Hadoop
Hortonworks의 정의
- 대용량 데이터를 commodity hardware에 분산 처리 하는 방법, 두 가지 component가 있다.
- HDFS : distributed file system
- Mapreduce : distributed processing
다수의 노드로 구성된 클러스터 시스템
- 마치 하나의 거대한 컴퓨터처럼 동작
하둡 1.0
- HDFS 큰 데이터를 손실 없이 저장
- Mapreduce는 위에서 병렬 처리
하지만 map과 reduce 2개의 operation만 제공한다.
-> 프로그래밍이 어려워져 생산성이 떨어진다
-> 그래서 위에서 도는 hive,pig,presto가 나온다.
하둡 2.0
맵리듀스말고 좀더 general한 mapreduce 대신에 yarn을 쓰자. HDFS 위에 분산 컴퓨팅 시스템으로 Yarn이 생김.
(resource management layer)
그 위에 application으로 mapreduce, spark, tez가 올라간다.
HDFS - 분산 파일 시스템은 어떻게 저장할까??
하나의 큰 파일의 데이터를 블록단위로 나눠 저장
- 블록의 크기는 128MB
이 블록들을 다수의 서버에 나누어서 저장한다. 서버의 고장으로 블록들이 유실이 될 수 도 있기 때문에, replication factor 데이터블록을 최소 3개로 나누어서 저장.
fault tolerance 를 보장 (장애 허용)
- 다수의 서버로 되어있는 데이터 노드 (slave node), 안에 있는 file system에 데이터 블록들이 들어가 있음.
- 다수의 slave를 관리하는 master를 name node라고 한다.
- 네임 노드는 어떤 파일이 있고 그걸 구성하는 데이터 블록들이 어떤 데이터 노드에 저장되어 있는지 알고있는 디렉토리
- 데이터 노드가 유실되었을 떄, 다른 블록이 있는 데이터 노드를 찾아서 background에서 복사 비슷한 명령을 취함.
- name node가 없다면 data node도 필요가 없어짐. 즉, backup이 필요함. hadoop2.0 에서는 Active와 Standby로 나누는 것이다. 네임 노드를 이중화 시키는 것이다. active에 문제가 생긴다면, standby로 진행. secondary node도 존재는 하긴한다.
MapReduce : 분산 컴퓨팅 시스템
다수의 태스크 트래커와 하나의 잡 트래커로 slave와 master로 나누어진다.
task job은 태스크 트래커에서 이루어짐.
태스크 트래커에 일을 나누어주는 역할은 잡 트래커가 맡음.
slave node에 태스크 트래커와 데이터 노드 두 가지 software가 같이 설치되어 있는 것이 일반적임.
하둡 클러스터를 구성하는 서버들이 데이터 파일 시스템과 데이터 처리 시스템의 역할을 한다.
잡트래커와 네임노드를 같이 설치도 하지만 여유가 된다면 서버를 나누어서 진행, 둘 다 너무 중요하기 때문이다.
그 위에 hive 나 presto를 두어서 구조화된 데이터를 더 효율적으로 처리하였다.
하둡2.0에서는 YARN이 등장한다...
분산 컴퓨팅 시스템 : 하둡 2.0 에서는 map reduce와 같이 고정된 분산 시스템이 있는 것이 아닌 범용적인 분산 컴퓨팅 시스템이 있다. 그 위에서 새로운 분산 처리 시스템을 만들거나 사용할 수 있는 구조가 되었다.
YARN
Mapreduce 뿐만 아니라 범용적으로 다른 것도 지원하는 범용 컴퓨팅 프레임웤이다.
slave node는 노드 매니저로 마스터에 해당하는 리소스 매니저의 요구에 따라서 자기가 가지고 있는 자원들을 일부 넘겨주는 역할이다.
여기서 자원이란 컨테이너를 의미한다. JAVA 관점에선 JVM.
JVM을 마스터 요구에 따라서 넘겨주고 할당해주고 그 상황을 리포팅해주는 역할. 이런 컨테이너 중에 특별한 컨테이너를 앱마스터가 있다.
동작 방식
1. Yarn의 어떤 application을 실행시키고 싶은 클라이언트가 있다.
- 실행하고 싶은 코드와 환경 정보를 리소스 매니저에게 넘김. 실행에 필요한 파일들은 application ID에 해당하는 HDFS폴더에 업로드, 복사가 미리됨.
-
자기가 실행시키고 싶은 코드나 환경을 리소스 매니저에게 넘긴다. 리소스 매니저는 환경정보나 코드를 알기 때문에 어느정도 리소스가 필요한지 알고 있다.
-
리소스 매니저의 첫번째 역할은 지금 실행시키려는 애플리케이션의 마스터를 만드는 것이다. 그것이 애플리케이션 마스터이다. AM은 프로그램마다 하나씩 할당되는 프로그램 마스터에 해당.
