HDFS NameNode HA(high availability)
Hadoop v1.x 버전 까지는 namenode 는 SPOF(single point of failure)였다. Hadoop 의 기본 아키텍처는 namenode를 master, datanode 들을 slave 로 하는 master-slave 구조이다. 이 중 namenode 는 하나의 인스턴스, datanode 는 수평적 확장이 가능했으므로 namenode는 bottleneck 이 되기 쉬웠다. namenode 가 이용 불가능한 상태라면, datanode가 아무리 많더라도 클러스터 전체가 이용 불가능해진다. 초기 버전에서는 namenode의 데이터 유실을 방지하는 secondary namenode 가 있었지만 Availability 문제를 완전히 해결하지는 못했다. 이러한 상태라면 예상치 못한 장애 뿐만 아니라, 계획된 업그레이드나 업데이트를 위해서 downtime 이 발생할 수 밖에 없었다.
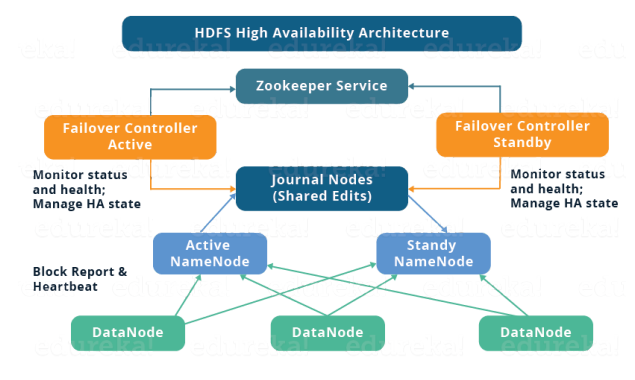
acitve 다운시 standby로 교체. downtime을 최소하고 active namenode를 만듬으로서, 고가용성을 유지한다. perfect는 아님. active는 standby에 항상 sync 되어야한다. 즉 backup의 기능도 한다.
이러한 HA Cluster 에서 consistency 를 유지하기 위해서는 두 가지 이슈가 있다.
1. Active Standby namenode 는 항상 서로 sync 되어야 한다.
2. 한 순간에 단 하나의 active namenode만 존재해야 한다. 만약 잠깐이라도 두 개의 active namenode 인 상태가 된다면, 서로 다른 active 데이터 상태를 가져서 데이터 충돌이 일어날 수 있다. (split-brain) 이것을 막기 위해서 Fencing 과정을 가진다.
간단하게 down 되고 up된 상태에서 txn의 상태가 달라질 수 있다
Active Standby namenode 설정을 하는 방법으로 두 가지의 선택지가 있다.
1. Quorum Journal Nodes 를 사용
2. NFS를 이용한 shared storage 를 사용
Quorum Journal Nodes를 이용한 HA Archi
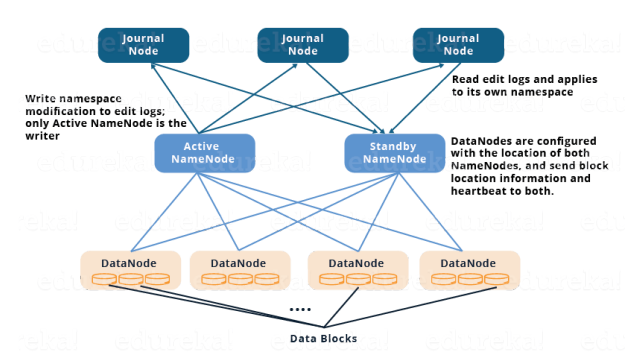
구성요소는 active namenode 복수개의 journal node로 이루어져있다. journal node는 3개이상의 홀수개로 이루어져있다. Quorum을 만족해야하기 때문에. Journal node는 node로 띄울 수도 있고, Active namenode와 같은 머신에 둘 수도 있다. 프로세스만 다른 데몬프로세스로 사용할 수 있다. 가볍고 리소스 사용이 적기 때문이다. journal node는 링포톨로지로 연결되어 있다.
- request 1이 active -> journal1에 오면 request를 journal node 2,3으로 보낸다

링형태로 전달한다. journal node끼리 request를 복제해서 링연결로 가지고 있기 때문에, fault tolerance를 유지한다.
request는 active namenode는 변경사항을 fsimange와 editlog 두개가 있다, 그 중에 editlog를 request로 보낸다. standby는 active에게 받는 것이 아니라 Journal node를 통해서 sync 받는다.
active가 다운되면, standby는 journal로부터 sync를 받고 active로 전환한다.
데이터 노드는 애초에 active와 standby를 모두 다 가지고 있고, heartbeat과 block report를 보내기 때문에 2개의 namenode는 이미 정보를 가지고 있다.
데이터 노드는 위의 2가지 신호를 미리 보내고 있기 때문에 failover가 발생해도 빠르게 처리할 수 있다.
그러면 데이터 노드가 신호를 2번 보내기에 시간이 오래걸리지 않나? 라고 생각할 수 있지만 heartbeat과 block report같은 경우는 가볍기에 상관없다.
fencing 문제는 journal node에 작성하는 name node를 한순간에 하나만 쓸 수 있도록 보장함으로서 해결한다.
