SparkSQL
Spark SQL vs .DataFrame
하지만 SQL로 가능한 작업이라면 DataFrame을 사용할 이유가 없음.
두 개를 동시에 사용할 수 있다는 점 분명히 기억
- Familiarity/Readability
- sql이 가독성이 더 좋고 더 많은 사람들이 사용가능
- optimization
- sparkSQL 엔진이 최적화하기 더 좋음 SQL은 Declarative
Catalyst Optimizer와 Project Tungsten
- Interoperability/Data Management
SQL이 포팅도 쉽고 접근권한 체크도 쉬움.
SQL 사용방법
- 데이터프레임을 기반으로 테이블 뷰 생성: 테이블이 만들어짐
createOrReplaceTempView : Spark Session이 살아있는 동안 존재
createOrReplaceGlobalTempView: Spark 드라이버가 살아있는 동안 존재
Spark Session의 sql 함수로 SQL 결과를 데이터 프레임으로 받음
SparkSession 사용 외부 데이터베이스 연결
spark Session의 read 함수를 호출
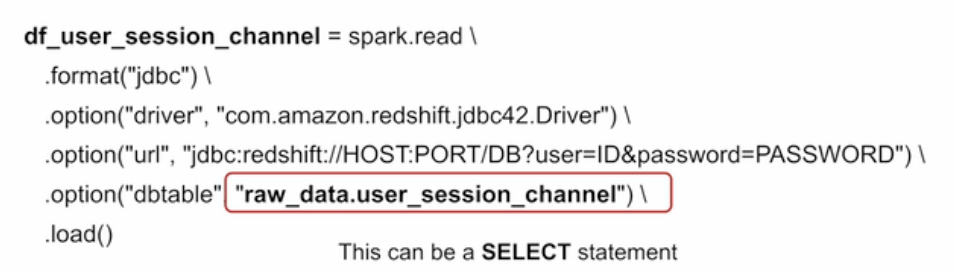
Join - Inner Join
양쪽 테이블에서 매치가 되는 레코드만 리턴
양쪽 테이블의 필드가 모두 채워진 상태로 리턴됨.
Left Join
왼쪽 테이블의 모든 레코드들을 리턴함
오른쪽 테이블의 필드는 왼쪽 레코드와 매칭되는 경우에만 채워진 상태로 리턴됨.
- 오른쪽 필드는 널값 포함
Full Join
왼쪽 테이블과 오른쪽 테이블의 모든 레코드들을 리턴함
매칭되는 경우에만 양쪽 테이블들의 모든 필드들이 채워진 상태로 리턴됨.
- 왼쪽 오른쪽 다 널값 포함
Cross Join
왼쪽 테이블과 오른쪽 테이블의 모든 레코드들의 조합을 리턴함.
Self Join
동일한 테이블을 alias를 달리해서 자기 자신과 조인함.
똑같은 테이블이 2개 생기겠죠?
최적화 관점에서 본 조인의 종류들
위의 조인들은 단지 문법적 조인. 스파크 Join을 사용하게 되면 최적화가 필요해짐.
왜 그럴까?
데이터셋의 크기가 큰 경우 파티션의 수가 여러개임. 조인을 하는 키를 바탕으로 셔플링이 생김. 셔플링을 하게 되면, 만들어진 파티션을 기준으로 data skew가 생길 수 있음. 셔플을 되도록 피하는게 좋음.
Shuffle Join
- 일반 조인 방식
- Bucket Join: 조인 키를 바탕으로 새로 파티션을 새로 만들고 조인을 하는 방식. 이 과정을 통해서 셔플링이 안발생하게 만들 수 있음.
