.png)

2021년 2월 7일
3주차 리뷰
이번주는 앞으로의 내가 나아가야할 방향성을 배운 날이라 생각한다.
취업을 위해 뭘 해야할지 몰랐던것이 문제라면 지금은 해야할것들이 보인다. 너무 잘보여서 문제이다. 매번 학습을 할때마다 나의 빈틈이보이고 알고리즘같은 경우는 디테일이 모잘라서 엣지케이스를 만나면 여지 없이 실패를 출력해낸다. 주변 동기들의 조언을 들어보면 많이 풀다보면, 익숙해지면 그런 것들이 서서히 보이기 시작한다고 한다. 내가 그 친구들에 비해서 얼마나 뒤늦게 출발했는가가 여실히 들어나는 예라고 생각이 들었다. 모자란 부분들을 채워나가고 더 많은 알고리즘 경험을 쌓자!
문제를 잘 풀진 못해도 뭘 해야할지 아는 달라진 내가 너무 좋다.
표준 입출력
byte char입력 스트림 InputStream Reader
출력 스트립 OuputStream Writer
- System.in : 입력
- System.out : 출력
- System.err : 표준 에러 출력
노드 스트림
- 표준 입출력을 위해 필수적으로 사용 되어야한다
필터 스트림(Process Stream)
- 노드 스트림속에 선택적으로 사용'
Scanner
java.utill.Scanner
-
파일,입력 스트림등에서 데이터를읽어 구분자로 토큰화 하고 다양한 타입으로 형변환하여 리턴해주는 클래스
-
nextInt() , nextDouble(),next() → 구분자가 나오기 전까지 읽어 드린 후 다음에 진행 될때기존에 유효문자 전에 남아있는 구분자의 잔재를 다 떼버리고 다음 구분자 전까지의 유효문자만 출력한다 .
-
nextLine() →커서끝에서 부터 읽어온 후에 개행을 떼고 앞에온 개행을 떼고 출력 nextLine은 개행빼고 모두 유효글자이다.
-
code
public class IO2_ScannerTest { public static void main(String[] args) { String s1 = "안 \n녕 \n"; Scanner sc = new Scanner(s1); System.out.print("읽은 문자열 :"+ sc.next()); System.out.print(",읽은 문자열 :"+ sc.next()); System.out.println("\n================================="); String s2 = "안 녕 \n"; Scanner sc2 = new Scanner(s2); System.out.print("읽은 문자열 :"+ sc2.nextLine()); System.out.println("\n================================="); String s3 = "안 \n 녕 \n"; Scanner sc3 = new Scanner(s3); System.out.print("읽은 문자열 :"+ sc3.nextLine()); System.out.println("\n================================="); System.out.print("읽은 문자열 :"+ sc3.nextLine()); System.out.println("\n================================="); } }-
출력
읽은 문자열 :안,읽은 문자열 :녕
읽은 문자열 :안 녕
읽은 문자열 :안
읽은 문자열 : 녕
NextLine과 나머지 3개는 섞어 쓸경우 이렇나 문제점을 잘 알고 진행해야한다.
-
-
대량의 데이터 처리 시 수행시간이 비효율적임
주요 메소드
- nextInt() , nextDouble(),next() 각 타입 반환 ,White Space(space,tab,enter)을 만나면 종료
- nextLine() ,문자열 반환 개행(enter)를 만나면 종료 next() 달리 문자열 안에 띄어쓰기를 할 수 있다(공백을 포함가능)
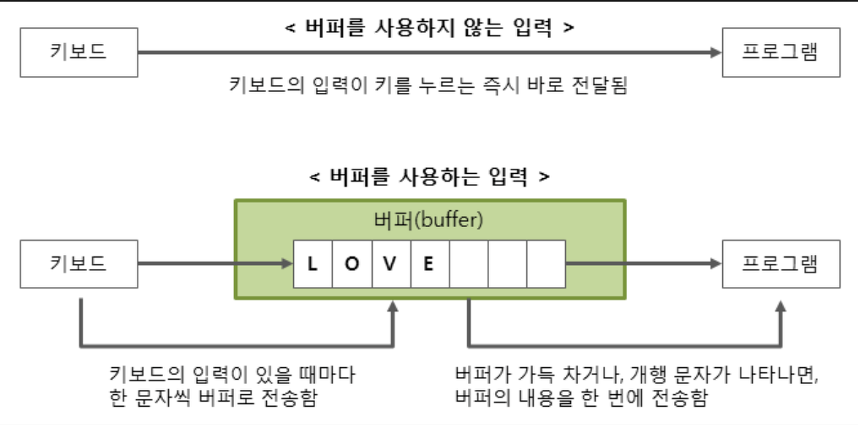
String Buffered Reader/buffered Writer
버퍼를 이용해서 읽고 쓴느 함수, 이 함수는 버퍼를 이용하기 떄문에 이 함수를 이용하면 입출력의 효율이 굉장이 높아진다. 하드디스크의 경우 속도가 굉장히 느리기 때문에 키보드로 들어오는 입력은 시간이 굉장히 많이 걸리는 작업이다, 그래서 키보드가 입력을 받을 때마다 전송하는 것보다 중간에 버퍼를 만들어 데이터를 한데 묶어서 전송하는것이 효율적이다.
