hadoop & spark
1.Hadoop & spark 1

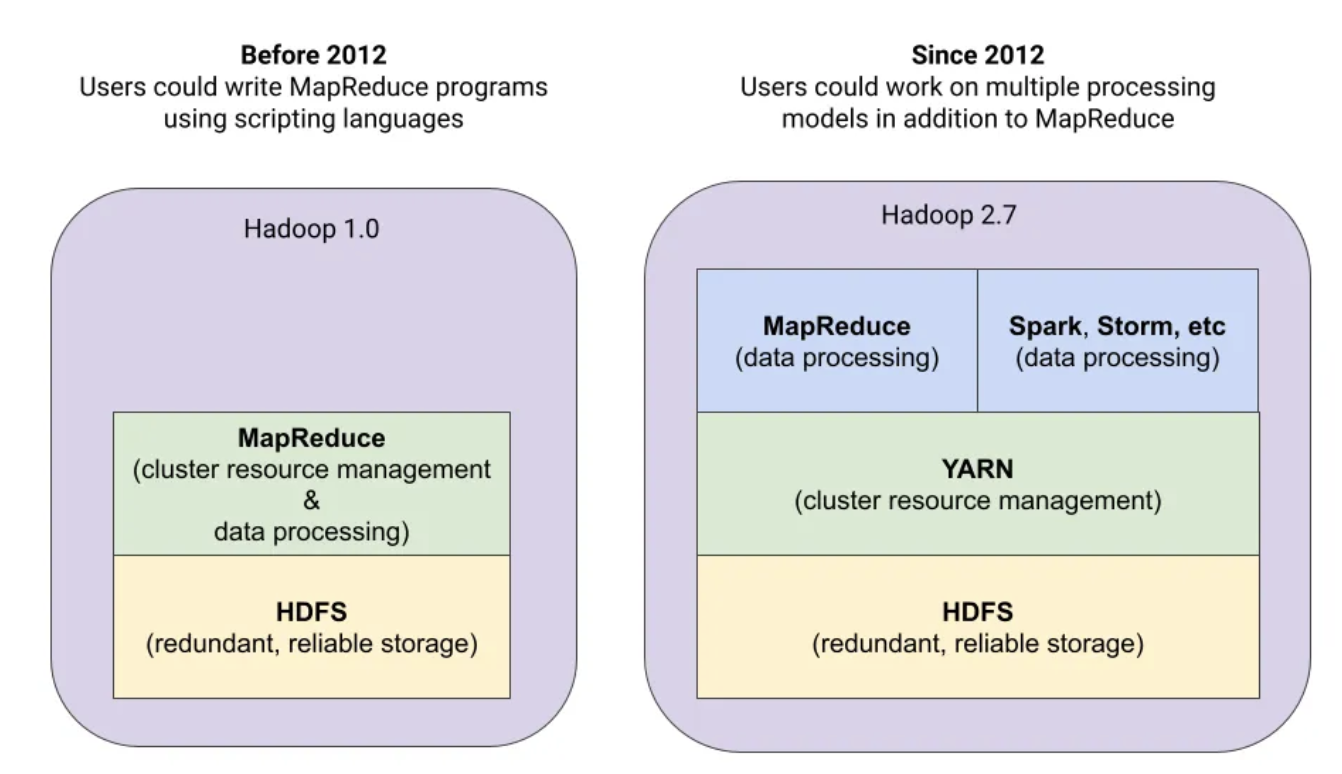
Hortonworks의 정의대용량 데이터를 commodity hardware에 분산 처리 하는 방법, 두 가지 component가 있다.HDFS : distributed file systemMapreduce : distributed processing다수의 노드로 구성
2.Spark 프로그래밍 : DataFrame

1.Spark 데이터 처리의 기본이 되는 파티션에 대해 알아보자 Spark 데이터 시스템 아키텍쳐 spark 같은 경우 분산 파일 시스템이 없다. 우리는 HDFS,S3,Azure Blob, GCP cloud Storage와 같은 분산 파일 시스템 위에서 사용한다. 이
3.YARN 정리
YARN(Yet Another Resource Negotiator)은 Hadoop 생태계의 중요한 구성 요소입니다. Hadoop 클러스터에서 실행되는 분산 애플리케이션에 대한 CPU, 메모리, 스토리지와 같은 리소스를 관리하고 할당하는 역할을 하는 클러스터 리소스 관리
4.SparkSQL
하지만 SQL로 가능한 작업이라면 DataFrame을 사용할 이유가 없음.두 개를 동시에 사용할 수 있다는 점 분명히 기억Familiarity/Readabilitysql이 가독성이 더 좋고 더 많은 사람들이 사용가능optimizationsparkSQL 엔진이 최적화하기