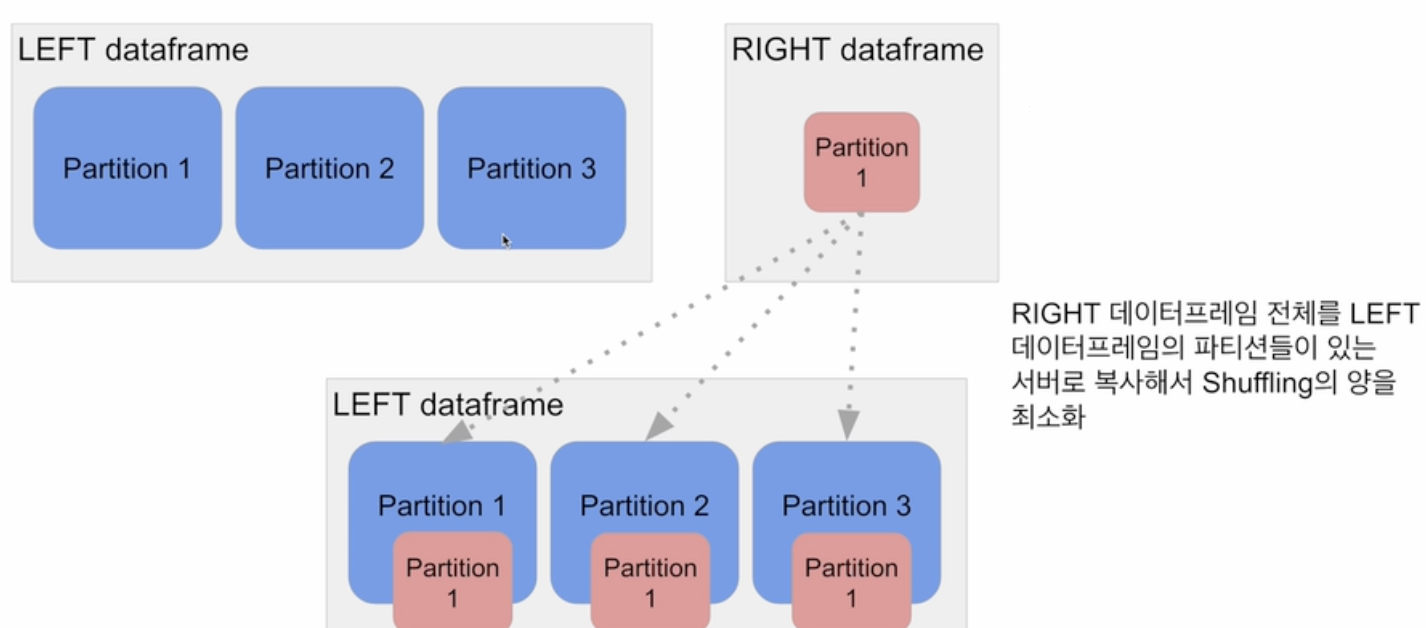
Broadcast Join
큰 데이터와 작은 데이터간의 조인
데이터 프레임 하나가 충분히 작으면 작은 데이터 프레임을 다른 데이터 프레임이 있는 서버들로 뿌리는 것 (broadcasting).
spark.sql.autoBroadcastJoinThreshold 파라미터로 충분히 작은지 여부 결정.
