출처
위 리뷰 정리는 유투버 : 나동빈님 영상을 공부하면서 정리 한 글입니다.문제가 될 시 삭제 하겠습니다
출처 : 동빈나 youtube
https://www.youtube.com/watch?v=AA621UofTUA
Transformer 논문
2021년 년 기준으로 현대의 자연어 처리 네트워크에서 핵심이 되는 논문이다. Attention is all you Need
Transformer 특징
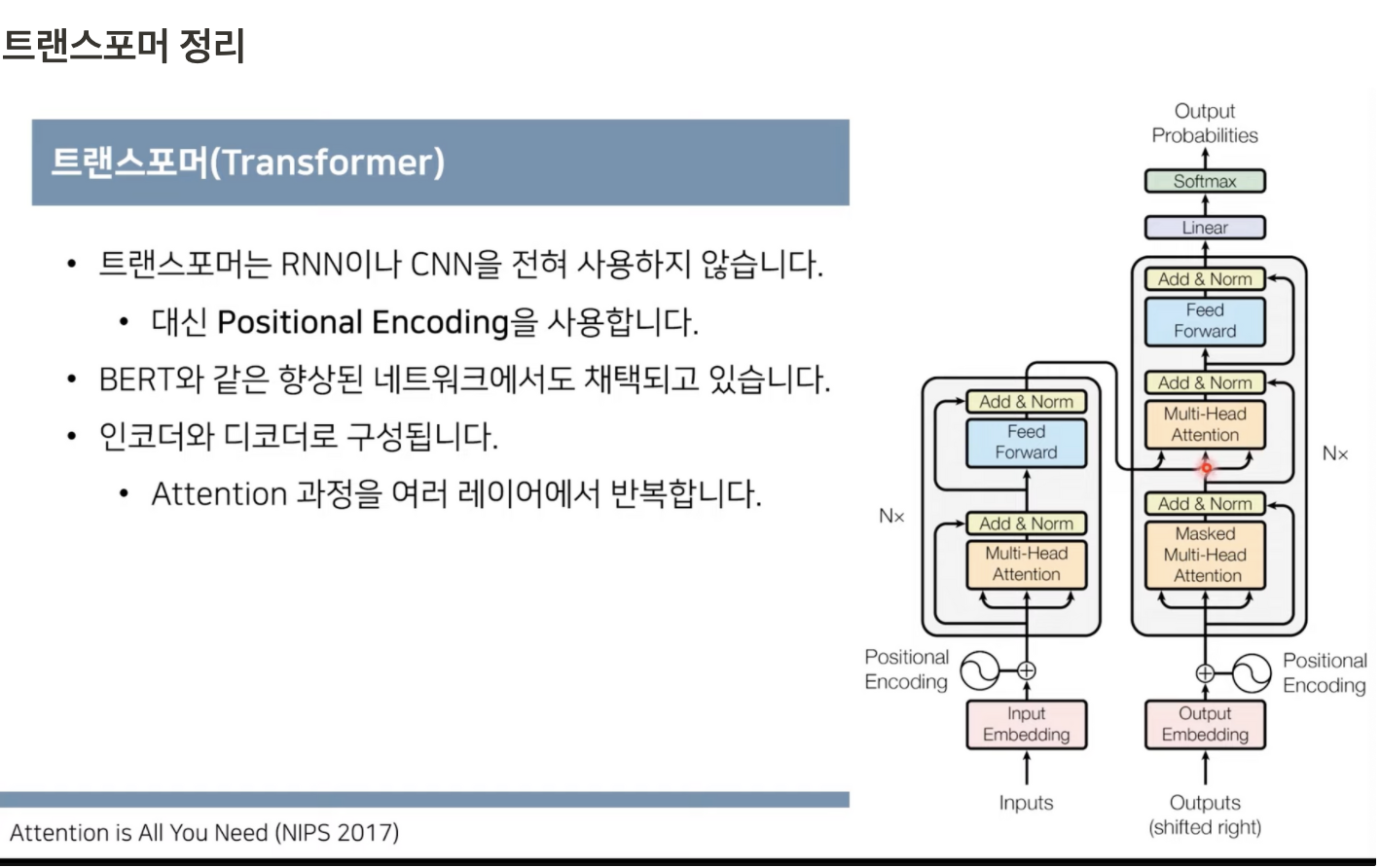
- RNN 이나 CNN 을 전혀 사용하지 않습니다
- 대신 Positional Encoding 을 사용한다
- 인코더와 디코더로 구성 attention 과정을 여러번 반복한다.