눈을 치울때 한자루식 퍼서 옮기는것보다 한번에 모아서 치우는것이 효율적이다.
- 필터 스트림 유형
- 줄 단위로 문자열 처리 기능 제공 → readLine()
- 대량의 데이터 처리시 수행시간이 효율적이다. → scanner 보다 훨씬 좋은 성능을 가지고 있다.
- buffer flush로 버퍼를 비울 수 있다.
system.in을 reader형으로 만들기 위해서 InputStreamReader를 사용하고 그 데이터를 BufferedRead의 데이터로 사용 한다.
구분자를 이용해 잘린 것들을 토큰이라고 부른다.
-
code
import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.util.StringTokenizer; public class IO4_BufferedReaderTest { public static void main(String[] args) throws NumberFormatException, IOException { //파일에서 입력받을 경우 FileReader fr = new FileReader("BufferedReaderEx1.java"); BufferedReader br_f = new BufferedReader(fr); //콘솔에서 입력받을 경우 BufferedReader in = new BufferedReader(new InputStreamReader(System.in)); //String 리턴값이라 형변환 필수! 라인단위 주로 테스트 케이스 갯수를 입력받을때 사용 int n = Integer.parseInt(in.readLine()); StringTokenizer st = new StringTokenizer(in.readLine(), " "); for(int i=0;i<n;i++) { System.out.println(st.nextToken()); } for (int t = 1; t <= 10; t++) { //int N값을 가져오는것 String타입이라서 Integer로 변환 N = Integer.parseInt(br.readLine().trim()); //toCharArray로 chars배열안에 읽어온 값들을 저장; //Int로 사용 하고 싶다면 사용할떄 - '0'을 해주면됨 chars = br.readLine().toCharArray(); System.out.println(Arrays.toString(chars)); //배열에 삽입하는 두가지 방법 for (int i = 0; i < N; i++) { nums_test[i]=Integer.parseInt(st.nextToken()); } //2 nums=br.readLine().toCharArray(); } } } -
Wrapper Class
기본 클래스를 참조클래스를 사용 (메소드)
-
int → Integer
-
double → Double
-
float → Float
-
boolean → Boolean
-
char → Character
parseInt → 문자열로 선언되어 있지만 숫자가 들어온 경우 int형으로 사용가능
-
-
StringBuilder
- 문자열의 조작을 지원하는 클래스
- 자바에서 상수로 취급되는 문자열을 조작 시마다 새로운 문자열이 생성되는것을 방지
- append()
- toString()
알고리즘
어떤 문제를 해결하기 위한 절차
알고리즘 해결 과정
- 문제를 읽고 이해한다.
- 문제를 익숙한 용어로 재정의한다(조건 , 유의사항)
- 어떻게 해결할지 계획을 세운다
- 계획을 검증한다. (← 테스트 케이스를 확인 , 계산이 가능한 작은 범위 테스트케이스)
- 프로그램으로 구현한다. (150줄 이상인 경우 다시 생각해보기)
- 어떻게푸렀는지 돌아보고 개선할 방법이 있는지 찾는다. (다 푼후에 나중에 개선할 방법이 있는지 찾아본다)
문제 해결 전략
-
직관과 체계적인 접근
-
체계적인 접근을 위한 질문들
비슷한 문제를 풀어본 적이 있던가 ?
문제를 단순화 할 수 있을까 ?
