1. 데이터 및 모듈 불러오기
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# data -> https://archive.ics.uci.edu/dataset/186/wine+quality
wine_red = pd.read_excel('C:\workspace\data\wine_red.xlsx')
wine_white = pd.read_excel('C:\workspace\data\wine_white.xlsx')
# 라벨이 따로 없는 데이터이기 때문에 생성
wine_red['label'] = 'red'
wine_white['label'] = 'white'
wine = pd.concat([wine_red,wine_white])
y = wine['label']
X = wine.drop('label',axis=1)
# data를 train, test로 나누어 train set로 모델을 훈련시킨 뒤 test set에 적용하여 모델 성능을 확인
train_input, test_input, train_target, test_target = train_test_split(
wine_data, wine_target, test_size=0.2, random_state=42)
# test 데이터는 전체의 20%로 설정2. 스케일링
모든 data의 범위가 다르기 때문에 수행한다.
ss = StandardScaler() #표준화 작업
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)3. Decision Tree로 분석
우선 아래의 그림의 두 데이터셋을 보면 위에 있는 데이터셋이 불순도가 낮다고 표현한다. 여기서 지니 계수는 불순도를 측정하는 지표로 지니 계수가 0에 가까울수록 불순도가 낮다는 의미를 갖는다. 또한 불순도 하이퍼파라미터로 'gini','entropy','log_loss'가 있지만 결정나무는 지니계수가 0에 가까워지도록 학습을 진행한다.
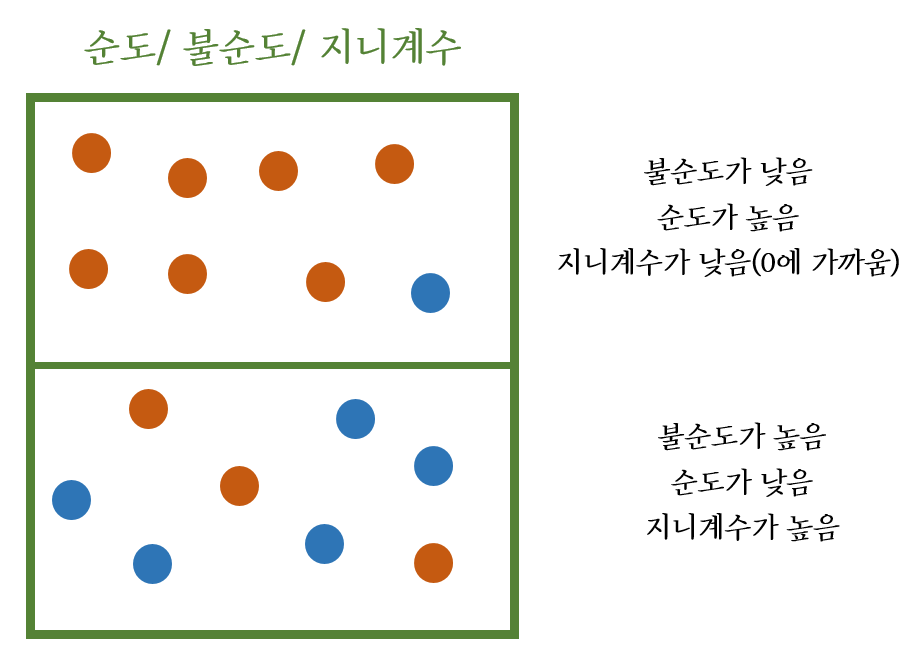
출처 : https://di-bigdata-study.tistory.com/2
1. 하이퍼파라미터 조정없이 분석
dt = DecisionTreeClassifier()
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target)) # 0.9976909755628247
