류 및 예측을 위한 모델로 사용된다.
즉 정리하자면, logistic regression은 종속변수(결과변수)가 범주형인 데이터 예측에 적합하게 제안된 모델이며 또한 linear regression이 확률을 예측할 수 없는데에 비해 이 logistic regression을 사용하면 0~1 (앞으로는 [0,1]로도 표현하겠다)사이의 값을 출력하면서 특정 변수에 대한 확률을 예측할 수 있게 된다. 다만, y의 결과 범위가 [0,1]인 것 외에도 일반적인 선형회귀와는 달리 독립변수와 종속 변수간의 조건부 확률 P(y∣x)의 분포가 정규분포 대신 이항 분포를 따른 다는 특징도 있다.
1. odds(승산)의 개념
먼저 로지스틱 회귀를 제대로 이해하기 위해서는 다소 생소한 개념인 'odds', 우리말로는 승산이라는 개념에 대해 알아야 한다.
승산이란 임의의 사건 A가 발생하지 않을 확률 대비 일어날 확률의 비율을 일컫는다. 좀 더 쉽게 말하자면, 실패와 성공이라는 상호배반적(mutual exclusive) 사건이 있을 때 승산은 실패할확률성공할확률=실패횟수성공횟수로 정의 되며,이를 좀 더 수학적으로 나타내면 다음과 같다.
odds=1−p(y=1∣x)p(y=1∣x)=P(Ac)P(A)=실패성공
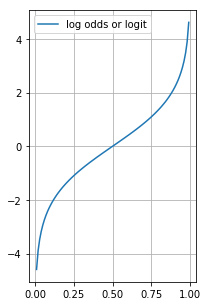
성공횟수가 많을 수록, 즉 위 수식에서 p(y=1∣x)와 P(A)의 값이 1에 가까울 수록 승산은 높아지며, 0에 가까울 수록 승산은 0에 수렴할 것이다. 그리하여 승산이 갖는 특징은 그래프로 다음과 같이 나타난다.
확률(Probability)과 헷갈려 할 수 있는데, 확률은 전체 시도 중에 성공한 개수의 비율을 나타낸 것으로 성공과 실패만을 가지고 정의한 승산과는 차이가 있다. 대표적으로 equal odds 라고 하면 이는 성공과 실패의 비율이 1:1을 가져 결과적으로 1이 되지만, equal probabilities는 성공+실패성공가 되어 0.5가된다. 또 odds 값의 범위는 0 ~ +∞가 되는데 확률은 [0,1]이라는 차이도 있다.
2. Binary Logistic Regression
2.1 Logit and Sigmoid function
먼저 주로 사용되는 이진 로지스틱 회귀에 대해 살펴보자.
결과변수 Y가 범주형이면 기존 회귀 모형으로는 풀 수 없으므로 회귀식의 장점인 일차결합형태(linear combination)를 살리면서 Y가 범주가 아닌 1의 범주가 될 확률로 두고 아래와 같이 식을 세워 접근해보고 싶다.
P(Y=1∣X=x)==β0+β1x1+β2x2+...+βpxpβTx
이 때 좌변은 확률이므로 범위는 [0,1]인데 비해 우변은 −∞,+∞ 이므로 범위가 서로 맞지 않아 이렇게 풀수 없다.
1−P(Y=1∣X=x)P(Y=1∣X=x)=(1−p)p=βTx
이번에는 좌변을 승산으로 바꾸어 비슷한 무한대의 범위를 갖게 할 수 있으나 여전히 완벽히 맞지 않기 때문에, 좌변에 log를 씌우면 재밌는 현상이 나타난다.
log(1−P(Y=1∣X=x)P(Y=1∣X=x))=log(1−p)p=βTx
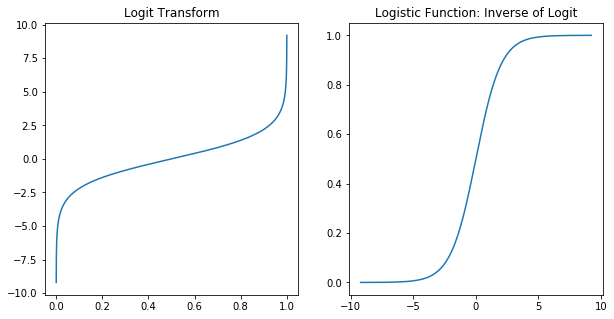
말려 올라갔다가 내려 오는 모양과 범위가 딱 우리가 맞추고 싶어하던 −∞,+∞ 양상을 띄는 것을 알 수 있다. 이렇게 로그를 씌운 승산을 logit (function) 이라고 부르며, 이를 확률 p에 대해 풀면 다음과 같이 정리할 수 있다.
