Target
- https://arxiv.org/abs/2401.09417?utm_source=pytorchkr
- Transformer 를 주축으로 이루어진 딥러닝의 아키텍처의 대안을 찾고자 개발자들은 다양한 시도를 진행하고 있었고, 그 중 Mamba가 하나의 대안으로 떠오르고 있음
- 해당 논문은 대안으로 떠오르는 Mamba를 비전 분야에 적용시킨 Visual Mamba(ViM)에 대해 나타내며, 해당 모델은 기존 ViT모델과 어느정도 비등한 성능을 나타냄
키워드
- Mamba
- State-Space Model
- Vision
배경
- 연구 발전에 따라 상태 공간모델 (SSM)에 대한 관심이 높아지고 있음
- 또한 Transformer 를 주축으로 이루어진 딥러닝의 아키텍처의 대안을 찾고자 개발자들은 다양한 시도를 진행하고 있음.
- 그 중 Mamba가 하나의 대안으로 떠오르고 있음
- Mamba가 언어 모델링에 큰 대안으로 떠오르고 있는 만큼, 비전 분야에서도 활용하고자 함.
기본 개념
- Mamba 적용
- Vim 모델은 Mamba를 Encoder에 적용하여 활용
모델 아키텍쳐
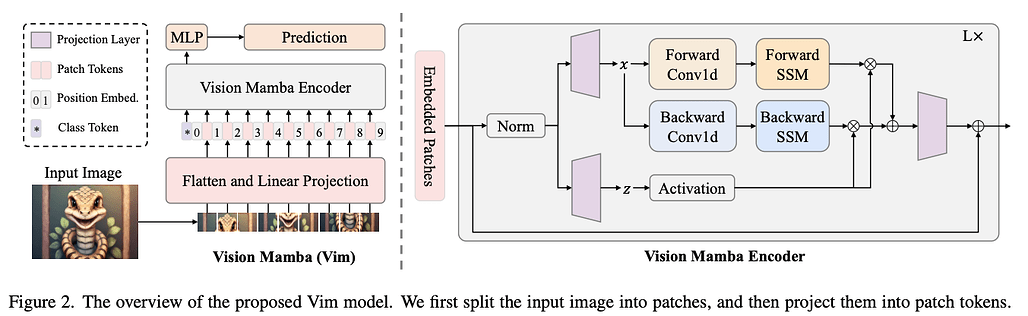
- Overflow
- Input된 이미지를 패치화, Flatten 및 Linear Projection [한 벡터를 다른 벡터의 공간에 표기하는 것]
- 해당 시퀀스들을 대변하는 Class Token 추가 & Position Embedding 진행
- 진행된 과정들을 Vim Encoder 블록에 입력
- Normalize & MLP를 거쳐 최종 결과 도출
- Vision Mamba Encoder
- 임베딩된 패치들을 해당 Encoder에 입력됨.
- Normalize 한 후 차원을 2개로 확장
(x, z) 라 지칭 - x는 Backward & Forward 방향 2가지로 진행
- 1차원 Convolution -> Linear Projection 순서로 진행
- 이후 3개의 Δ값을 생성, Back & Forward 별로 SSM 단계에서 이용
- 이러한 순서를 거쳐 y_forward & y_backward 값이 계산됨
- Z는 Gate 형식으로 이용하며 RNN 방식과 유사하게 y_forward & y_backward를 선택적으로 추출
- 해당 값들을 더하면 최종 Output이 도출됨
모델의 의의 (개인생각)
- Tranformer가 현 시점 가장 많이 이용되는 모델의 백본이자, 성능도 우수함.
- 다만, Transformer의 경우 메모리 효율성 부분에서는 좋지 않다는 점이 단점으로 작용하고 있었음.
- Mamba는 하드웨어 효율성을 어느정도 고려하면서, Transformer와 어느정도 비등한 성능을 나타낸다는 점에서 주목할 수 있다고 보여짐

성장 += 지식