sklearn으로 데이터 scaling하기
한빛미디어에서 나온 혼자 공부하는 머신러닝+딥러닝을 머신러닝 공부하는 데 참고하고 있다. 오늘은 데이터 전처리 과정 중 스케일링을 공부하였다. 스케일링을 하지 않은 데이터는 평균과 분산, 표준편차가 모두 제각각이므로 다른 통계 데이터와 비교하는 데에 있어 어려움이 있다. 스케일링 과정을 통하여 기준을 잡아 데이터를 계산한 후 분석을 시작해야 모델의 정확도가 상승한다.
데이터 불러오기
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
fish = pd.read_csv('http://bit.ly/fish_csv_data')
fish['Species'].unique()
# ['Bream', 'Roach', 'Whitefish', 'Parkki', 'Perch', 'Pike', 'Smelt']
# Bream : 도미, Smelt : 빙어
fish = fish[(fish['Species'] == 'Bream') | (fish['Species'] == 'Smelt')].reset_index(drop=True)
# 여기서 빙어와 도미 데이터만 사용
# 조건식으로 빙어와 도미만 추출하고 reset_index를 통해 인덱스를 초기화한다.
#drop=True를 넣으면 기존의 인덱스가 하나의 컬럼으로 생성되는 것이 아니고 자동 삭제된다.
fish_target = fish['Species'].to_numpy()
fish_data = fish[['Length','Weight']].to_numpy()
# 도미와 빙어의 길이와 무게 데이터만 사용하려고 한다.
#또한 스케일링 과정과 모델에 적용하기 위해서는 numpy값으로 바꿔줘야한다.
train_input, test_input, train_target, test_target = train_test_split(
fish_data, fish_target, stratify=fish_target)
# train data와 test data는 default값이 8:2이다.
# stratify은 fish_target에서 도미와 빙어의 비율을 그대로 유지하려할 때 필요하다.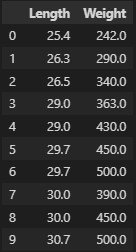
1. StandardScaler
standardscaler는 데이터의 평균을 0, 분산과 표준편차를 1로 만들어 표준화를 하는 방법이다. 하지만 표준화는 이상치가 존재할 경우 이상치가 평균과 분산, 표준편차에 영향을 주기 때문에 모델의 성능이 떨어질 수 있다는 단점이 있다. 이 경우 다른 스케일링 방법을 사용하거나 이상치를 제거해준 뒤 표준화 기법을 사용한다.

from sklearn.preprocessing import StandardScaler
sd= StandardScaler()
sd.fit(train_input,train_target)
sd_train = sd.transform(train_input)
sd_train = pd.DataFrame(sd_train,columns = [['Length','Weight']])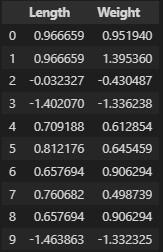
표준화 과정을 거친 뒤에 모든 데이터의 값이 변화하였다.
2. MinMaxScaler
minmaxscaler는 데이터들이 0과 1사이의 값을 갖도록 하는 방법이다. 최솟값은 0, 최대값은 1이 되고 그 사이의 값들은 선형적으로 비례하게 스케일링 된다. 이 기법은 이상치에도 민감하지 않아, 이상치가 포함된 데이터셋에서도 잘 작동한다.
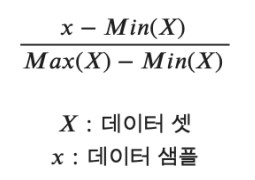
from sklearn.preprocessing import MinMaxScaler
mm = MinMaxScaler()
mm.fit(train_input,train_target)
mm_train = sd.transform(train_input)
mm_train = pd.DataFrame(mm_train,columns = [['Length','Weight']])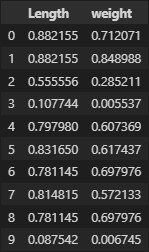
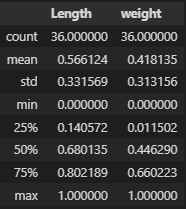
정규화 과정을 거친 뒤 모든 데이터의 값이 0~1 사이의 값으로 변화하였다.
3. MaxAbsScaler
maxabsscaler는 데이터들의 절댓값이 0과 1사이에 놓이도록 한다. 즉 -1부터 1사이의 값을 갖는다.
from sklearn.preprocessing import MaxAbsScaler
ma = MaxAbsScaler()
ma.fit(train_input,train_target)
ma_train = max.transform(train_input)
ma_train = pd.DataFrame(ma_train,columns=[['Lenght','Weight']])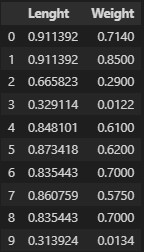
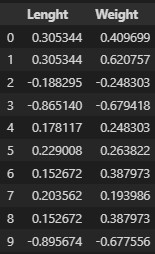
길이와 무게는 모두 양수이기 때문에 데이터 값이 모두 양수이다.
4. RobustScaler
robustscaler는 중간값과 사분위값을 사용하고, 이상치의 영향을 최소화할 수 있다.
from sklearn.preprocessing import RobustScaler
robust = RobustScaler()
robust.fit(train_input,train_target)
robust_train = robust.transform(train_input)
robust_train = pd.DataFrame(robust_train,columns=[['Lenght','Weight']])