Bucket Join
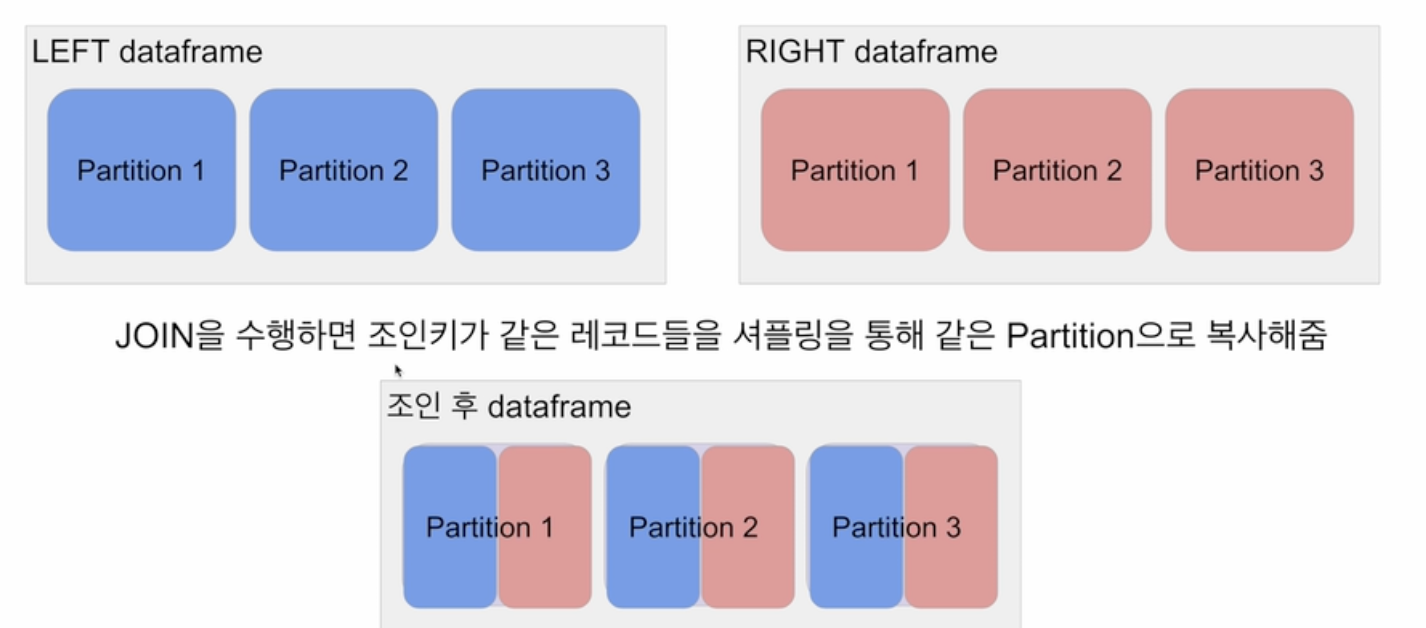
join 후의 파티션 수는 스파크 환경변수
Broadcast Join
UDF(User Defined F)
데이터 프레임의 경우 .withcolumn함수를 써서 새로운 컬럼을 만들고 사용하는 것이 일반적
- spark SQL
Aggreagtion dyd UDAF도 존재
Group BY에서 사용되는 SUM, AVG와 같은 함수를 만드는 것
pyspark에서 지원되지 않음. Scalar/Java를 사용함.
import pyspark.sql.functions as F from pyspark.sql.types import *
upperUDF = F.udf(lambda z:z.upper()) df.withColumn("Curated Name", upperUDF("Name"))def upper(s): return s.upper()
# 먼저 테스트
upperUDF = spark.udf.register("upper", upper)
# upper 함수를 "upper"로 등록할게
spark.sql("SELECT upper('aBcD')").show()
# DataFrame 기반 SQL에 적용
df.createOrReplaceTempView("test")
spark.sql("""SELECT name, upper(name) "Curated Name" FROM test""").show()data = [{"a": 1, "b": 2}, {"a": 5, "b": 5}]
df = spark.createDataFrame(data) df.withColumn("c", F.udf(lambda x, y: x + y)("a", "b"))def plus(x, y):
return x + y
plusUDF = spark.udf.register("plus", plus) spark.sql("SELECT plus(1, 2)").show()
df.createOrReplaceTempView("test")
spark.sql("SELECT a, b, plus(a, b) c FROM test").show()register를 통해서 udf를 등록할 수 있다.
UDF - Pandas UDF Scalar
from pyspark.sql.functions import pandas_udf import pandas as pd
@pandas_udf(StringType())
def upper_udf2(s: pd.Series) -> pd.Series:
return s.str.upper()
upperUDF = spark.udf.register("upper_udf", upper_udf2)
df.select("Name", upperUDF("Name")).show()
spark.sql("""SELECT name, upper_udf(name) `Curated Name` FROM test""").show()중간에 pandas_udf annotation을 볼 수 있다. 스칼라를 사용하는 이유는 판다스 시리즈 타입으로 들어오기 때문에, 벌크 처리한다. 즉 레코드의 집합을 한번에 처리한다.