print(dt.score(test_scaled,test_target)) # 0.9846153846153847
# accuracy_score로도 성능을 확인할 수 있다.
pred_target = dt.predict(test_scaled)
accuracy_score(pred_target, test_target) # 0.98461538461538472. 시각화
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(20,15))
plot_tree(dt,filled=True, feature_names = wine_data.columns)
plt.show()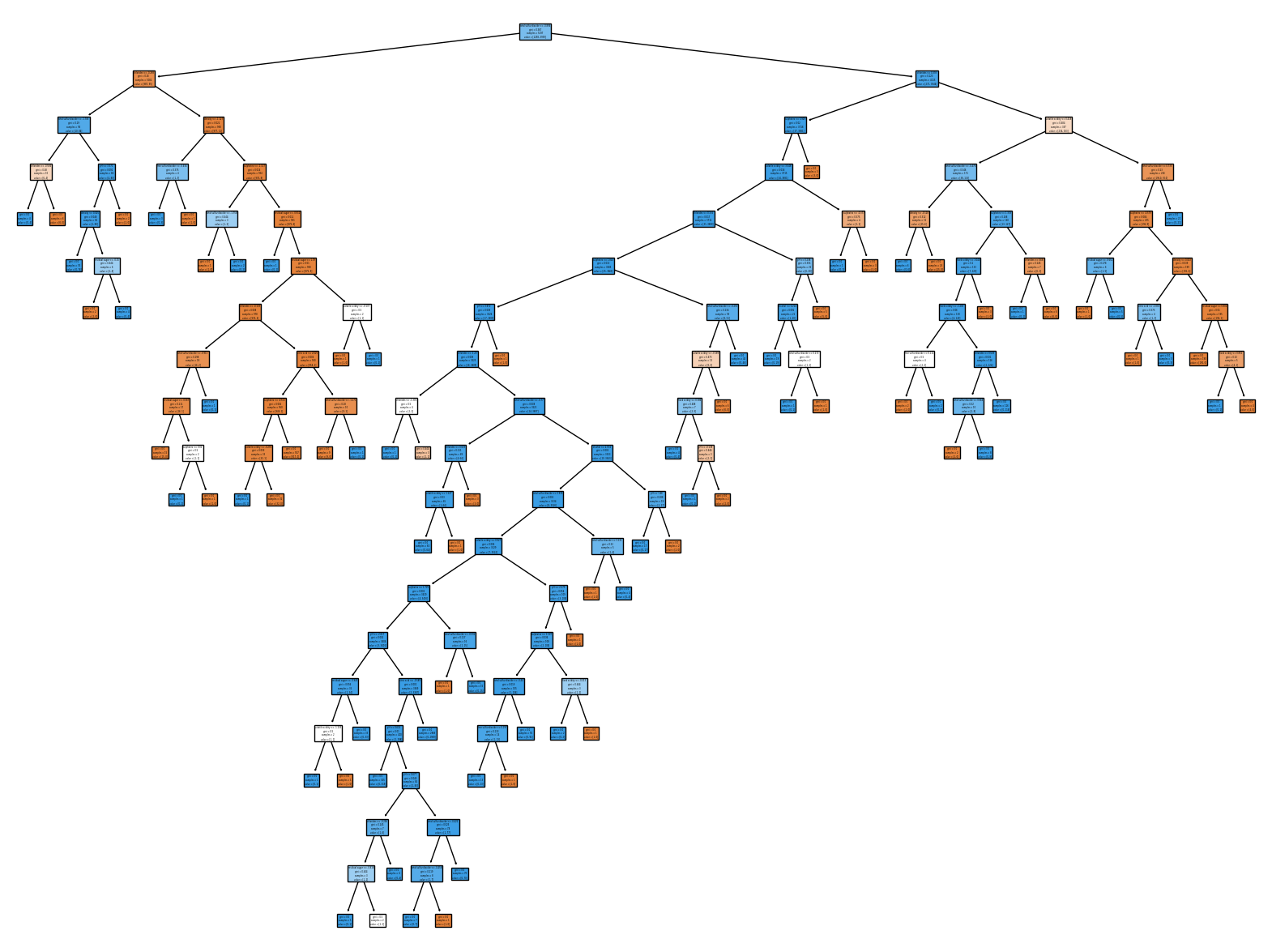
plt.figure(figsize=(10,7))
plot_tree(dt, max_depth=1, filled=True, feature_names = wine_data.columns)
plt.show()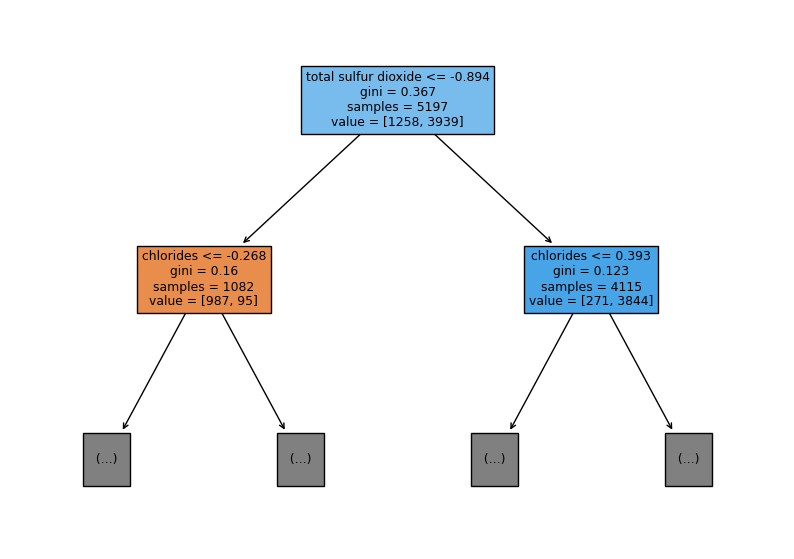
max_depth를 1로 하여 확대하여 보면 가지에 상세하게 정보가 적혀있는 것을 확인할 수 있다.
4. Grid Search CV
모델의 과대적합을 피하고 성능을 높이기 위해 파라미터를 조정하려한다.
