1.Spark 데이터 처리의 기본이 되는 파티션에 대해 알아보자
Spark 데이터 시스템 아키텍쳐
spark 같은 경우 분산 파일 시스템이 없다. 우리는 HDFS,S3,Azure Blob, GCP cloud Storage와 같은 분산 파일 시스템 위에서 사용한다.
이 위에 YARN이나 쿠버네티스와 같은 리소스 매니저가 있고 그 위에 spark가 돌아간다.
배치 형태로 큰 데이터를 ETL 하거나 adhoc 형태로 인터렉티브하게 쿼리를 날리려는 의도라면, hive나 presto를 쓰면 되는데 spark를 왜 쓸까?
한 시스템에서 여러개를 사용할 수 있어서.
이미 데이터가 파일 시스템에 있다면 spark로 로딩하는데, 이미 존재하기 때문에 큰 문제가 없다. 하지만 모든 데이터는 hdfs내에 항상 있는 것이 아니다. 외부데이터 같은 경우는 rdbms나 nosql이 있다.
- 필요한 외부 데이터에서 주기적인 ETL를 통해서 hdfs에 넣는다.
- 필요하면 그때 그때 spark으로 가져오는 것.
데이터 병렬처리가 가능하려면?
데이터가 먼저 분산되어야함.
하둡 맵의 데이터 처리 단위는 디스크에 있는 데이터 블록(보통 128mb)
hdfs-site.xml에 있는 dfs.block.szie 프로퍼티가 결정
Spark에서는 이를 파티션이라고 부름. 파티션의 기본 크기도 128MB
spark.sql.files.maxPartitionBytes: HDFS등에 있는 파일을 읽어올 때만 적용됨.
다음으로 나눠진 데이터를 각각 따로 동시 처리
맵리듀스에서 N개의 데이터 블록으로 구성된 파일 처리시 N개의 Map 태스크가 실행
스파크에서는 파티션 단위로 메모리로 로드되어 Executor가 배정됨.
- 처리하려는 데이터 파일이 hdfs에 나눠서 저장되어 있음. 4개의 데이터 블록으로 만들어져 있다. 그러면 4개의 파티션이 생김.
만약 외부에서 mysql 등에서 spark를 통해 데이터를 가져와야한다. 그렇다면 jdbc 소스 같은 경우 별도의 설정이 없다면 기본으로 하나의 파티션만 만듬.
어떤 소스에서 불러오는지에 따라 달라짐.
꼭 필요할 때가 아니면, 별도의 process를 통해서 hdfs에 저장하고 spark job은 Hdfs에서만 진행.
spark cluster에 executor가 2개가 있다. 각 cpu가 하나씩 배정되어 있다면, 이 spark cluster는 최대 처리할 수 있는 task는 2개밖에 되지 않는다. 4개의 파티션은 2번의 병렬처리로 이루어짐.
Spark 데이터 구조
RDD(Resilient Distributed Dataset)
로우레벨 데이터로 클러스터내의 서버에 분산된 데이터를 지칭
레코드별로 존재하지만 스키마가 존재하지 않음
- 그래서 구조화된 데이터나 비구조화된 데이터 모두 지원
DataFrame과 Dataset
RDD위에 만들어지는 RDD와는 달리 필드 정보를 갖고 있음(테이블)
Dataset은 타입 정보가 존재하며 컴파일 언어에서 사용가능
pyspark 같은 경우 DataFrame을 사용

RDD위에 spark engine이 올라가서 rdd operation을 optimizing하는 역할 인데, spark sql engine의 힘을 빌리려면 상위 레벨의 api를 사용해야한다. DataFrame이 일반 sql을 사용할 수 있다면, spark sql만 사용하면 됌.
