Was 서버가 데이터가 어떤노드에 있는지 찾아야했었는데, yarn이라는 Resource manager가 interface를 제공하면서, 데이터의 locality가 증가함으로서 찾는 시간이 줄어든다.
또한 yarn을 통해 hdfs 작업 이외에도 다른 작업들을 할 수 있다. 남는 resource들 있다면, was를 띄어서 다른 작업을 하는 것이 아닌 노드 자체에 띄운다. was를 띄우면 네트워크 비용 및 서버를 띄워야 한다.
그래서 hadoop v2에서는 yarn을 사용하는 맵리듀스이고, yarn이 인터페이스를 제공해주면, 어떤 형태의 작업이든 분산처리를 할 수 있고 그것이 hdfs내의 파일 자원을 사용한다면 locality를 높여서 내가 하는 작업이 내가 필요한 데이터가 있는 곳에서 작업하는 가능성이 높여준다. 네트워크 비용이 들지 않기에 데이터를 io하는데 훨씬 빠르다. was를 쓰면 데이터가 어디에있는지 찾아야했는데 yarn이 알아서 해주니까, 남는 자원도 동적으로 사용할 수 있고 hdfs내의 locality를 높이는 작업을 쉽게 사용할 수 있다.
HDFS Design Goal
2.1.1 Hardware Failure
HDFS를 구성하는 분산 서버에는 다양한 장애가 발생할 수 있다. 예를 들면 하드디스크에 오류가 생겨서 데이터 저장에 실패하는 경우, 디스크 복구가 불가능해 데이터가 유실되는 경우, 네트워크 장애가 생겨 특정 분산 서버에 네트워크 접근이 안되는 경우 등이 있다.HDFS는 이런 장애를 빠른 시간에 감지하고 대처할 수 있게 설계되어있다. HDFS에 데이터를 저장하면, 복제본도 함께 저장되어 데이터 유실을 방지한다. 분산 서버 사이에는 주기적으로 health check 를 통해 빠른 시간에 장애를 감지하고 대처할 수 있게 됩니다.
2.1.2 Streaming Data Access
HDFS는 클라이언트의 요청을 빠르게 처리하는 것보다 동일한 시간 내에 더 많은 데이터를 처리하는 것을 목표로 한다. HDFS는 이것을 위해 Random Access 를 고려하지 않는다. user와 상호작용하는 것보다는 batch 처리에 더 맞게 디자인 되어있다. 따라서 은행 서비스, 쇼핑몰과 같은 trasnactional 서비스에서 기존 파일시스템 대신 HDFS 를 쓰는 것은 적합하지 않다. HDFS는 Random Access 대신 Streaming 방식으로 데이터를 접근하도록 설계되어 있다. Client 는 HDFS 명령어/API를 통해서 연속된 흐름(streaming)으로 데이터에 접근할 수 있다.
2.1.3 Large Data Sets
HDFS는 하나의 파일이 GB ~ TB 수준의 데이터 크기로 저장될 수 있게 설계되었다. 이것으로 높은 데이터 전송 대역폭(bandwidth)를 지원하고 하나의 클러스터에서 수백대의 노드를 구성할 수 있다. 하나의 인스턴스에서는 수백만개(tens of million) 이상의 파일을 지원한다.
2.1.4 Simple Coherency Model
데이터베이스에서 데이터의 무결성은, 데이터의 입력이나 변경을 제한해서 데이터의 안정성을 깨는 동작을 막는 것을 의미한다.HDFS는 write-once-read-many access model 이 필요하다. HDFS에서는 한 번 저장한 데이터는 수정할 수 없
고, 읽기만 가능하게 무결성을 지킨다. 데이터 수정은 불가능하지만, 파일의 이동, 삭제, 복사는 지원한다. 최초에는 수정이 안되었지만, 현재는 end of file 위치에 append 가 가능하다.이런 Simple Data Coherency Model 은 데이터 접근에 대한 높은 throughput 을 가능하게 한다. 이 방식은
MapReduce 에서 큰 장점을 발휘한다.
2.1.5 Moving Computation is Cheaper than Moving Data
데이터를 이용해서 computing processing 을 한다면, 데이터가 processor와 가까울 수록 효율이 좋다. 데이터의 양이 클수록 이 영향이 크다. Network 혼잡을 줄이고 시스템 전체의 throughput 을 높일 수 있다.