동작원리
트랜스포머 이전의 전통적인 임베딩은 다음과 같다.
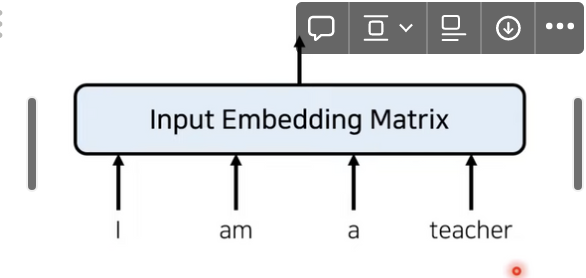
RNN을 사용하지 않으려면 위치 정보를 포함하고 있는 임베딩을 사용해야 한다.
- 이를 위해 트랜스포머에서는 Positional Encoding 을 사용한다
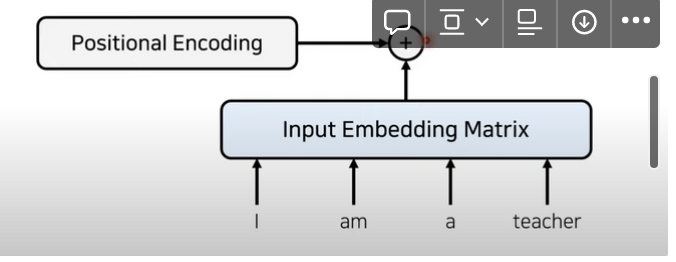
임베딩이 끝난 이후에 어텐션을 진행한다.

성능 향상을 위해 잔여 학습을 사용한다.
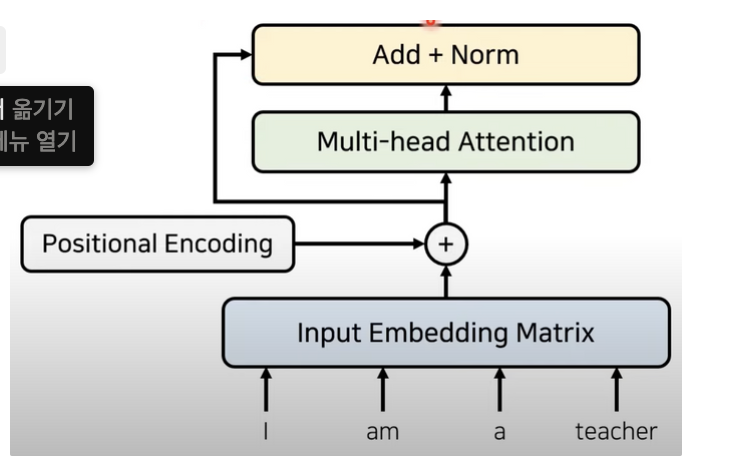
- 특정 레이어를 건너 뛰기 때문에 추가적으로 잔여 된 부분만 학습시킨다(난이도가 낮음)
- 글로벌 옵티마를 찾을 확률이 높기 때문에 잔여 학습을 쓸때 성능이 더 좋아진다.
어텐션과 정규화 과정을 반복합니다.
- 각 레이어는 서로 다른 파라미터를 가진다.