-
애플리케이션 마스터는 노드 매니저 안의 컨테이너에서 실행된다.
-
다수의 노드매니저가 있을 텐데, 일을 하고 있지않은 노드매니저를 임의로 골라서 니가 가지고있는 컨테이너를 하나 달라고 리소스 매니저에게 요청. 요청을 받으면, 그 노드 매니저의 컨테이너안에 클라이언트가 주문한 애플리케이션의 마스터 역할을 할 프로그램을 실행시키게 된다. 즉 애플리케이션 마스터는 yarn 클라이언트가 실행시킨 애플리케이션의 주인 역할이다.
yarn 애플리케이션의 수 만큼 앱마스터가 컨테이너 안에서 돌고 있는 것이다.
- 앱 마스터는 클라이언트가 제출한 코드를 실행하기 위해서 그 코드에 필요한 자원을 리소스 매니저에게 요청. 여기서 리소스는 컨테이너들이다. 컨테이너 == 리소스 .JAVA JVM과 비슷하다.(jvm인지 모르겠어요) JVM에게 해당하는 리소 할당을 요청. 리소스를 할당 받으면 그 숫자에 맞는 컨테이너(하나 혹은 여러개의 노드매니저)가 할당 된다. 그 노드 매니저로 부터 할당 받은 컨테이너 안에 클라이언트가 주문한 코드를 돌리는 task를 만든다.
- 앱마스터는 리소스를 할당 받을 때, 각 노드와 통신하고 있기 때문에 어떤 노드 매니저에게 리소스 컨테이너를 받아야하는지 알고 있다. 필요한 만큼 컨테이너를 받고 그 안에 task를 실행.(리소스 매니저는 data locality를 고려해서 컨테이너를 할당한다.)
- 컨테이너에서 돌아가는 task들은 app master에게 보고 이것을 heartbeat이라고 함.
- 만약 태스크가 실패하거나 보고가 오랜 시간 없으면 태스크를 다른 컨테이너로 재실행. -> 그러면서 fault tolerance를 보장.
- yarn 어플리케이션은 데이터는 hdfs 위에 있다고 가정한다. 하둡1.0과 동일하다.
결론
하둡 1.0은 분산 처리 시스템이 map reduce 하나 밖에 없었다. 생산적이지 못하다.
그래서 하둡 2.0을 쓰자. 리소스 매니저가 생겼고, 그 위에 분산 컴퓨팅 시스템을 할 수 있도록 구현된 3개의 레이어로 구성한다.
하둡 3.0은 yarn2.0을 이용한다. yarn 프로그램들을 논리적인 그룹(플로우라고 부름)으로 나누어서 자원 관리가 가능. 같은 그룹 내에서만 자원 이동이 가능하도록. 데이터 수집 프로세스와 서빙 프로세스를 나누어서 관리가 가능하다.
HBASE를 기본 스토리지로 사용 하둡 2.1
파일 시스템
- 네임노드의 경우 다수의 스탠바이 내임노드를 지원.
- 하둡 3.0에 HDFS,S3,Azure Storage 이외에도 Azure Data Lake storage도 지원
맵리듀스
데이터 셋은 key, value의 집합이며 변경 불가(immutable)
데이터 조작은 map과 reduce 두 개의 오퍼레이션으로만 가능.
map
- 입력으로 들어온 key value pair를 다른 key value pair나 집합(리스트)로 만들거나, output이 없을 수 도 있다.
reduce
- map의 출력 중에 같은 key를 갖는 출력들을 모아서 처리해서 새로운 key : value pair를 만듬.
개발자 관점에서는 map과 reduce안의 함수를 채워주는 것.
map의 입력과 reduce 입력은 시스템에서 만들어주고, 두 오퍼레이션은 쌍으로 존재한다. 한번의 map reduce로는 원하는 결과를 만들지 못하고 여러번의 과정을 거쳐야함.
맵리듀스 시스템이 map의 결과를 reduce 단으로 모아줌.
이 단계를 보통 셔플링이라 부르며 네트웍단을 통해 데이터 이동이 생김.
map reduce 코드 채워주고 hdfs 입력 파일이 어디에 있는지 어디에 저장되어 있는지 알려주면, 시스템이 알아서 다 해준다.
맵의 입력에 으로 들어가는 파일 수에 따라서 맵을 실행하는 태스크 수가 정해지고, reduce의 태스크 수는 개발자가 지정.
맵리듀스 프로그래밍의 핵심: 맵과 리듀스
MAP : (k,v) -> [(k',v')*]
입력은 시스템이 결정함.