HDFS는 이것을 위해 computing 자원을 data가 있는 위치로 이동시키는 것을 선택한다. Data를 이동시키는 것보다 비용이 싸고 빠르기 때문이다. HDFS는 이러한 방식을 위한 인터페이스를 제공한다.
-> job 자체를 필요 데이터가 있는 노드에 제공
2.1.6 Portability Across Heterogeneous Hardware and Software Platforms HDFS는 쉽게 HW/SW 플랫폼을 옮길 수 있도록 디자인 되었다. 인텔 칩, AMD칩이 설치된 하드웨어에서 동일한 기능으로 동작한다. CentOS나 Redhat LInux 상관없이 동일하게 동작한다. HDFS의 서버의 코드가 Java로 구현되어있기 때문에 가능하다. 대용량 데이터 셋의 플랫폼으로 채택되는 주요한 이유중 하나이다.
Block system의 장점
2.2.1 Block based file system 이란?
HDFS는 블록 구조의 파일 시스템이다. HDFS에 저장되는 모든 파일은 일정 크기의 블록으로 나눠져서 여러 서버에 분산되어 저장된다. 블록 크기는 기본 128MB로 되어있고, 설정으로 변경이 가능하다. 블록단위로 분산해서 저장하기 때문에 로컬 디스크보다 큰 규모의 데이터를 저장할 수 있고, 저장할 수 있는 용량을 페타바이트 단위까지 확장할 수 있다.
2.2.2 파일과 Block
-
하나의 파일은 하나 또는 복수의 block 에 저장된다. 이때 어떤 파일이 어느 블록에 저장되어있는지는 메타데이터로 namenode가 메모리에서 관리한다.
-
복수의 파일이 하나의 block에 저장될 수 없다.
-
하나의 File의 사이즈가 block size 를 넘어가면, 여러개의 블록에 나누어 저장된다.
- a. 예 1) 하나의 파일 사이즈가 128MB+10bytes 라면, 128MB 블록 하 나, 10bytes 블록 하나에 나뉘어 저장된다.
- 하나의 File 사이즈 또는 하나의 블록 사이즈를 초과하는 크기의 하나의 파일이 블록 사이즈로 딱 나누어떨어지지 않아서 남은 사이즈가 하나의 블록 사이즈보다 작다면, 해당 블록은 그 크기만큼 점유한 블록으로 관리된다.
- a. 예 1) 하나의 파일이 1MB이고 블록사이즈가 128MB라면, 128MB 블록 하나에 할당되어 1MB만 저장된다.
- b. 예 2) 하나의 파일이 129MB이고 블록 사이즈가 128MB라면, 해당 파일은 128MB 블록 한개, 1MB 블록 한개에 구성된다.
- 실제 디스크를 점유하는 공간은 블록 내에 파일이 차지하는 크기이다.
a. 예) 블록 사이즈 128MB이고, 할당된 파일의 사이즈가 1MB 이라면, 실제 디스크 사용량은 1MB이다.
2.2.3 Block system의 장점
Block 크기를 적당한 수준(64MB, 128MB) 으로 고정해서 얻을 수 있는 장점은 다음과 같다.
-
Disk Seek time 감소
디스크 탐색 시간 = seek time (데이터의 위치) + search time (데이터의 섹터에 도달). 하둡 개발 당시의 일반적인 HDD의 disk seek time은 10ms, disk I/O bandwidth 는 100MB/s 였다. HDFS는 seek time 이
bandwidth 의 1% 사용하는 것을 목표로 했다. 따라서 100MB를 넘지않고 2^n 으로 가까운 64MB 를 선택했다. (Hadoop v1 은 64MB였다.) -
Metadata size 감소
namenode 는 블록 위치, 파일명, 디렉토리 구조, 권한 정보 등의 메타데이터 정보를 메모리에서 관리한다. 예를 들어 블록 사이즈가 128MB이라면, 200MB의 파일에 대해 2개 블록에 해당하는 메타데이터만 저장하면 된다. 하지만 일반적인 파일시스템은 블록(page) 크기가 4k~8k이기 때문에 동일한 크기의 파일을 저장할 경우 훨씬 많은 메타데이터가 생성된다. 200MB의 파일에 대해서 만약 블록 크기가 4k 이라면, 5만개의 블록이 생성되고 메타데이터 또한 5만개 분을 하나의 namenode에서 관리해야한다. namenode는 모든 메타데이터를 관리하는 단일 서버이므로 이렇게 메타데이터의 양이 늘어나는 것은 성능과 HDFS 안정성에 심각한 영향을 미친다. namenode는 일반적으로 100만개 블록을 저장할 경우, 1GB의 heap memory를 사용한다. -
Communication cost between Client and NameNode클라이언트는 HDFS에 저장된 파일을 접근할 때, namenode에 먼저 해당 파일을 구성하는 데이터 블록의 위치를 조회한다. 데이터 블록이 작아서 그 갯수가 많다면, 이 조회에서 필요한 데이터가 많아지거나 조회 횟수가 증가할 것이다. 클라이언트는 스트리밍 방식으로 데이터를 읽고 쓰기 때문에 특별한 경우를 제외하면 namenode 와 통신할 필요가 없다.