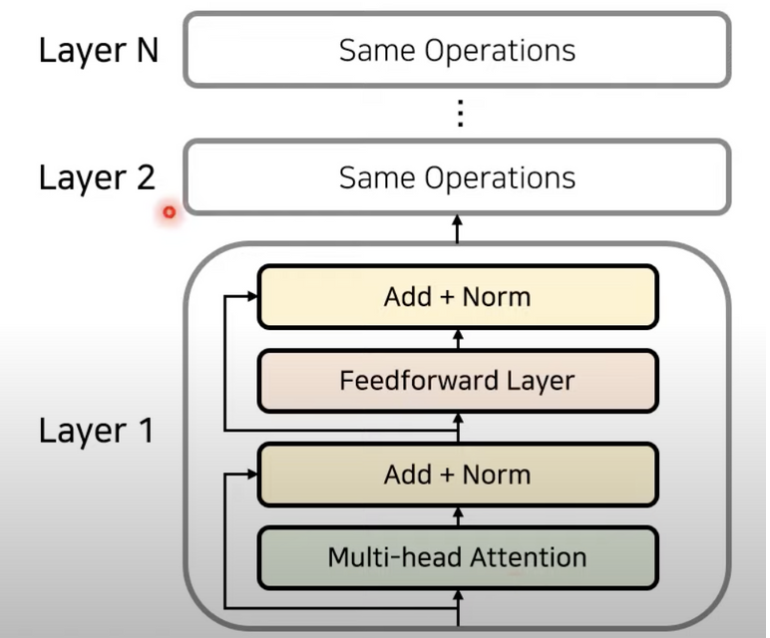
트랜스포머의 동작 원리 : 인코더와 디코더
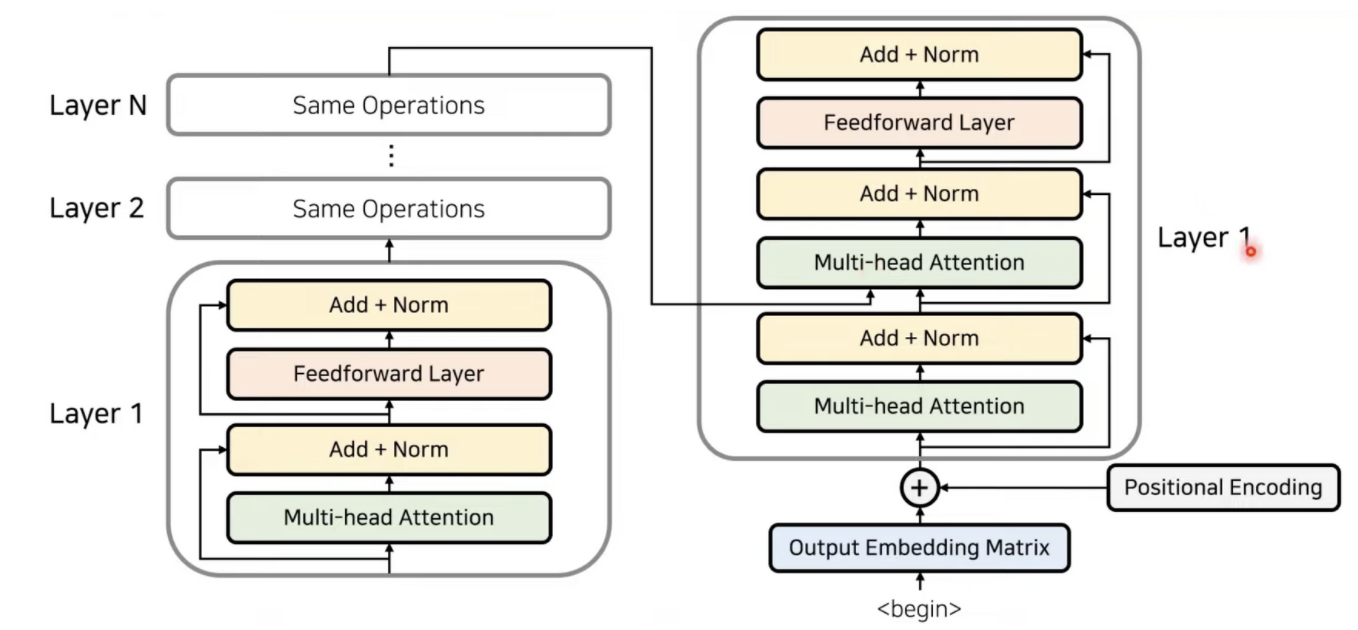
디코더는 셀프 어텐션과 위에는 인코더 / 디코더 어텐션이다.