그림으로 그려 볼 수 있을까 ?
수식으로 표현 할 수 있을까 ?
문제를 분해 할 수 있을까 ? (→ 재귀)
뒤에서부터 생각해서 문제를 풀 수 있을까?
특정 형태의 답만 고려 할 수 있을까 ?
무엇이 좋은 알고리즘인가 ?
- 정확성 : 얼마나 정확하게 동작하는가 ?(기본)
- 작업량 : 얼마나 적은 연산으로 원하는 결과를 얻어내는가
- 메모리 사용량 : 얼마나 적은 메모리를 사용하는가
- 단순성 : 얼마나 단순한가 (유지보수)
- 최적성 : 더이상 개선할 여지 없이 최적화 되었는가 ?
빅-오(O) 표기법
- 시간 복잡도 함수 중에서 가장 영향력을 주는 N에 대한 항만을 표시
- 계수는 생략하여 표시
- O(3N +2 ) → O(3n) → O(N)
- 예시 ) n개의 데이터를 입력받아 저장한 후 각 데이터에 1씩 증가시킨 후 각 데이터를 화면에 출력하는 알고리즘의 시간 복잡도는 ? → O(n)
- 연산이 1억 번 정도 되면 1초가 걸린다고 생각 하고 문제를 풀어보자
반복(Iteration) 과 재귀 (recursion)
- 반복과 재귀는 유사한 작업을 수행할 수 있다.
- 반복 : 반복패턴 찾고 주어진 횟수를 만족할떄 까지 수행 (포인트 : 단위 반복을 찾는것! → 언제 끝낼지)
- 반복은 수행하는 작업이 완료될 때까지 계속 반복 → 루프(for, while,do~while)
재귀함수(recursive function)
- 함수 내부에서 직접 혹은 간접적으로 자기 자신을 호출하는 함수
- 일반적으로 재귀적 정의를 이용하여 재귀함수를 구현
- 따라서, 기본부분(basic part) (종료 파트) 와 유도 파트(inductive part)로 구성된다
- 재귀적 프로그램을 작성하는것은 반복 구조에 비해 간결하고 이해하기 쉽다.
- → Flat!! 평평하게 쉽게 생각할것! 재귀적으로 타고 들어가는 것을 생각하지 말자!
- 함수 호출은 프로그램 메모리 구조에서 스택을 사용한다.
- 따라서 재귀 호출은 반복적인 스택의 사용을 의미하며 메모리 및 속도에서 성능저하가 발생한다.
- 역할을 명확히 ! (함수의 역활 - WHAT)
- 언제 끝이 나는가 ? (기저 조건 → basic part)
- 각 함수가 수행될때 필요한 가변적인 값? → 매개변수!
- 팩토리얼 재귀함수
- 일반적으로 , 재귀적 알고리즘은 반복 알고리즘보다 많은 연산을 필요로 한다.
- 입력값 N이 커질수록 재귀 알고리즘은 반복에 비해 비효율적 일 수 있다.
메모이제이션
컴퓨터 프로그램을 실행 할 떄 이전에 계산한 값을 메모리에 저장해서 매번 다시 계산하지 않도록 전체적인 실행속도를 빠르게 하는 기술이다.
하노이탑
N개의 원판 이동 :
- N-1개 원판 이동(시작 →임시기둥)
- N번째 원판 이동(시작 → 목적)
- N-1개 원판 이동(임시 → 목적)
매번 실행 할때 마다 원판의 개수가 다르다. 시작 기둥과 목적기둥이 계속 바뀐다.
seudo code
//n개 원판을 시작기둥(from) -> 목적 기둥(to)으로 모두 이동
hanoi(n,from,temp,to)
honoi(n-1,from,to,temp)
//n번째원판 이동
hanoi(n-1,temp,from,to)
if(n==0) return; //기저조건2차원 배열
array of array
2차원 이상의 다차원 배열은 각 차원에 따라 크기를 명시한다.