Architecture
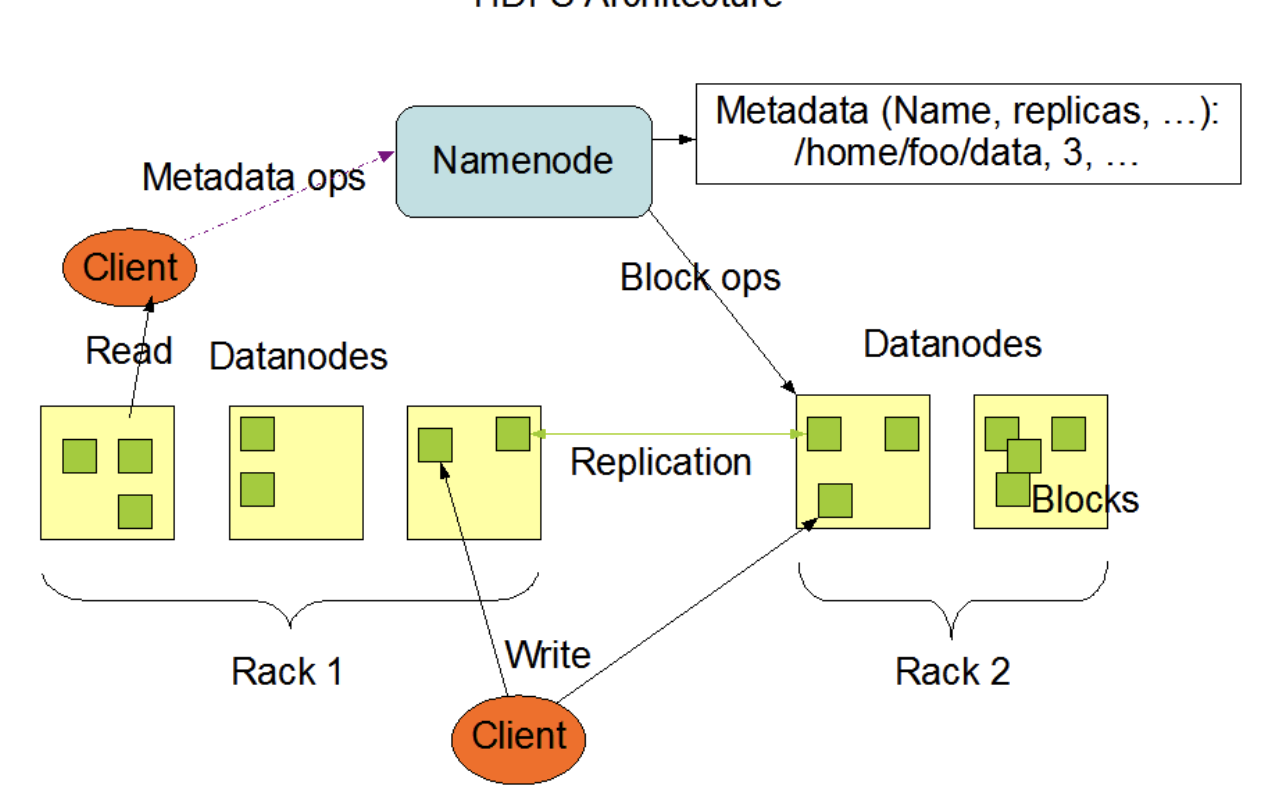
각 서버 Rack 당 복수의 노드들로 이루어져 있다. Rack은 뒤에서 다루지만 여러개의 서버가 안정적으로 한 장치에 모여있는 것이다. Rack 하나가 문제가 생기면 내부의 서버들이 다 다운되기 때문에 (현재는 가용영역) 복제해서 둔다.
client는 Namenode,Datanodes와 통신, Namenode는 Datanode와 통신, 데이터 노드끼리도 서로 통신하며 하는 작업이 있다.