트랜스포머에서는 마지막 인코더 레이어의 출력이 모든 디코더 출력이 모든 디코드 레이어에 입력됨
n_layers = 4 일때
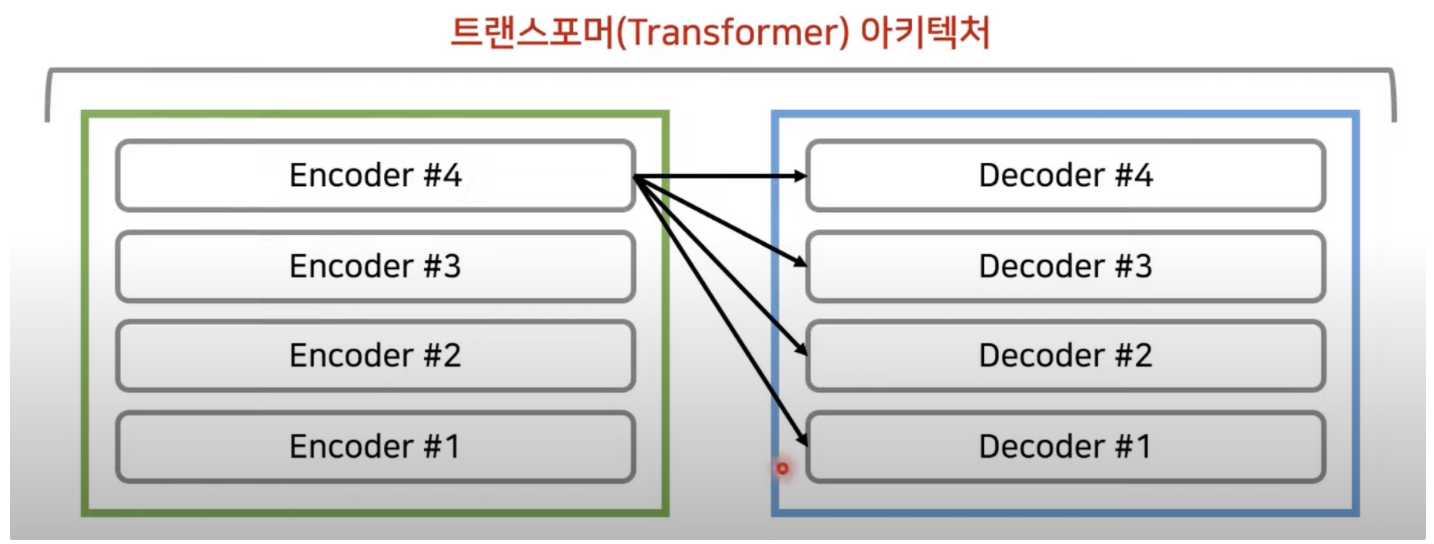
RNN 을 사용하지 않고 인코더와 디코더를 다수 사용한다는게 특징이다.
