YARN이란 무엇입니까?
YARN(Yet Another Resource Negotiator)은 Hadoop 생태계의 중요한 구성 요소입니다. Hadoop 클러스터에서 실행되는 분산 애플리케이션에 대한 CPU, 메모리, 스토리지와 같은 리소스를 관리하고 할당하는 역할을 하는 클러스터 리소스 관리 계층의 역할을 합니다.
왜 YARN이 필요한가요?
YARN의 주요 목표는 리소스 관리 및 데이터 처리 기능을 별도의 구성 요소로 분리하는 것입니다. 이를 통해 MapReduce, Spark, Storm, Tez 등과 같은 다양한 데이터 처리 애플리케이션을 지원할 수 있는 전역 리소스 관리자를 단일 클러스터에서 실행할 수 있습니다.
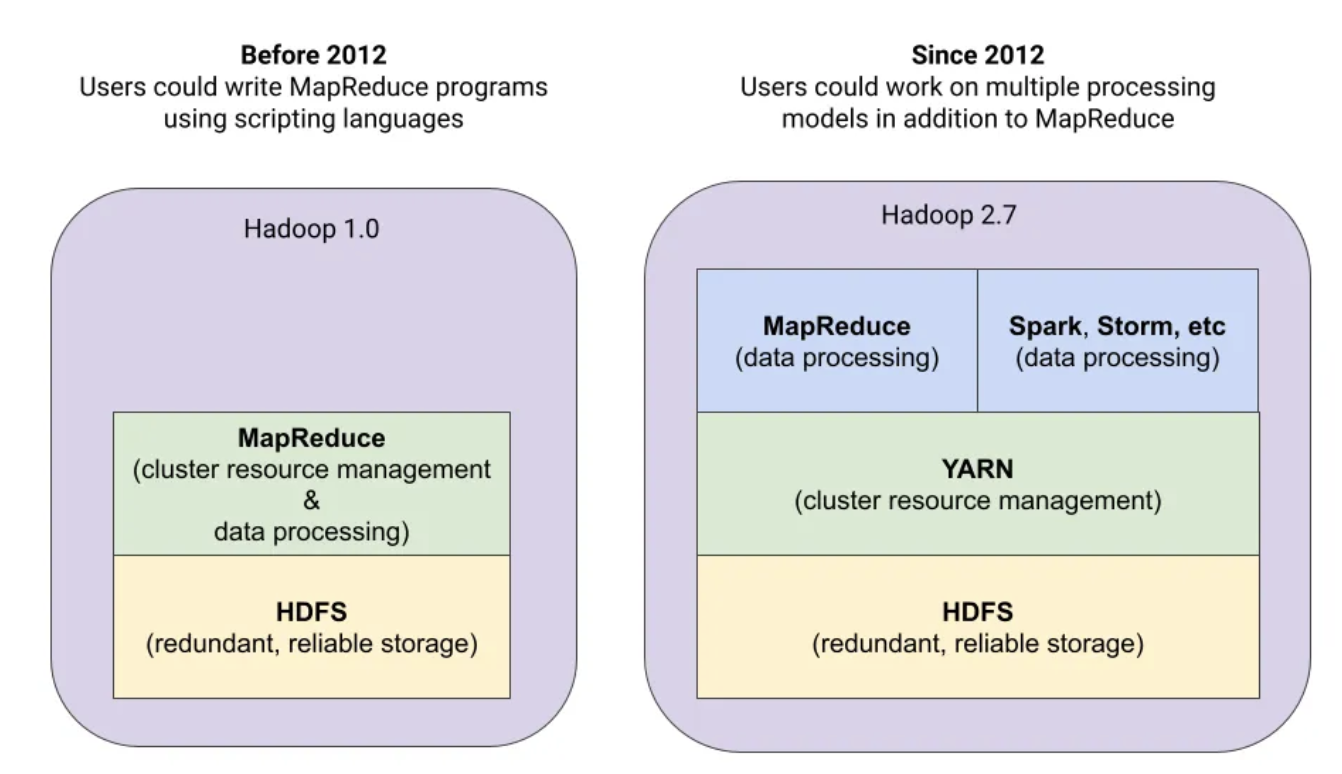
Yarn이 도입되기 전에 하둡같은 경우 맵리듀스를 통해 리소스 관리를 해왔다.이로인해 맵리듀스 작업만 실행하도록 제한되었고 하둡 클러스터에서 다른 유형의 app을 실행하기가 어려워졌다. 그래서 나온 것이 yarn이다.