네임 노드는 metadata 관리 file size auth 등 + block에 대한 Mapping 정보를 포함한다. ex) file1 == dn_block_a + dn_block_b
모든 update는 namenode가 관리한다. 네임노드는 데이터 노드와 정보를 고유하며, 클러스터 내의 데이터노드들에 대한 정보를 가지고 있다. 모니터링도 하기에, 데이터 노드 하나가 다운이 되면, 해당 정보를 다른 노드에 복사를 한다(?)
또한 데이터 노드는 네임 노드에게 heartbeat 신호(기능이 정상이다)를 보내고, block report를 보낸다. 블록에 대한 모든 정보를 보낸다.
Namenode는 자기 자신에대한 변경사항을 2가지로 기록한다.
1) FS Image - file system에 대한 이미지 즉 스냅샷이다.
2) 모든 오퍼레이션 마다 Image를 남길 수는 없다. (큰 작업이기에) 스냅샷이 남겨진 후 추가적인 변경은 Edit Log로 정보를 저장한다.
Client로부터 request가 들어오면 언제나 namenode에 먼저 접속한다.
Namenode는 항상 메모리에 상주한다. 왜냐하면 데이터 노드도 여러개고 client도 여러명이기 때문이다. 응답을 빨리빨리하려면 file이 아닌 메모리
2.3.3 Data Node
데이터노드는 클라이언트가 HDFS에 저장하는 파일을 디스크에 유지한다. 저장하는 파일은 크게 두 종류이다.
1) 실제 데이터인 로우(raw) 데이터
2) raw 데이터를 검증하는 chekcsum, created time 등 메타데이터가 설정된 파일
DataNode의 기능
1. client 로부터 실제데이터의 read/write request 를 받아 처리한다.(read write는 실제로 데이터 노드에서 이루어진다.)
2. Name Node로부터 명령을 받아서 자신의 디스크에 있는 block을 생성, 복제, 삭제를 수행한다.
3. HDFS 의 상태를 Name Node에게 heart beat 로 보낸다.