-
행 우선 순회
-
열 우선 순회
-
지그재그 순회
행의 홀 ,짝으로 나누어서 처리하는 방법
짝수행 홀수행
0 +3 (3-0) 3
1 +1 (3-2) 2
2 -1 (3-4) 1
3 -3 (3-6) 0
일반식을 찾아서 해결 하는 방법 ( 생각이 안나면 시간낭비)
for (int i= 0 ; i< n;i++) for(int j=0; j<m;j++) { array[i][j+(m-1)-2*j) * (i%2)] } -
지그재그 순회
for (int i = 0; i < row; i++) {
if(i%2==0) {
for (int j = 0; j < col; j++) {
//수행할일 행의 번호가 짝수일때 수행할일
}
}else
{
for (int j = col; j>=0; j++) {
//홀 수 일때 수행할일
}
}
}-
델타를 이용한 2차열 배열 탐색
사방 탐색
dx ,dy를 배열로 만들어 사방 탐색을 접근
대신 상하좌우 따로 하는것 보다 실행 시간이 많이 걸릴 수도 있다
→ 데이터가 만을경우 따로 생성한느거 추천
-
전치행렬
완전 탐색
탐욕적 알고리즘은 접근은 해답을 찾아내지 못하는 경우도 있으니 유의해야 한다.
완전 탐색 방법은 문제의 해법으로 생각할 수 있는 모든 경우의 수를 나열해보고 확인하는 기법
Brute-force 혹은 generate-and-test기법이라고도 불린다.
모든 경우의 수를 테스트한 후, 최종 해법을 도출한다.
구현시간은 빠르다
일반적으로 경우의 수가 상대적으로 작을때 유용하다.
완전 탐색의 예시 순열 조합 그리고 부분집합 과 같은 조합적 문제들과 연관된다
****순열 부분집합 조합은 매일 풀기
-
순열 문제의 경우 9! 10! 이 마지노선이라고 생각한다.
-
문제
- problem1: 출발 , 도착 선택 , 모든 도시를 여행 시켜드립니다. 단 숙박비는 본인부담 -? 순열
- problem 2 : 3개의 도시를 선택하면 3개 도시의 숙박비를 지원해드립니다.(단 숙박비만 고려) → 조합 6c3
- problem 3: 추가 도시 할인 2개 선택 10%, 3개선택 20%, 4개 선택 30% 할인 (단,이동경비 무료) → 부분 집합 6c1, 6c2, 6c3......
-
code(지그재그탐색)
for (int i = 0; i < row; i++) { if(i%2==0) { for (int j = 0; j < col; j++) { //수행할일 행의 번호가 짝수일때 수행할일 } }else { for (int j = col; j>=0; j++) { //홀 수 일때 수행할일 } } }
순열(Permutation)
-
나열된 순서가 의미를 가지는 경우 → 대표 와 부대표를 뽑는 경우를 생각
-
서로 다른 것들 중 몇개를 뽑아서 한 줄로 나열하는 것
-
서로 다른 n개 중 r개를 택하는 순열은 아래와 같이 표현
→ nPr\
-
10! = 360만
-
3 P 3경우의 수 = n!과 같다.
-
반복문을 통한 순열 생성
-
재귀 호출을 통한 순열 생성
조합(Combination)
isSelected같은 중복 관리 필요 X
-
재귀호출을 이용한 조합 생성 알고리즘
-
code
부분집합
-
집합에 포함된 원소들을 선택하는 것이다.
-
다수의 중요 알고리즘들이 원소의 그룹에서 최적의 부분 집합을 찾는 것이다.
예)배낭 짐싸기(Knapsack)
-
부분집합의 수
집합의 원소가 n개 일떄, 공집합을 포함한 부분집합 개수는 2^n개이다.
이는 각 원소를 부분집합에 포함시키거나 포함시키지 않는 2가지 경우를 모든 원소에 적용한 경우의 수와 같다.
-
원소의 개수가 몇개 안되는 경우 → 반복문으로 해결
-
원소의 개수를 모르거나 많은경우 → 재귀로 해결
탐욕(Greedy) 알고리즘
-
탐욕 알고리즘은 최적해를 구하는데 사용되는 근시안적인 방법
-
여러 경우 중 하나를 결정해야 할 떄마다 그 순간에 최적이라고 생각 되는 것을 선택해 나가는 방식으로 진행하여 최종적인 해답에 도달한다.
-
각 선택의 시점에서 이루어지는 결정은 지역적으로는 최적이지만! 그선택들을 계속 수집하여 최종적인 해답을 만들었다고 하여 그것이 최적이라는 보장X
-
일반적으로 머리속에 떠오르는 생각을 검증 없이 바로 구현하면 Greedy적 접근이 된다
-
동작 과정
- 해 선택 : 현재 상태에서 부분 문제의 최적 해를 구한 뒤, 이를 부분해집합(Solution set)에 추가한다.