Yarn의 장점
- 중앙 집중식 리소스 관리
- 유연성
- 향상된 클러스터 활용도
- 동적 리소스 할당을 통해 각 어플리케이션은 다른 어플리케이션에 영향을 주지 않고 성공적으로 실행하는데 필요한 리소스를 얻을 수 있다.
- 비용효율성
- 데이터 이동 감소
Yarn의 구성요소
- Resource Manager
- Application Manager
- Node Manager
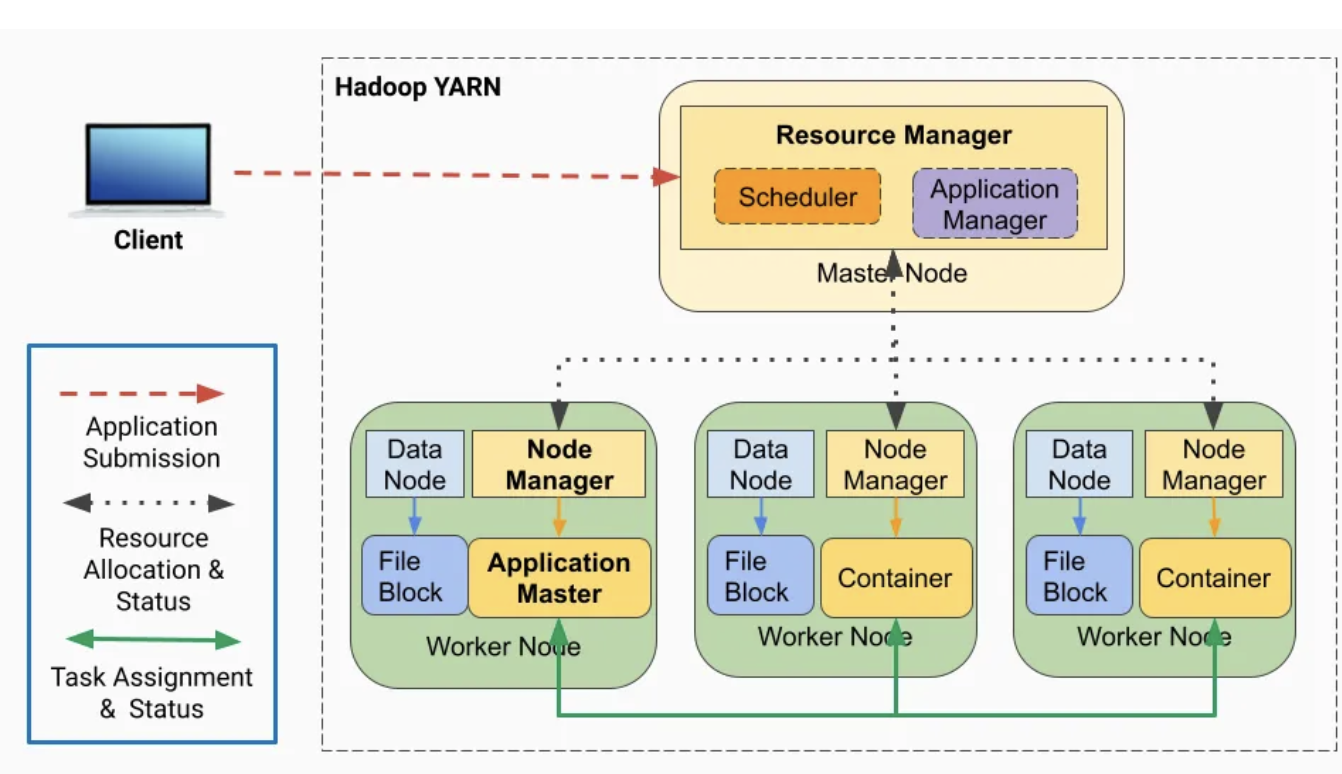
Resource Manager
ResourceManager 는 다양한 작업의 요구 사항에 따라 Hadoop 클러스터 전체에서 CPU, 메모리, 디스크와 같은 리소스를 관리하고 할당하는 역할을 하는 마스터 노드에서 실행되는 Java 프로세스입니다.