4. 자신이 가진 block들의 리스트와 상태를 Name Node 에게 보낸다.
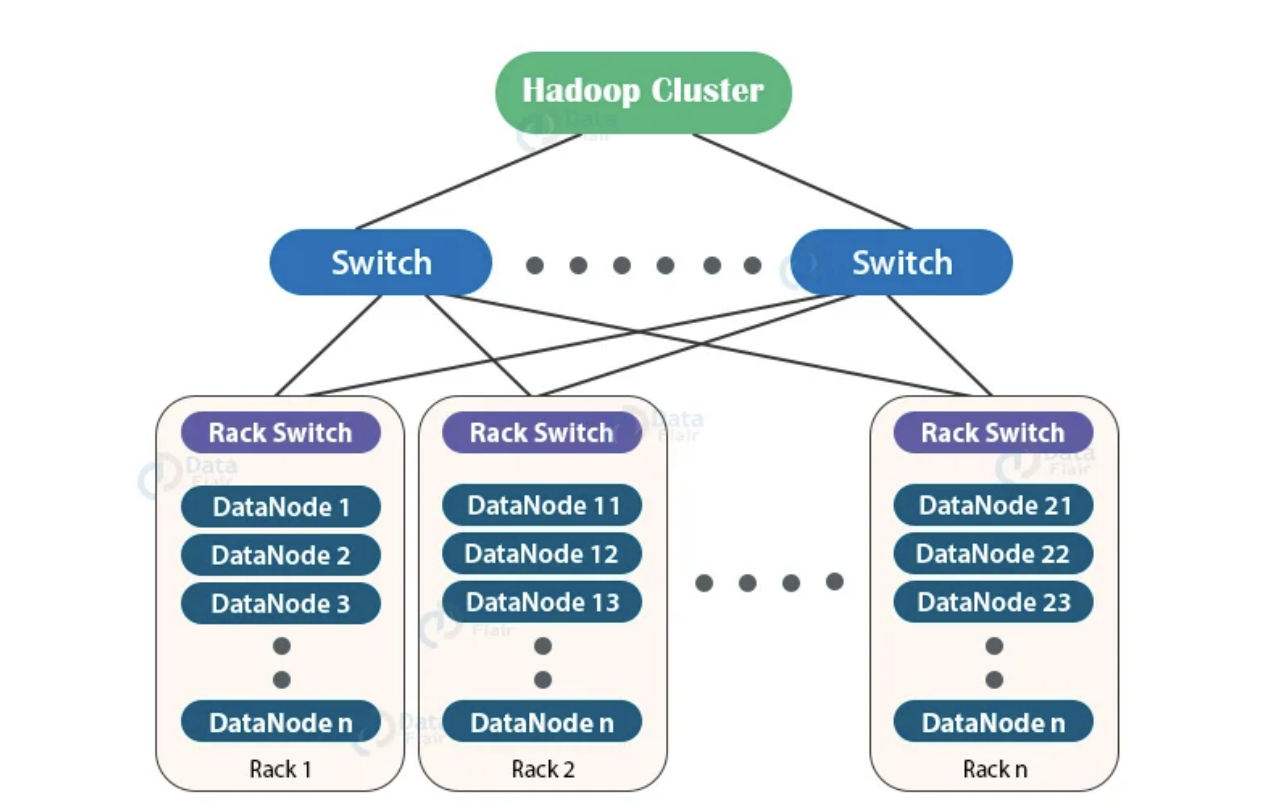
위는 물리적인 그림이다.
지금은 잘 사용하지 않지만 Rack에는 하드웨어를 잘 유지하기 위한 전원장치, 네트워크장치가 있다. rack switch에는 해당 rack 내의 데이터 노드들의 ip 및 정보를 가지고 있다. rack switch는 switch에 응답을 routing한다.
여기서 Rack awareness는 무엇이냐? 하둡 클러스터가 rack 정보를 알고 있다는 것이다.
같은 Rack 내의 데이터 노드끼리의 통신은 네트워크 비용은 거의 들지 않는다.(osi layer L2라고 하는데 이건 찾아봐야할듯) 만약 node1이 node11과 통신하고 싶다면 rack switch - switch - rack switch 를 통해서 node 11로 접근할 수 있다. switch를 거치기 때문에 물리적으로 더 오래걸린다.
만약 replica가 같은 rack에 있다면 fault tolerance를 대응하지 못한다. 그래서 하둡 클러스터는 물리적으로 구분된 다른 rack에 replica를 저장하게 한다. 단점은 네트워크를 타기에 성능은 안좋아질 수 있다. 이렇게 나누게 되면, rack 내의 노드는 다른 rack에 복제본이 있는 것이 보장되기 때문에 전체적으로 데이터가 고르게 분산된다. 부하가 편중되서 side effect가 생기는 우려는 완화될 수 있다. load balance를 하는 rack awareness를 하면 부하분산의 효과도 얻을 수 있다.(cloud는 AZ 가용영역)
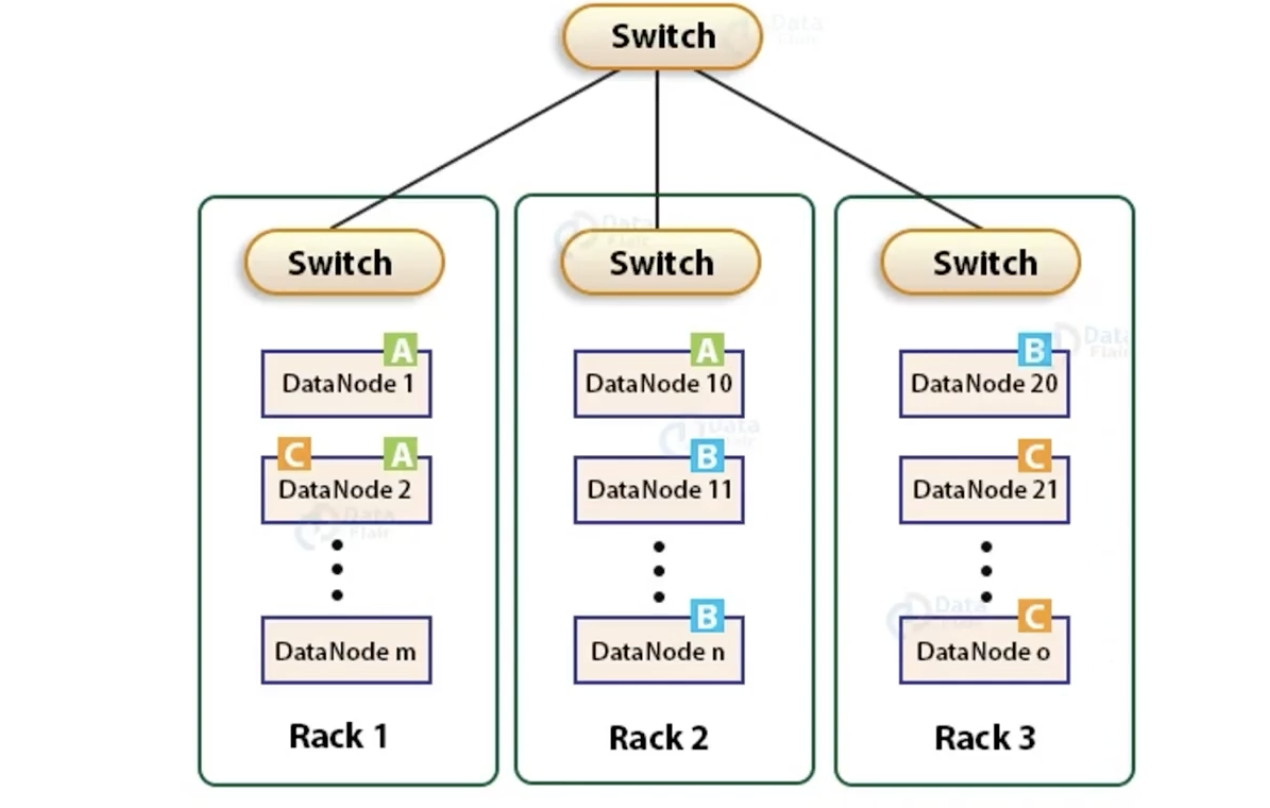
rack2에 데이터를 write하고 Replica를 생성할 때 1,3에 나눠서하면 좋겠지만 기본정책은 다르다. dn1에 복사 후, 같은 rack내의 다른 노드에 복제한다.
여기서 rack 2개가 나가면, 데이터가 유실되는 것이 맞다. 이렇게 기본정책이 설립된 이유는 rack awareness에 의해서 다른 rack에 존재하면 네트워크 비용이 드는 단점이 있기 때문이다(성능). write 성능을 조금 더 높일 수 있다.