키, 벨류 페어를 새로운 키, 벨류 페어 리스트로 변환(transformation)
출력 : 입력과 동일한 키, 벨류 페어를 그대로 출력해도 되고 출력이 없어도 됨.
Reduce :(k',[v1',v2',v3']) -> (k'',v'')
입력은 시스템에 의해 주어짐.
- 맵의 출력중 같은 키 를 갖는 키/벨류 페어를 시스템이 묶어서 입력으로 넣어줌. 이거를 보고 개발자가 어떤 형태로든 요약해서 새로운 키 벨류를 만들어내면 됌. 출력은 없어도 됨. hdfs에 저장되고, sql의 group by와 흡사하다.
리듀스의 숫자에 따라서 저장 공간의 개수가 정해진다.
shuffling과 sorting이 되어서 리듀스로 보내지는 과정에서 여러개의 리듀스 서버 중에 한쪽에만 몰리는 경우 data skew가 생길 수 있다.
Shuffling and Sorting
HDFS의 인풋이 3개가 있다. 각 파일 별로 map 태스크가 생김. hdfs의 한블록의 최대 용량은 128mb 이다. map task는 블록 갯수 만큼 생긴다.
만약 한 파일의 크기가 128 보다 작다 -> 그러면 map task는 한 개로 충분하다.
맵안에서 개발자의 코드가 처리된 이후 리듀스의 갯수를 보고, 각 맵의 출력을 보고 어디로 보낼 건지 결정하게 된다. map이 모든 key value pair를 다 처리한다면, 네트워크를 타고 송신한다. 이 과정을 shuffling이라 한다. merge를 해서 같은 key를 갖는 쌍을 하나의 리스트로 묶는 과정이 sorting.
map reduce : Data Skew
각 태스크가 처리하는 데이터의 크기에 불균형이 존재한다면,
병렬 처리의 큰 의미가 없음. 가장 느린 태스크가 처리 속도를 결정.
이 문제는 리듀서로 오는 나눠지는 데이터의 크기는 큰 차이가 있을 수 있음.
문제점
낮은 생산성 flexiblity 낮음. 2가지 오퍼레이션
튜닝/최적화가 쉽지 않음
배치작업 중심 -> 빠르게가 초점이 아닌 큰 데이터를 처리하는 데 목적.
low latency 보다 throughput
그래서 yarn과 spark 등장 스트리밍도 하기 위해서
sql의 컴백 hive, presto 등장
hive -> mapreduce위에서 구현. throughput에 초점. 대용량 ETL에 적합. 하둡 2.0은 테즈 위에서 구현.
presto -> low latency 중점. adhoc 쿼리에 적합 aws athena
JVM은 Java Virtual Machine의 약자로, 자바 언어로 작성된 프로그램이 실행되는 가상 컴퓨터입니다. 자바 프로그램은 컴파일러에 의해 자바 바이트 코드로 변환되고, JVM은 이를 해당 플랫폼에 맞게 해석하여 실행합니다. 이를 통해 자바 언어로 작성된 프로그램은 플랫폼에 독립적으로 실행될 수 있습니다.
YARN은 Hadoop 클러스터의 리소스 관리를 담당하는 Apache Hadoop의 하위 프로젝트입니다. YARN은 클러스터에서 실행되는 작업을 관리하고 조율하는 역할을 합니다. YARN은 클러스터에서 실행되는 각각의 작업에 대해 별도의 컨테이너를 할당하고, 각 컨테이너에서는 작업을 실행하는 데 필요한 환경을 제공합니다. 이때 컨테이너에서 실행되는 작업이 자바 프로그램일 경우, 해당 작업은 JVM을 사용하여 실행됩니다. 따라서 YARN의 컨테이너가 JVM을 실행하는 것이 맞습니다.
spark 3.0

map reduce 디스크 기반
디스크에 항상 쓰고 디스크에서 읽는다.
spark는 기본적으로 메모리 기반
메모리가 부족해지면 디스크 사용
mapreduce는 디스크 기반
mapreduce는 하둡 위에서만 동작
spark은 하둡 이외에도 다른 분산 컴퓨팅 환경 지원.
spark은 키벨류 구조가 아닌 판다스 데이터 프레임과 개념적으로 동일한 데이터 구조 지원
Spark 프로그래밍 API
RDD - Resilient Distributed Dataset
로우레벨 프로그래밍 API로 세밀한 제어가 가능
하지만 코딩 복잡도 증가
DataFrame & Dataset(판다스 데이터프레임과 흡사)
python - dataframe
scala,java - dataset
테이블이라면 sparksql이 더 효율적이고 code maintenance이 좋음
Spark SQL
구조화된 데이터 처리를 SQL로 처리
dataframe을 sql로 처리할 수 있다.