5.Spark
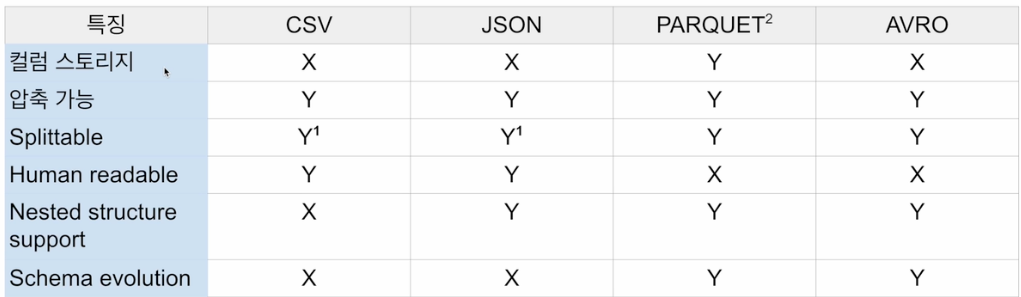
데이터는 디스크에 파일로 저장됨: 일에 맞게 최적화 필요Unstructured Text -> Human readableSemi-structured Json, XML, CSVStructuredParquet(가장 많이 사용되는), avro, orc, SequenceFile
6.Spark
parquet 같은 경우 이 포맷은 안에 스키마를 가지고 있다. field 뿐만 아니라 type도 알고 있다. 스키마 에볼루션을 지원해서 나중에 컬럼이 추가되도 문제 없이 사용 가능.개발자가 작성한 코드가 어떻게 실행되는지 web ui를 통해서 확인할 수 있다.대부분의
7.Hadoop 1
Was 서버가 데이터가 어떤노드에 있는지 찾아야했었는데, yarn이라는 Resource manager가 interface를 제공하면서, 데이터의 locality가 증가함으로서 찾는 시간이 줄어든다. 또한 yarn을 통해 hdfs 작업 이외에도 다른 작업들을 할 수 있
8.Hadoop 2
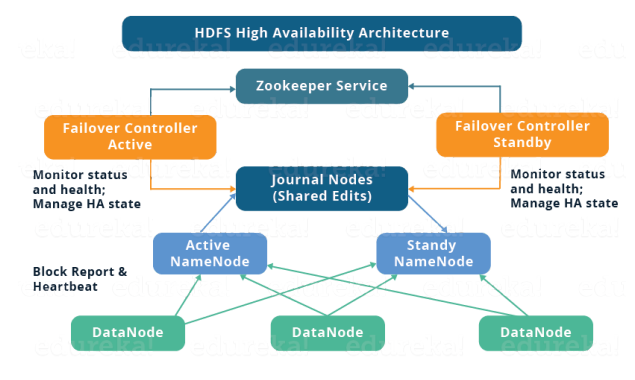
Hadoop v1.x 버전 까지는 namenode 는 SPOF(single point of failure)였다. Hadoop 의 기본 아키텍처는 namenode를 master, datanode 들을 slave 로 하는 master-slave 구조이다. 이 중 namen