- 클러스터 리소스 추적
- 클러스터 상태 모니터링
- 클러스터 자원 할당
- 작업 예약
- 어플리케이션 마스터 관리
RM에는 두가지 요소가 있다.
- 스케쥴러
- application manager
스케줄러
YARN의 스케줄러 는 정의된 정책에 따라 제출된 애플리케이션 사이에서 클러스터의 사용 가능한 리소스를 예약하고 중재하는 역할을 담당합니다.
FIFO 스케줄러: 선착순 접근 방식을 따르는 간단한 스케줄러이며 소규모 클러스터 및 간단한 워크로드에 적합합니다.
용량 스케줄러: 클러스터 리소스를 여러 대기열로 나누는 스케줄러로, 각 대기열에는 예약된 리소스가 있고 다른 대기열에서 사용하지 않는 리소스를 동적으로 활용할 수 있습니다. 대규모, 다중 사용자 환경에 적합합니다.
Fair Scheduler: 일정량 의 예약 용량을 요구하지 않고 허용된 작업 간에 리소스 균형을 공정하고 균등하게 조정하도록 설계된 스케줄러입니다.
application Manager
ApplicationManager는 제출 , 실행 또는 완료된 애플리케이션 목록을 유지 관리하는 인터페이스입니다. 다음을 담당합니다.
작업 제출 처리: YARN에 대한 작업 제출 수락,
ApplicationMaster를 위한 자원 협상: 애플리케이션별 애플리케이션 마스터를 실행하기 위한 첫 번째 컨테이너를 협상하고,
ApplicationMaster의 장애 조치 관리: 실패 시 애플리케이션 마스터 컨테이너를 다시 시작합니다.
App Master
ApplicationMaster 는 Spark 드라이버와 같은 애플리케이션의 주요 기능/진입점을 실행하는 프로세스입니다. 다음을 포함하여 여러 가지 책임이 있습니다.
리소스 요청: 작업을 실행하기 위해 컨테이너를 시작하기 위한 리소스를 얻기 위해 Resource Manager와 협상합니다.
마스터/드라이버 프로그램 실행: 작업 실행 계획을 수립하고, 할당된 컨테이너에 작업을 할당하고, 작업 실행 상태를 추적하고, 진행 상황을 모니터링하고, 작업 실패를 처리하는 스파크 드라이버와 같은 마스터/드라이버 프로그램을 실행합니다.
노드 관리자(NM)
NodeManager는 Hadoop 클러스터의 슬레이브/작업자 노드에서 실행되는 Java 프로세스입니다. 이들은 각 작업자 노드에서 컨테이너와 리소스를 관리하고, 애플리케이션을 위한 안전한 런타임 환경을 제공하며, 효율적이고 유연한 리소스 할당을 허용하는 일을 담당합니다.
노드 상태 보고: 각 노드 관리자는 ResourceManager에 자신을 알리고 주기적으로 하트비트를 보내 메모리 및 가상 코어를 포함한 노드 상태 및 정보를 제공합니다. 오류가 발생하면 Node Manager는 모든 문제를 Resource Manager에 보고하여 리소스 할당을 정상 노드로 전환합니다.