spark sql engine은 우리가 작성한 dataframe code나 spark sql 코드를 RDD operation으로 만들어주고 그걸 최종적으로 자바 바이트 코드로 바꿔주는 건데, 처음은 코드를 분석해서 어떤 테이블이 쓰이고, 어떤 컬럼이 쓰이는지 먼저 결정내고, 코드 분석을 통해서 logical optimization 단계에서는 이 코드를 실행할 수 있는 방안들을 만들어냄(그리고 catalyst optimizer이 방안들마다 최종적으로 얼마나 비용이 필요한지 계산), 이 과정에서 standard sql 최적화 방식을 사용. physical planning 단계에서는 가장 싼 것을 골라서 rdd operation 코드를 작성, 마지막 code generation 단계에서는 java 바이 코드로 만듬. projectTungsten 방법을 사용해서 최적화.
- code analysis
- logical optimization - catalyst optimizer
- physical planning
- code generation - projectTungsten
4가지 단계를 거쳐서 spark sql 코드를 효율적으로 자바 바이코드로 만들어주는 것이 spark sql engine. RDD를 사용하면 사용 불가함.
Spark 데이터 구조 - RDD
일반 파이썬 데이터는 parallelize 함수로 RDD로 변환
반대는 collect로 파이썬 데이터로 변환가능
드라이버에 있는 파이썬 리스트를 parllize하면 RDD로 변환
collect하면 스파크 상에 코드가 아닌 python 코드로 된다.
rdd가 정말 크다면 collect시 메모리 오류.
Spark 데이터 구조 - 데이터 프레임
RDD위에서 돌아가게 됨으로 immutable
테이블처럼 컬럼으로 나눠 저장
판다스와 rdbms와 흡사
다양한 데이터 소스 지원
SparkSession 생성
Spark 프로그램의 시작은 SparkSession을 만드는 것
프로그램마다 하나를 만들어 SparkCluster와 통신: Singleton 객체
Spark Session을 통해 Spark이 제공해주는 다양한 기능을 사용
DataFrame,SQL, Streaming 모두 이 객체로 통신
config 메소드를 이용해 다양한 환경설정 가능
단 RDD와 관련된 작업을 할때는 SparkSession 밑의 SparkContext 객체 사용.
spark2.0이 나오면서, dataset, dataframe, spark sql이 spark sql engine위에서 동작하면서 spark session도 pyspark sql 내의 모듈로 되었다.
spark = SparkSession.builder\
.master("local[*]")\ .appName('PySpark Tutorial')\ .getOrCreate()
...
spark.stop() 마스터로 어떤 리소스 매니저를 사용할 건지, 이경우 local standalone 별은 cpu, 쓰레드 수.
get or create -> 싱글톤이라는 것. 한 프로그램에 하나만 있으면 된다. 없으면 만들고 있으면 return.
spark stop은 끝내고 리소스 반환.
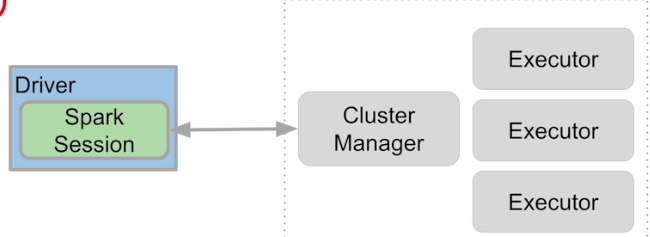
스파크 클러스터 내에 클러스터 매니저와 통신.
Spark Session을 만들 때 다양한 환경 설정이 가능
❖ 몇 가지 예
● executor별 메모리: spark.executor.memory (기본값: 1g)
● executor별 CPU수: spark.executor.cores (YARN에서는 기본값 1)
● driver 메모리: spark.driver.memory (기본값: 1g)
● Shuffle후 Partition의 수: spark.sql.shuffle.partitions (기본값: 최대 200)
spark Session 환경 설정 방법 4가지
환경변수 혹은 spark_default.conf 파일 -> 보통 spark cluster 어드민이 관리 -> 개발자가 잘 손대지 않음
spark -submit 명령의 커맨드라인 파라미터
sparkSession 만들 때 지정 - buildup pattern 혹은 SparkConf
만약에 똑같은 변수가 4개에 있다면, 결국은 아래서부터 우선순위가 높다. sparksession 만들 때, 지정한 것이 우선순위가 높음.