인코더와 디코더
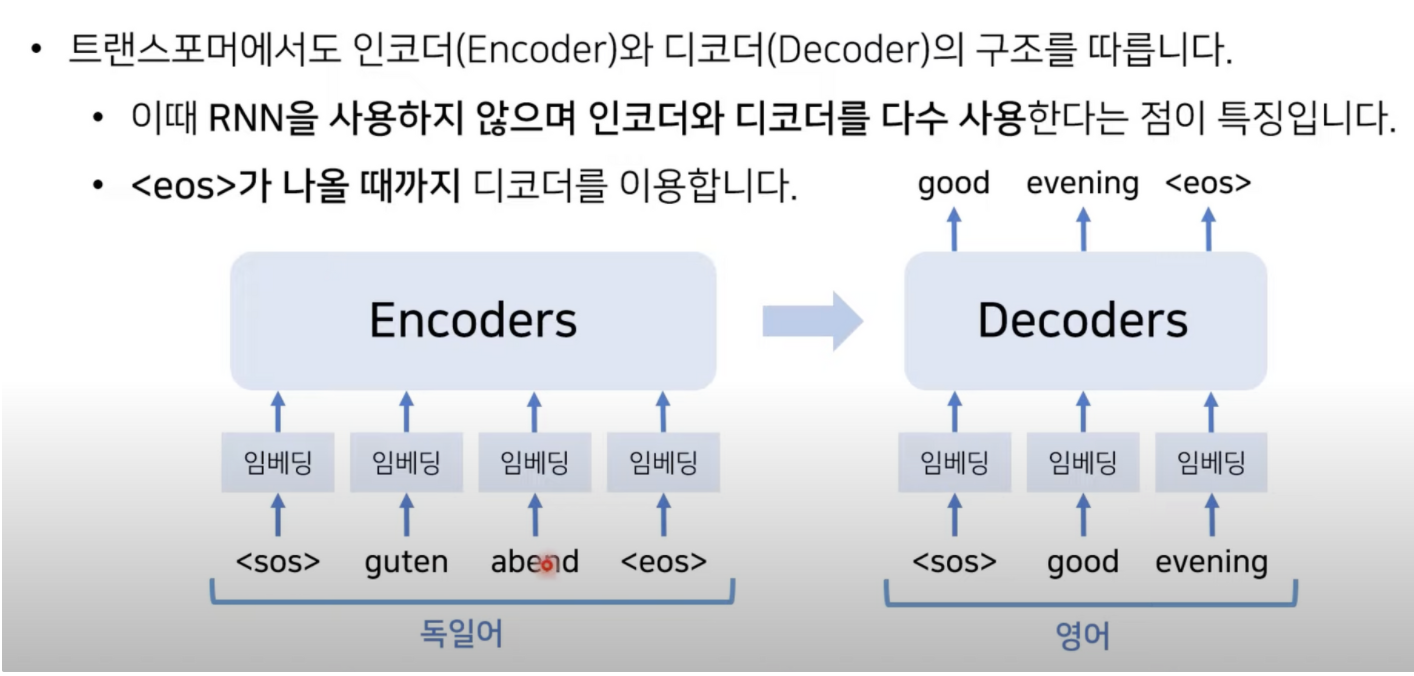
위치의 정보를 rnn 과 다르게 위치의 정보를 한꺼번(입력단어 자체가 한번에 들어간다)에 넣어서 한번에 인코더를 거칠 때 마다 병렬적으로 출력값을 구할수 있기 때문에 계산복잡도가 낮은편이다.
Multi header attention
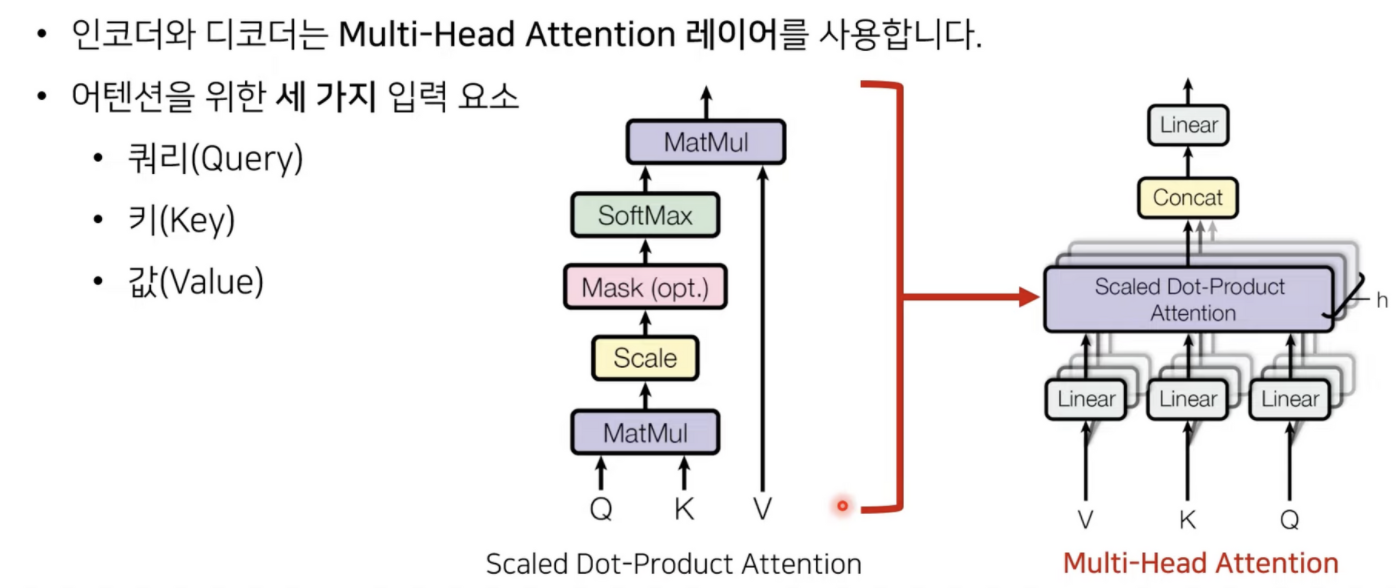
어텐션 메커니즘을 이해해야한다.