위의 파이썬 함수나 람다처럼 레코드 하나만 하는 것이 아닌 레코드의 집합을 벌크처리를 하는 것.
from pyspark.sql.functions import pandas_udf import pandas as pd
@pandas_udf(FloatType())
def average(v: pd.Series) -> float:
return v.mean()
averageUDF = spark.udf.register('average', average)
spark.sql('SELECT average(b) FROM test').show() df.agg(averageUDF("b").alias("count")).show()aggreagation을 scala로 작성할 수 있다. 보면 리턴타입이 float인 것을 확인할 수 있다. df.agg와 역할은 동일하다.
SparkSQL
spark.sql("""SELECT sessionid, COUNT(1) count
FROM session_transaction
GROUP BY 1
ORDER BY 2 DESC
LIMIT 1""").show() 만약 여기서 카운트가 1 초과라면 session id는 uniqueness를 보장하지 않는 것
WINDOW Function 같은 경우는 레코드를 줄이는 것이 아닌 컬럼을 늘려가는 것
first_last_channel_df = spark.sql("""
WITH RECORD AS (
SELECT /*사용자의 유입에 따른, 채널 순서 매기는 쿼리*/
userid,
channel,
ROW_NUMBER() OVER (PARTITION BY userid ORDER BY ts ASC) AS seq_first,
ROW_NUMBER() OVER (PARTITION BY userid ORDER BY ts DESC) AS seq_last
FROM user_session_channel u
LEFT JOIN session_timestamp t
ON u.sessionid = t.sessionid
)
SELECT /*유저의 첫번째 유입채널, 마지막 유입 채널 구하기*/
f.userid,
f.channel first_channel,
l.channel last_channel
FROM RECORD f
INNER JOIN RECORD l ON f.userid = l.userid
WHERE f.seq_first = 1 and l.seq_last = 1
ORDER BY userid
""")같은 테이블끼리 조인 하는 경우. 윈도우 함수는 강력하다. 잘 알아두자
Spark 데이터 베이스와 테이블
카탈로그 : 테이블과 뷰에 관한 메타 데이터 관리
- 기본으로 메모리 기반 카탈로그 제공 - 세션이 끝나면 사라짐
- Hive와 호환되는 카탈로그 제공 - Persistent
- 디스크에 저장되서 세션이 종료되도 디스크기반으로 저장하는 것이 필요함.
- 결국엔 하이브 메타스토어를 스파크 테이블의 메타스토어로 사용하자.
결론은 2개의 메타스토어가 존재한다.
- 인메모리 메타스토어
- 임시테이블이 아니라 hdfs와 같은 file system에 저장되는 테이블을 만들고 싶다. 하이브와 호환이 되는 메타스토어를 쓸 수 있다.
테이블 관리 방식
- 테이블들은 데이터 베이스라 부르는 폴더와 같은 구조로 관리(2단계)
- 테이블의 성격에 따라서 데이터베이스를 나누고 그 안에 테이블을 만드는 것.
ETL로 레이크나 웨어하우스에 들어온다면 raw_data, 요약된 denormalized된 데이터는 analytics, 개인 정보가 포함된 데이터라면 pii와 같은 테이블.
redshift 접근 방식과 동일.
Spark 데이터베이스와 테이블
메모리 기반 테이블/뷰
- 임시 테이블
스토리지 기반 테이블
- 기본적으로 HDFS와 Parquet 포맷 사용
HIVE와 호환되는 메타스토어 사용
두 종류의 테이블이 존재
-
Managed Table
spark이 실제 데이터와 메타 데이터 모두 관리(성능적 좋음) -
Unmanaged Table(External Table)
spark이 메타 데이터만 관리
실제 데이터는 관리하지 않음. 만약 drop 하게 된다면, 내부 테이블 이라면 hdfs 실제 데이터도 drop, 외부테이블이라면 메타 데이터만 사라짐.