Shared Storage를 이용한 HA Architecture
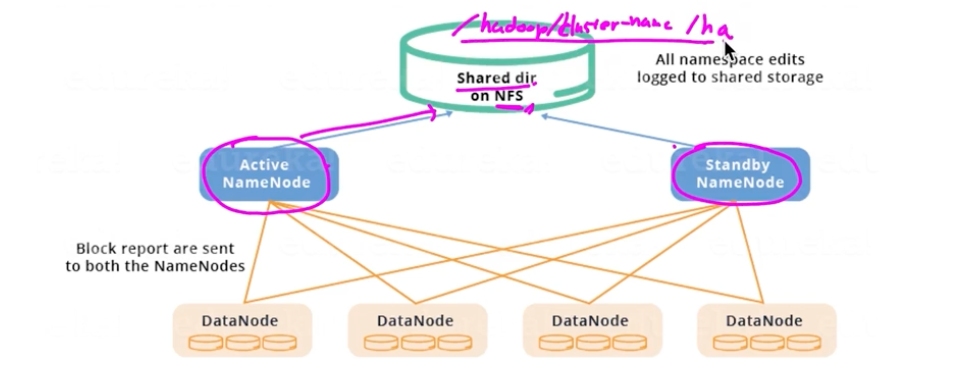
디렉토리를 하나 만들어서 모든 sync를 저장한다. editlog를 기록하는 것이다. standby는 editlog를 읽어서 sync를 한다.
active가 down 즉 failover가 된다면, 해당 최근 내용까지 standby에서 sync 되고 active로 전환.
shared storage에서는 fencing을 위한 1가지를 설정해야함. 보통 access의 권한을 해제 시켜버린다. 그런데 NFS를 어떤 것을 쓰느냐, 어디까지 보장해주느냐에 따라 dependency가 달라진다고 한다. 강사는 본적이 없다고 하네여.
Split-brain을 방지하기 위해 관리자는 최소한 하나의 fencing 방법을 설정해야 한다.
다양한 fencing 메커니즘을 사용할 수 있다. 여기에는 namenode의 프로세스를 삭제하고 공유 스토리지 디렉토리에 대한 액세스를 취소하는 작업 등이 있을 수 있다. 마지막 수단으로, 우리는 이전에 active namenode 에 STONITH로 split brain을 방지할 수 있다. (STONITH “shoot the other node in the head") 특수 전원 공급 분배기롤 namenode 머신을 강제로 끄는 방법이다.
Automatic Failover
Active를 Standby로 누가 바꿔줄까?
Failover 는 시스템의 failure 나 fault 를 감지하고 secondary system 에대한 조작을 자동으로 수행하는 동작을 말한다. Failover 에는 다음 두가지 방식이 있다.
- Graceful Failover: 직접 failover 과정을 진행한다. 주로 유지보수 과정에서 필요한경우 계획하고 의도적으로 실행한다.
- Automatic Failover: 예상치 못한 namenode장애에 의해 자동으로 수행된다.
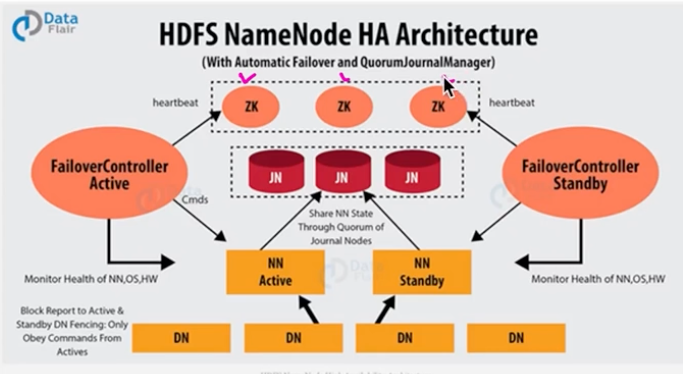
위의 그림은 Journal node를 이용해서 만든 HA이다.
Zookeeper는 분산 코디네이터다. 적은 양의 데이터, 보통 메타데이터의 종류에 대해서 분산된 주키퍼 클러스터에서 상태를 일관되게 관리해주고, 연결된 클라이언트에게 변경되면 이벤트도 보내주고 하는 역할이다.
여기서 주키퍼는 failover controller와 같이 동작해서, 네임노드에 장애가 발생하면 그것을 감지하고 standby 중에 누구를 active로 전환할 것인가를 결정한다.
ZK Failove controller는 네임노드와 같은 머신에 있다. failover controller는 주키퍼 서버에 대한 클라이언트다. 주키퍼 서버한테 네임노드들의 상태를 관리하는 네임 스페이스를 바라보고 있고, 거기있는 데이터를 통해서 어떤 친구가 active 고 standby인지를 확인한다. ZKFC는 NN에게 명령을 날려서 지속적으로 체크를 한다. 정상이라면 zk에 반영한다.
만약 active NN이 문제가 생겼다면, 모든 NN에는 ZKFC가 있기 때문에 주키퍼 서버를 통해 sync 받고 해당 standby는 active가 된다. 한 standby node에 대한 health of namenode os hardware의 상태를 확인하고 standby를 active할지 결정했으면 state에 대한 lock을 걸고 다른 standby node가 active가 될 준비를 하지못하게 한다.
Observer Name Node(ONN)으로 부하 분산하기