1. 최적의 파라미터 탐색
from sklearn.model_selection import GridSearchCV
dt = DecisionTreeClassifier()
params = {'max_depth': range(1, 10)}
grid_dt = GridSearchCV(dt, param_grid=params, cv=5)
grid_dt.fit(X_train, y_train)
print('params', grid_dt.best_params_)
# params {'max_depth': 7, 'min_samples_leaf': 6}2. 파라미터 적용
final_dt = DecisionTreeClassifier(max_depth=grid_dt.best_params_['max_depth'], min_samples_leaf = grid_dt.best_params_['min_samples_leaf'])
final_dt.fit(X_train, y_train)
print('Train', final_dt.score(X_train, y_train)) #0.9896093900327112
print('test', final_dt.score(X_test, y_test)) # 0.98파라미터 조정으로 트레인 데이터에 과대적합되었던 것이 미세하게 완화된 것을 볼 수 있다.
3. 시각화
plt.figure(figsize=(20,15))
plot_tree(grid_dt, filled=True, feature_names = wine_data.columns)
plt.show()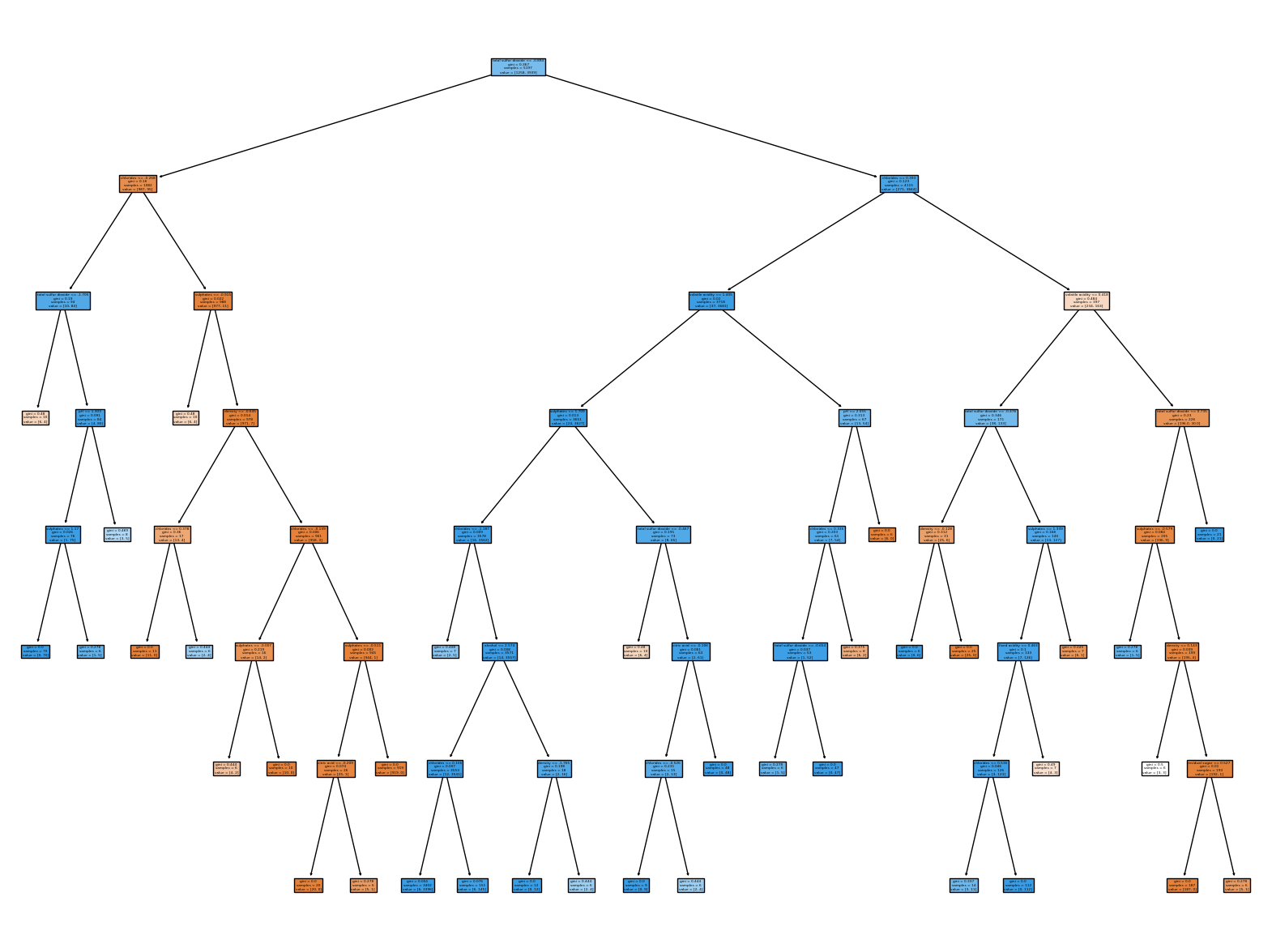

데이터분석공부중