from pyspark.sql import SparkSession
# SparkSession은 싱글턴
spark = SparkSession.builder\
.master("local[*]")\
.appName('PySpark Tutorial')\ .config("spark.some.config.option1", "some-value") \ .config("spark.some.config.option2", "some-value") \ .getOrCreate()
# or sparkConf 지정
from pyspark.sql import SparkSession
from pyspark import SparkConf
conf = SparkConf()
conf.set("spark.app.name", "PySpark Tutorial")
conf.set("spark.master", "local[*]")
# SparkSession은 싱글턴
spark = SparkSession.builder\
.config(conf=conf) \ .getOrCreate()config (변수이름, 값)
이 시점의 Spark Configuration은 앞서 언급한 환경변수와 spark_defaults.conf와 spark-submit로 들어온 환경설정이 우선순위를 고려한 상태로 정리된 상태
전체적인 플로우
SparkSession을 만들기
입력데이터 로딩
데이터 조작 작업
DataFrame API나 Spark SQL을 사용
원하는 결과가 나올때까지 새로운 DataFrame을 생성
최종 결과 저장 대상은 hive의 테이블, hdfs, rdbms 등
SparkSesson이 지원하는 데이터 소스
spark.read를 사용하여 데이터 프레임으로 로드가능
- 즉 지원하는 것은 다 됌
spark.write을 사용하여 데이터 프레임을 저장가능
- 즉 지원하는 것은 다 됌
HDFS 파일
- csv, Json, Parquet,ORC, TEXT, avro
hive 테이블
JDBC형 관계형 데이터베이스
클라우드 기반 데이터 시스템
스트리밍 시스템
Spark 개발 환경 옵션
자신의 컴퓨터나 리눅스 서버에
Local Standalone Spark + spark shell
python IDE- pycharm, visual Studio
Databricks Cloud
다른 노트북 - 주피터, 코랩, 아나콘다
local standalone spark
spark cluster manager로 local[n]지정
master를 local[n] 지정
master는 클러스터 매니저를 지정하는데 사용
주로 개발이나 간단한 테스트 용도
하나의 JVM에서 모든 프로세스를 실행
하나의 driver와 하나의 executor가 실행됨
1+ 쓰레드가 excutor안에서 실행됨
Executor안에 생성되는 쓰레드 수
local : gkskdml TMfpemaks todtjd
local[*] : 컴퓨터 cpu 수만큼 쓰레드 생성
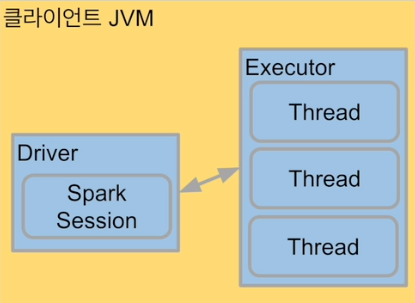
- local[3]
구글 코랩에서 Spark 사용
pyspark + py4j
구글 코랩 가상서버위에 로컬 모드 spark을 실행
- 기본적으로는 스파크 ui는 못들어감. 포트가 막혀 있음.
py4j는 파이썬에서 jvm내에 있는 자바 객체를 사용가능하게 해줌.
spark는 lazy excution 때문에, 쓰기 읽기 작업 등 실제 데이터가 리턴되어야하는 작업들이 있어야만 그때 실행됨.
Mac에서 local standalone Spark 사용
Mac Catalina 이후 버전 기준
z쉘이 기본으로 사용됨
자바 관련 설정
JDK 8/11이 필요: 터미널에서 java - version 명령으로 체크