여기서는 가정이 들어가는데, rack의 고장 확률 < 노드 하나의 고장 확률로 가정하기에, data reliability 측면에서 영향이 별로 없다. 이 가정을 기반으로 write 성능을 높이기 위해 Replica factor가 3일때 rack 2개에 저장한다.
여기서는 단점도 있다. 1:1:1 보다 2:1로 할 때 더 편중이 생길 수 있다. 왜냐하면 블록의 단위는 같더라도 파일의 단위는 다르기 때문이다. 그리고 1:1:1보다 네트워크 bandwith를 크게 줄이지는 못한다. 왜냐하면 node 10 -> node1, node 10 -> node 2 로 복제하기 때문이다.
만약 replication factor 가 3보다 크다면 4번 째 replica 는 다음 정책을 따른다.
1. 다음 복제본은 랙당 복제본 수를 상한선 보다 낮게 유지하면서 무작위로 결정된다.
a. 상한선 = (replicas - 1) / racks +2 (rack 내의 최대 수)
namenode 는 기본적으로 하나의 datanode 가 같은 블록에 대해서 여러개의 replica 를 갖는것을 허용하지 않는다. 따라서 하나의 블록이 가질 수 있는 최대 replica 수는 총 datanode 수와 같다.
2.4.5 Replica Selection - Read
글로벌 bandwidth 소비를 줄이고, read latency 를 줄이기 위해서 HDFS는 read 요청에 대해서 reader 와 가까운곳에 있는 replica 로부터 데이터를 읽도록 시도한다. reader node 와 같은 rack 에 replica 가 존재한다면, 해당read 요청은 그 replica 에서 데이터를 읽는다. 만약 HDFS 클러스터가 여러 데이터센터에 걸쳐져 있다면, 같은 데이터센터에 있는 replica 를 읽는 것을 선호한다. -> 블록 내의 데이터는 바뀌지 않기 때문에, 가까운 것을 읽어도 상관없다.