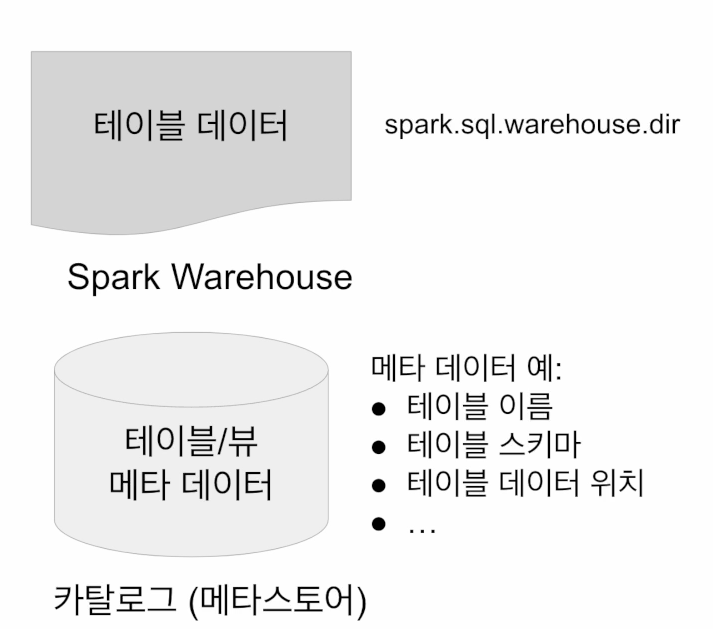
테이블관련된 다양한 데이터는 메타스토어에 저장되어 있고, 테이블 데이터는 실제로 hdfs 어딘가에 저장되어 있는데 spark.sql.warehouse.dir로 설정해준다.
Spark SQL - 스토리지 기반 카탈로그 사용 방법
❖ Hive와 호환되는 메타스토어 사용
❖ SparkSession 생성시 enableHiveSupport() 호출
● 기본으로 “default”라는 이름의 데이터베이스 생성 from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark Hive") \ .enableHiveSupport() \ .getOrCreate()
Spark 프로그래밍: SQL
◆ Spark SQL - Managed Table 사용 방법
❖ 두 가지 테이블 생성방법
● dataframe.saveAsTable("테이블이름")
● SQL 문법 사용 (CREATE TABLE, CTAS)
❖ spark.sql.warehouse.dir가 가리키는 위치에 데이터가 저장됨
● PARQUET이 기본 데이터 포맷
❖ 선호하는 테이블 타입
❖ Spark 테이블로 처리하는 것의 장점 (파일로 저장하는 것과 비교시)
● JDBC/ODBC등으로 Spark을 연결해서 접근 가능 (태블로, 파워BI)
Spark 프로그래밍: SQL
◆ Spark SQL - External Table 사용 방법
❖ 이미 HDFS에 존재하는 데이터에 스키마를 정의해서 사용
● LOCATION이란 프로퍼티 사용
❖ 메타데이터만 카탈로그에 기록됨
● 데이터는 이미 존재.
● External Table은 삭제되어도 데이터는 그대로임
CREATE TABLE table_name ( column1 type1,
column2 type2,
column3 type3,
... )
USING PARQUET
LOCATION 'hdfs_path';
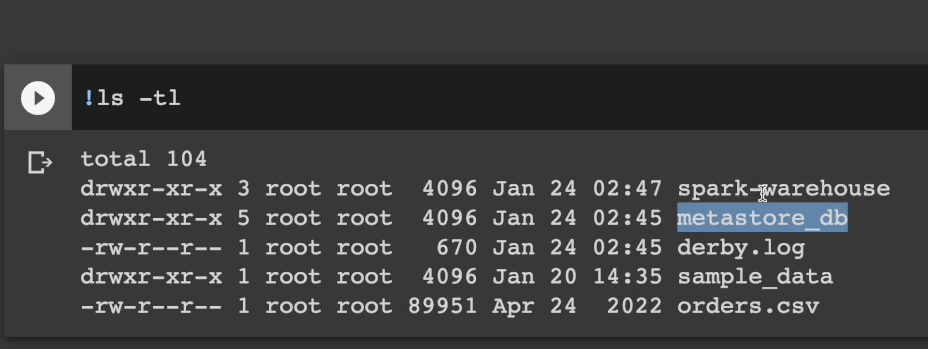
hive를 세션에 정의하고 테이블을 생성하면 metastore_db가 생긴다. 하이브와 호환되는 메타스토어. spark warehouse 같은 경우는 hdfs 폴더. spark에서 managed table을 만들면 spark warehouse 내에 저장되는 것.