- 실행 가능성 검사 : 새로운 부분해 집합이 실행 가능한지 확인한다. 곧, 문제의 제약 조건을 위반하지 않는지를 검사한다.
- 해 검사 : 새로운 부분해 집합의 문제의 해가 되는지 확인한다. 아직 전체 문제의 해가 완성되지 않았다면 1)의 해 선택부터 다시 시작한다.
-
예제
거스름돈 줄이기
어떻게 하면 손님에게 거스름돈으로 주는 지폐와 동전의 개수를 최소한으로 줄일 수 있을까?
- 해선택: 여기에선느 멀리 내다볼 것 없이 가장 좋은 해를 선택한다. 단위가 큰 동전으로만 거스름돈을 만들면 동전의 개수가 줄어들므로 현재 고를 수 있는 단위가 가장 큰 동전을 거스름돈에 추가한다.
- 실행 가능성 검사: 거스름돈이 손님에게 내드려야할 액수를 초과하는지 확이한다. 초과한다면 마지막에 추가한 동전을 거스름돈에서 빼고, 1)로 돌아가서 현재보다 한 단계 작은 단위의 동전을 추가한다.
- 해 검사: 거스름돈 문제의 해는 당연히 거스름돈이 손님에게 내드려야 하는 액수와 일치하는 셈이다. 더 드려도, 덜 드려도 안되기 때문에 거스름돈을 확인해서 액수에 모자라면 다시1)로 돌아가서 거스름돈에 추가할 동전을 고른다.
스택(stack)의 특성
-
물건을 쌓아 올리듯 자료를 쌓아 올린 형태의 자료구조.
-
스택에 저장된 자료는 선형 구조를 갖는다.
선형구조 : 자료간의 관계가 1대 1의 관계를 갖는다.
비선형구조: 자료간의 관계가 1대 N의 관계를 갖는다. (예 : 트리)
-
스택에 자료를 삽입하거나 스택에서 자료를 꺼낼 수 있다.
-
후입선출구조(LIFO,Last-In-First-Out)
마지막에 넣은 자료가 제일 먼저 나온다.
.png)
-
주요연산
push : 저장소에 자료를 저장한다 (삽입)
pop : 저장소에 자료를 꺼낸다. (삭제), 꺼낸 자료는 삽입한 자료의 역순으로 꺼낸다.
peek : 스택의 top에 있는 item(원소)를 반환한다.
-
java.utill.Stack
-
주요 메소드
push() 삽입
pop() 삭제
isEmpty()
size()
-
스택의 활용
스택을 이용한 괄호 검사 Function call 프로그램에서의 함수 호출과복귀에 따른 수행 순서를 관리 , 가장 마지막에 호출된 함수가 가장 먼저 실행을 완료하고 복귀하는 후입선출 구조이므로, 후입선출 구조의 스택을 이용하여 수행순서 관리.png)
큐의 특성 (Queue)
-
스택과 마찬가지로 삽입과 삭제의 위치가 제한적인 자료구조
큐의 뒤에서는 삽입만 하고, 큐의 앞에서는 삭제만 이루어지는 구조
-
선입선출구조 (FIFO : First In First Out)
큐에 삽입한 순서대로 원소가 저장되어, 가장 먼저 삽입(First In)된 원소는 가장 먼저 삭제(First Out) 된다.
.png)
Front는 직전에 나간 것을 가리키고 있는곳
Rear 는 마지막에 저장된 원소를 가리키고 있다.
-
큐의 기본 연산
-
enQueue(A)
-
deQueue(B)
-
-
Java에서의 큐
java.utill.Queue
-
큐에 필요한 연산을 선언해 놓은 인터페이스 (명세,약속)→ 즉 사용방법만 존재.
-
LinkedList클래스를 queue 인터페이스의 구현체로 많이 사용됨!
-
LinkedList는 Queue 성질을 가지고 있는것이지 Queue만 구현한것이 아니다. 메소드 사용에 주의할것
주요 메소드
-
offer() → 삽입 , EnQueue
-
poll() → 삭제 , DeQueue
-
isEmpty()
-
size()
-