위 변환을 그래프로 나타내면 아래와 같이 되고, 역함수를 취했을 때 도출되는 함수 형태를 Logisitic function 또는 Sigmoid function이라고 한다. 참고로 로그 변환은 통계에서 다음 장점들로 인해 자주 사용한다. 1. 함수의 증감 형태, convex/concave(볼록/오목) 형태 유지 2. 극점의 위치 유지 3. 곱셈과 나눗셈으로 표현된 식을 덧셈과 뺄셈 형태로 풀어줌
IMG source from dgkim5360.tistory
시그모이드 함수는 x값으로 어떤 값이든 받지만, 출력결과는 항상 0에서 1사이의 값을 반환하며 수학적으로 확률밀도함수(Probability density function) 요건을 충족한다고 한다. 수식으로 다음과 같이 나타낸다.
결과적으로 logit과 sigmoid는 역함수 관계를 지니며, logit(y)=z,Sigmoid(z)=y처럼 변환 된다는 것을 알 수 있다. 이 로지스틱 함수를 쓰기 때문에 로지스틱 회귀라고 명명 된 것은 아닐까 함께 짐작해본다.
2.2 Decision Boundary(결정경계)와 판별함수
시그모이드 함수를 쓸 이진 로지스틱 회귀의 경우 입력 z값의 범위에 따라 다음과 같은 관계를 갖는다.
z=0 일 때 μ=0.5
z>0 일 때 μ>0.5→y^=1
z<0 일 때 μ<0.5→y^=0
따라서 z는 분류 모형의 판별함수(결정함수) 역할을 하고, logistic regression은 판별함수로 linear function을 채택하므로
z=βTx
가 성립한다. 따라서 βTx가 로지스틱 회귀모델의 결정경계면(decision hyperplane)이 되어 범주를 0과 1로 분류하게 된다. 이제 위의 로지스틱함수와 엮어서 이해해보자. 이진 분류에서 회귀계수 β가 β=β0−β1처럼 임의의 두 벡터 β0, β1의 차로 표현이 된다고 할 때, 범주가 1이 될 확률은
그러나 이는 시그모이드 함수 μ가 들어간 비선형 함수이므로 선형 모형처럼 쉽게 구할 수는 없고, 수치적 최적화 방법(numerical optimization)의 일종인 경사하강법(grediant decent algorithm)을 통해 반복적으로 최적의 파라미터 β를 찾아가야 한다.
어떤 목적함수를 J(β)라고 할 때, 로그가능도 함수 l(β)를 최대화하는 것은 이 목적함수에 마이너스를 취해 이를 최소화 하는 것으로 여길 수 있다.
J(β)=−l(β)
기울기벡터를 gk라고 하면 최대 경사도(Steepest Gradient Descent) 알고리즘이 적용했을 때 목적함수를 β로 미분한 gk=dβd(−l(β))가 되고 스텝사이즈 ηk만큼 이동하는 다음 수식을 갖게 되며 결과적으로 β를 추정할 수 있게 된다.
k개 클래스가 있더라도 확률은 위와 같이 정리 되며, k번째 범주에 해당하는 회귀계수 βk벡터를 구하고 싶다면 이 확률들에 로그를 씌운 로짓(logit, log odds)을 이용한다. 0을 제외한 범위에서 확률 p는 odds(오즈;승산) 1−pp보다 작다. 또 multinormial logistic regression model에서 오즈의 분모는 모두 똑같이 K번째 범주에 속할 확률이므로, 다음 K개 식 모두에 같은 어떤 값을 빼준다.
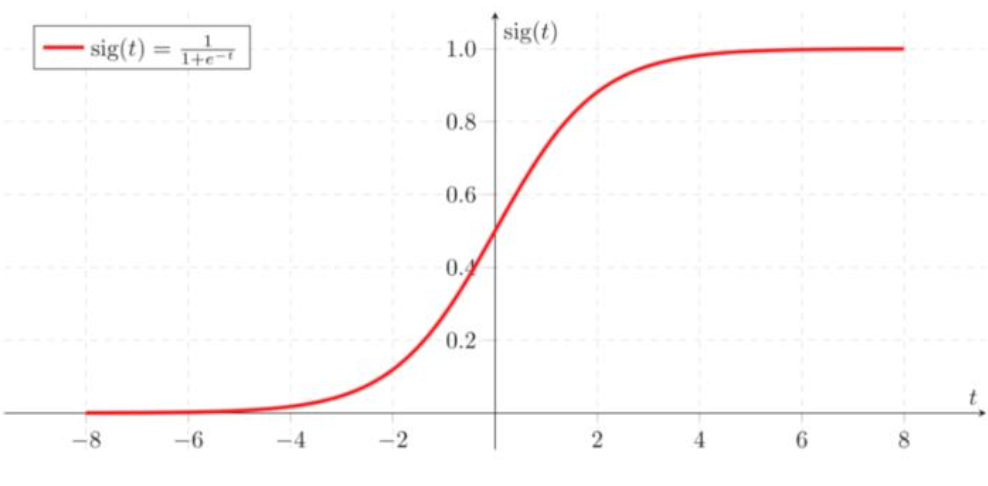
 IMG source from jinseob2kim.github
IMG source from jinseob2kim.github