컨테이너 시작: 노드 관리자는 ResourceManager의 지침을 받아 해당 노드에서 컨테이너를 시작하고 지정된 리소스 제약 조건으로 컨테이너 환경을 설정합니다.
컨테이너 관리: 노드 관리자는 컨테이너 수명 주기, 종속성, 임대, 리소스 사용량 및 로그 관리를 관리합니다.
컨테이너
컨테이너는 Hadoop 클러스터의 특정 작업자 노드를 나타내는 추상화인 리소스 할당 단위입니다. 컨테이너는 MapReduce 작업 또는 Spark 작업과 같은 애플리케이션의 작업을 실행하도록 할당됩니다. 각 컨테이너에는 CPU, 메모리, 디스크 공간 등 특정 양의 리소스가 할당되어 있어 제어되고 격리된 환경에서 작업을 실행할 수 있습니다.
client mode
(1) client에서 spark-submit을 통해 작업이 제출됨
(2) client에서 driver가 실행되고 driver는 resource manager에게 작업에 필요한 리소스를 요청
(3) resource manager는 node manager에 작업가능한 공간인 container를 전달받음
이 때 node manager는 container를 대신 시작
resource manager는 컨테이너에 application master를 실행
application master가 리소스를 ressource manager에게 요청하고 resource manager는 데이터 지역성을 고려하여 리소스를 할당
(4) (1)에서 복사되었던 파일들을 HDFS에서 container로 가져와 작업 수행
node manager에 떠있는 application master가 task(executor)를 실행
task들은 작업 상황을 주기적으로 application master에 전달
cluster mode
(1) client에서 spark-submit을 통해 작업이 제출됨
(2) resource manager로부터 지정받은 임의의 node manager가 driver(container)를 수헹
(3) driver는 resource manager에 작업에 필요한 리소스를 요청
(4) resource manager는 node manager에 작업가능한 공간인 container를 전달받음
이 때 node manager는 container를 대신 시작
resource manager는 컨테이너에 application master를 실행
application master가 리소스를 ressource manager에게 요청하고 resource manager는 데이터 지역성을 고려하여 리소스를 할당
(5) (1)에서 복사되었던 파일들을 HDFS에서 container로 가져와 작업 수행
node manager에 떠있는 application master가 task(executor)를 실행
task들은 작업 상황을 주기적으로 application master에 전달
둘의 차이는 spark이 driver를 node manager 안에 두냐 아님 클러스터 밖에 두냐의 차이이다. client 모드는 코드 개발 및 테스트 용도.
대략적인 작동 과정
1단계: 클라이언트는 "spark-submit"을 사용하여 YARN 리소스 관리자에 작업을 제출합니다.
2단계: 작업이 ResourceManager의 스케줄러 대기열에 들어가 실행을 기다리고 있습니다.
3단계: 작업이 실행될 시간이 되면 ResourceManager는 ApplicationMaster를 실행하기 위해 컨테이너를 시작할 수 있는 NodeManager를 찾습니다.
4단계: ApplicationMaster는 드라이버 프로그램(SparkSession/SparkContext를 생성하는 프로그램의 진입점)을 시작합니다.
5단계: ApplicationMaster/Spark는 작업에 필요한 리소스(CPU, RAM, 실행기 수)를 계산하고 리소스 관리자에 실행기를 시작하라는 요청을 보냅니다.
ApplicationMaster는 HDFS 프로토콜을 사용하여 클러스터 내의 파일(블록) 위치를 결정하기 위해 NameNode와 통신합니다.
6단계: 드라이버 프로그램은 실행기 컨테이너에 작업을 할당하고 작업 상태를 추적합니다. -> excutor
7단계: 실행기 컨테이너는 작업을 실행하고 결과를 드라이버 프로그램에 반환합니다. 드라이버 프로그램은 결과를 집계하고 최종 출력을 생성합니다.