판다스도 동일 기능 제공
HIVE 쿼리 보다 최대 100배까지 빠른 성능을 보장
hive : disk -> memory 지금은 mem -> mem 그래서 비슷
spark, presto : mem -> mem
머신러닝 관련 다양한 알고리즘
sparkML의 장점
원스톱 ML framework
데이터프레임과 SparkSQL등을 이용해 전처리
대용량 데이터도 처리가능
Spark 데이터 시스템 사용 예들
기본적으로 대용량 데이터 배치처리, 스트림 처리, 모델 빌딩
대용량 비구조화된 데이터 처리하기 - 배치 프로세싱
ml 모델에 사용되는 대용량 피쳐 처리
spark ml을 이용한 대용량 훈련 데이터 모델 학습
예시
log -> s3 <-> Spark -> 데이터 웨어하우스
Spark 자리에 hive나 presto가 있어도 된다.
이 경우 배치로 처리하는 경우
ML 모델에 사용되는 대용량 피쳐 처리
s3,redshift,kinesis(realtime) -> spark(batch,streaming) -> NOSQL(Cassandra, Hbase,REDIS) -> ML API
SPark 프로그램 실행 환경
개발/테스트/학습 환경
- 노트북
- spark shell
프로덕션 환경 - spark submit
- 데이터 브릭스 노트북
- rest api : spark stand alone 모드에서만 가능
실행 코드는 미리 hdfs에 저장 api를 통해 spark잡을 실행
Spark 프로그램의 구조
YARN 가정
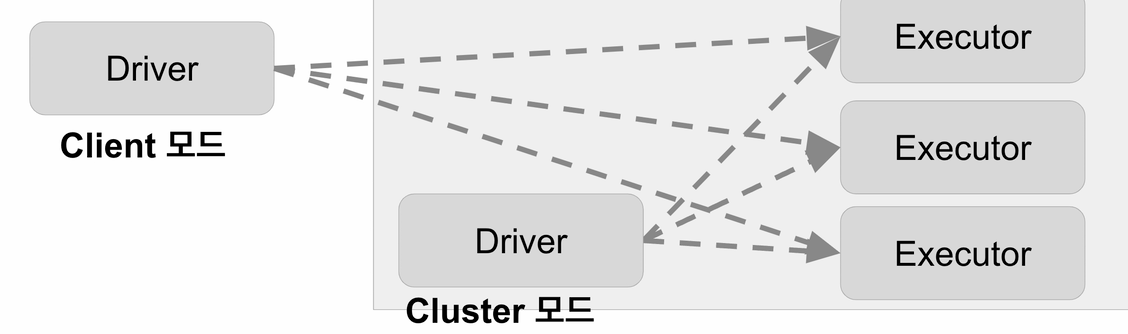
Driver
- 실행되는 코드의 마스터 역할 수행 (YARN의 Application Master)
Executor - 실제 태스크를 실행해주는 역할 수행
Driver
Client, Cluster 모드가 있음
-
Cluster 때는 driver가 yarn cluster 안에서 컨테이너를 하나잡아서 동작. 스파크 서밋과 같은 커맨드라인 유틸리티를 써서 개발이 끝난 코드를 클러스터 안에서 돌리는 것임
-
Client일 때는 Cluster 밖에서 돈다. 기본적으로 노트북이나 스파크 쉘 처럼 학습, 개발, 디버깅을 위해서 밖에서 돌리는 것임
스파크 서밋 사용시) cmd parameter 아래와 같은 예시가 있음
- --num-executors
job을 끝내는 데 몇개의 executor를 쓸거냐 - --executor-cores
몇개의 cpu를 쓸거냐 - --executor-memory
얼만큼 메모리를 쓸거냐
driver 코드 내에서 spark context를 만들어서 spark cluster와 통신 수행
1. Yarn의 리소스 매니저 == 스파크에서는 Cluster Manager.
2. Excutor YARN의 경우 Container
Task에 대한 리포트를 받음.
Executor:
하나의 jvm이라고 보면 됌. 실제 태스크를 실행해주는 역할 수행. Transformation,actions. YARN에서는 컨테이너.
Spark 클러스터 매니저 옵션
local[n] - 내 컴퓨터에서 아주 간단한 단일 클러스터를 돌리는 옵션.
- n은 몇개의 thread를 띄울꺼냐. jvm을 하나 띄어서 그게 마치 스파크 클러스터처럼 쓸텐데 몇개의 thread를 띄울건지.
- spark shell, IDE, notebook
- n은 thread의 수 : executor의 수가 됨
local[*] 은 모든 코어 사용
yarn - client mode, cluster mode
Driver가 notebook, sparkshell이 될 수 있음 - client mode
spark submit - cluster mode
YARN 클러스터)
k8s
mesos
standalone - 잘 안쓰임.