어떠한 단어가 다른 단어와 어떠한 연결성을 가지고 있는가?
i 가 쿼리가 되고 i am a teacher 가 key 가 된다.
행렬곱 수행 → 스케일링 → 마스크 → 소프트맥스(0.75, 0.125 ,0.125) → 벨류와 더해준다.
(입력값과 출력값의 디멘전을 같게한다)
attention의 수식

Attention : 쿼리와 키를 곱해서 에너지값을 구해서 소프트맥스 해준다 그과정중에 스케일화 루트 디(베네싱 그래디언트의 문제점을 보완하기 위함)
head : 입력으로 들어오는 리니어레이어에 대해서 쿼리 벨류 키 값을 만든다.
각 헤드의갯수 콘캣 해주어 멀티 헤드를 만들어준다.
트랜스포머의 동작원리 (하나의단어)
쿼리, 키 벨류
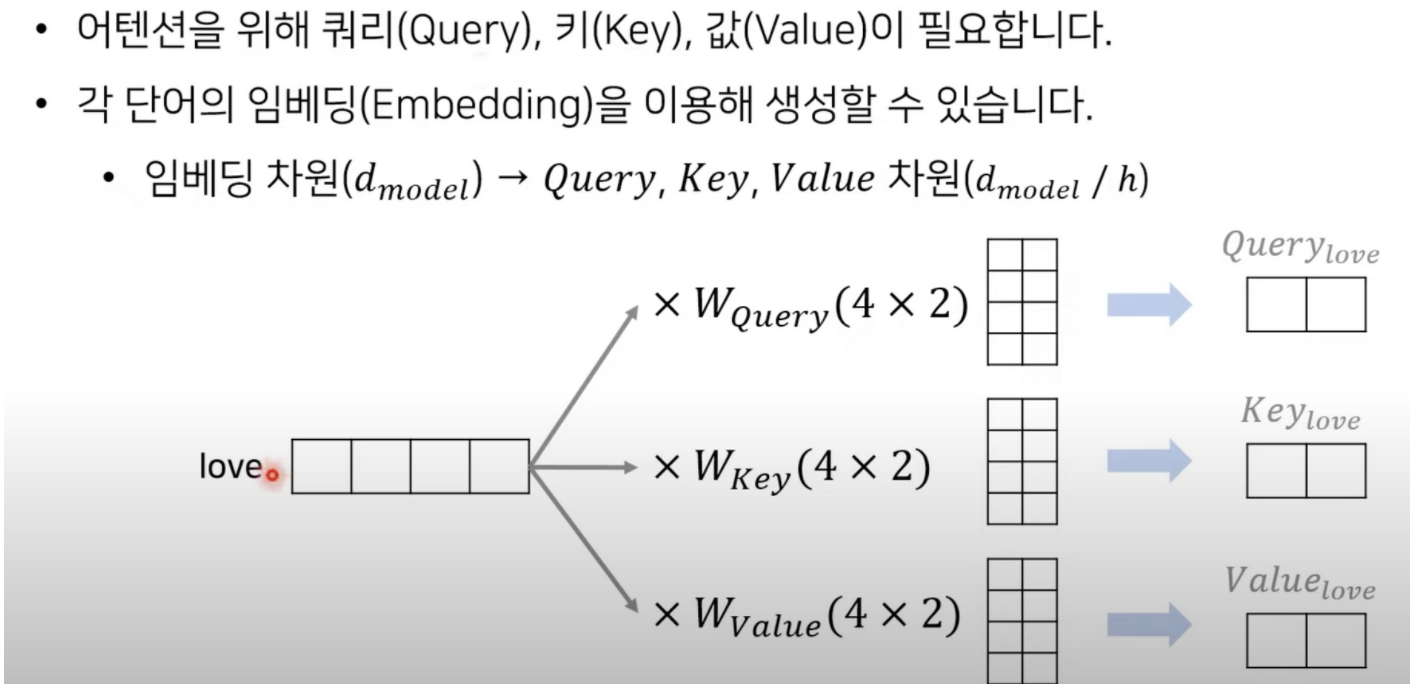
임베딩 모델을 512차원으로 사용한다(논문) 512 / 64
예시는 4/2 이다.