세션 아래에 카탈로그를 보면 managed type에 임시테이블이 아닌 것으로 확인할 수 있다.
궁금한점)
스파크 세션에 하이브를 정의하지 않았을 때, CTAS를 적용하면 어떻게 되는지
아마도 스파크 세션의 메타데이터에 저장만 되겠죠?
유닛 테스트
코드 상의 특정 기능 보통 메소드의 형태를 테스트하기 위해 작성된 코드
보통 정해진 입력을 주고 예상된 출력이 나오는지 형태로 테스트
CI/CD를 사용하려면 전체 코드의 테스트 커버러지가 굉장히 중요해짐
각 언어별로 정해진 테스트 프레임웍을 사용하는 것이 일반적
- unittest for python를 사용해볼 예정
코드 상에 70% 80%이상 테스트 해보아야함.
코드를 작성하기전에 테스트 코드를 먼저 작성해보고 기능을 채워나간다... 라는 컨셉이 있다고 하네요.
보통은 코랩에서 테스트하려는 코드와 테스트 코드가 하나에 있지 않음. 함수를 Import해서 테스트하는 게 일반적.
from unittest import TestCase
# 일반적으로는 아래 함수가 정의된 모듈을 임포트하고 그걸 테스트
# - upper_udf_f
# - load_gender
# - get_gender_count
class UtilsTestCase(TestCase):
spark = None
@classmethod
def setUpClass(cls) -> None:
cls.spark = SparkSession.builder \
.appName("Spark Unit Test") \
.getOrCreate()
def test_datafile_loading(self):
sample_df = load_gender(self.spark, "name_gender.csv")
result_count = sample_df.count()
self.assertEqual(result_count, 100, "Record count should be 100")
def test_gender_count(self):
sample_df = load_gender(self.spark, "name_gender.csv")
count_list = get_gender_count(self.spark, sample_df, "gender").collect()
count_dict = dict()
for row in count_list:
count_dict[row["gender"]] = row["count"]
self.assertEqual(count_dict["F"], 65, "Count for F should be 65")
self.assertEqual(count_dict["M"], 28, "Count for M should be 28")
self.assertEqual(count_dict["Unisex"], 7, "Count for Unisex should be 7")
def test_upper_udf(self):
test_data = [
{ "name": "John Kim" },
{ "name": "Johnny Kim"},
{ "name": "1234" }
]
expected_results = [ "JOHN KIM", "JOHNNY KIM", "1234" ]
upperUDF = self.spark.udf.register("upper_udf", upper_udf_f)
test_df = self.spark.createDataFrame(test_data)
names = test_df.select("name", upperUDF("name").alias("NAME")).collect()
results = []
for name in names:
results.append(name["NAME"])
self.assertCountEqual(results, expected_results)
@classmethod
def tearDownClass(cls) -> None:
cls.spark.stop()setupclass는 테스트 처음에 -> 테스트에서 계속 사용되는 정보
teardownclass는 마지막 릴리즈 전용
assertEqual 같은 경우는 두 인자가 동일한지
assertCountEqual은 result를 sorting했을 때 같은지.
unittest와 같은 경우는 커맨드라인과 같은데서 해야지, ide와 같은 인터렉트한 환경에서 하기엔 다름.
테스트 코드에서는
from my_df import 함수들 형식으로 가져와서 테스트 코드를 실행하자.