2.4.6 Safemode
namenode 가 최초로 기동될 때 namenode 는 Safemode 라는 특별한 상태에 들어간다. 이 Safemode 에서는 replication 이 발생하지 않는다.
Datanode 로부터 받은 blockreport 의 내용을 종합해서 모든 블럭에 대한 replication 이 일정 수준(%)을 넘어서 잘 구성되어있다면, 그 때 이 Safemode 에서 빠져나온다. 이 % 값은 변경이 가능하다. Safemode 에서 빠져나온 뒤에, 모자란 replication factor가 있는 블록이 있다면 복제를 수행한다.
File read & write
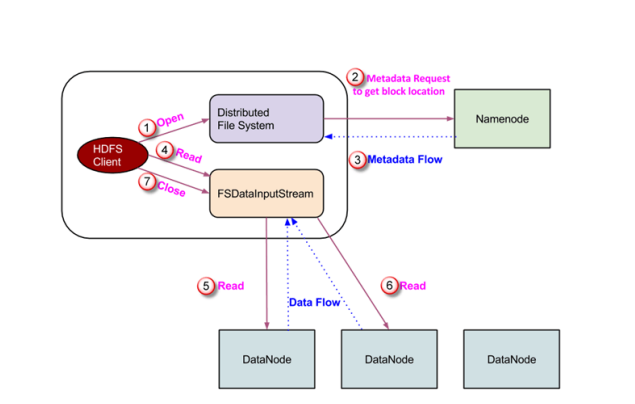
read
- open
- file system 객체에서 namenode에게 실제 파일이 존재하는지에 대한 여부, 어떤 블록으로 저장되어 있는지에 대한 여부, meatadata flow(어떤 데이터 노드가 replica를 가지고 있는지)를 응답으로 제공
- FSDataInputStream 객체 생성 DFS , FSData 객체 내에서 DFSData 객체를 만드는데, 생성된 객체는 datanode와 namenode와 상호작용한다.
- 받은 블록 정보를 통해서 객체가 생성된 가장 가까운 locality를 높이는 복제본 혹은 블록을 반환한다.
같은 rack 혹은 같은 data center. FSD JVM이 rack b에 있다 그럼 Rack b를 선택.
데이터는 여러개의 블록으로 나누어져있다. 하둡은 stream으로 형태로 read를 통해서 return 된다. read과정은 end of block이 되면 다른 데이터 노드의 블록에 접속에서 또 read를 수행한다. 해당 파일의 모든 node를 읽을 때까지 수행한다.
- end of block 에 도달하면, DFSInputStream은 datanode 와의 연결을 끊고, 해당 파일의 다음 블록이 위치한
데이터 노드와 연결을 맺는다. 이 과정은 해당 파일의 모든 블록을 읽을 때까지 계속된다. - read 과정이 끝나면 client 는 close() 로 모든 연결과 스트림을 닫고 끝낸다.

write
- write를 한다고 하면 create 호출로 Distributed file system 객체 생성
- namenode에 가서 생성하기 전 verfication을 거침 (존재여부, auth) 실패하면 IOexception
검증이 되면 파일에 대해 record. FSDataOutputStream 생성후 안에 DFSoutput 객체 생성.
해당 객체는 네임 노드와 데이터 노드와 상호작용. 해당 데이터는 패킷 형태로 만들어짐. - 데이터 패킷은 data queue 형태로 저장. 데이터 streamer는 어떤 노드에 저장해야하는지 namenode와 통신
- 패킷을 보내기전 replica를 위해 데이터 노드에 파이프라인 먼저 생성.
- 먼저 작성된 data node로 부터 다른 노드로 foward 형식으로 전달. 노드에 replica가 복사 되면 ack queue에 저장을 다했다고 전달.
- ack queue에 다 전달 되면 삭제되면서 write 완료. 만약 복제본이 3개 중 2개만 큐에 도착했다면, 해당 복제본 다시 복사. ack queue는 파일마다 따로 존재한다.
- 완료되면 close 함수를 호출하는데 data queue에 패킷이 남았다면, flush 하고 graceful하게 종료된다. 마지막으로 namenode에 매핑정보를 저장한다.