Scaled Dot-Product Attention
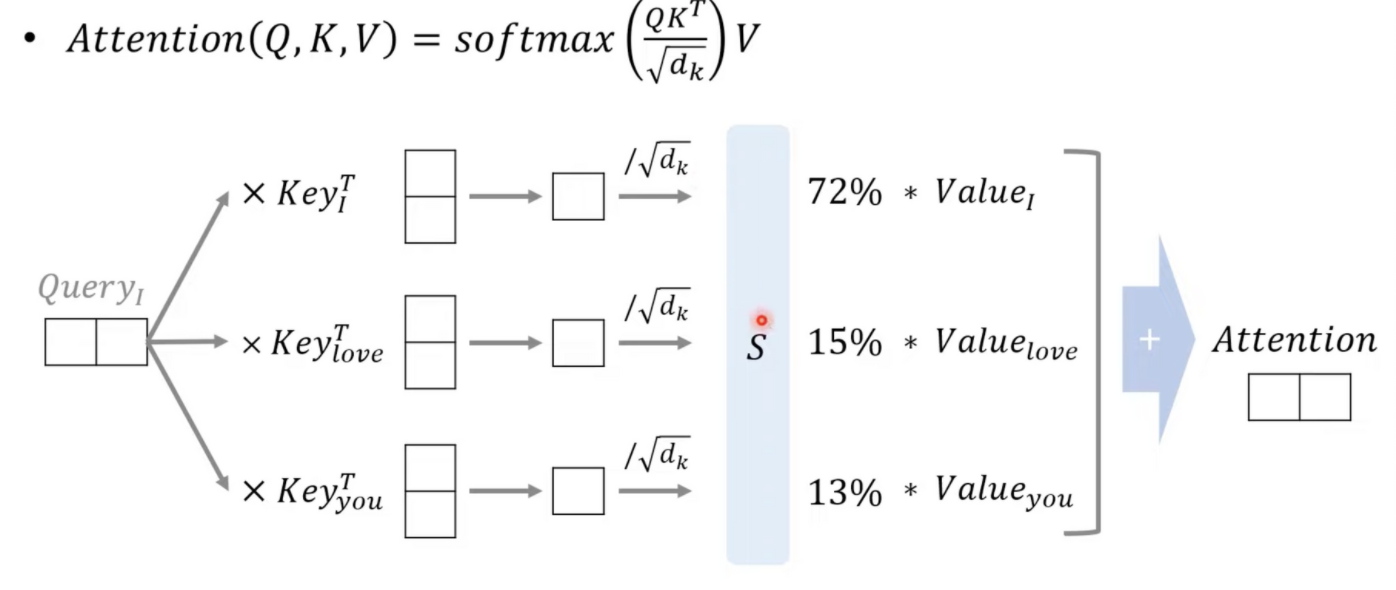
어떠한 가중치를 가지는지 확인을 한다.
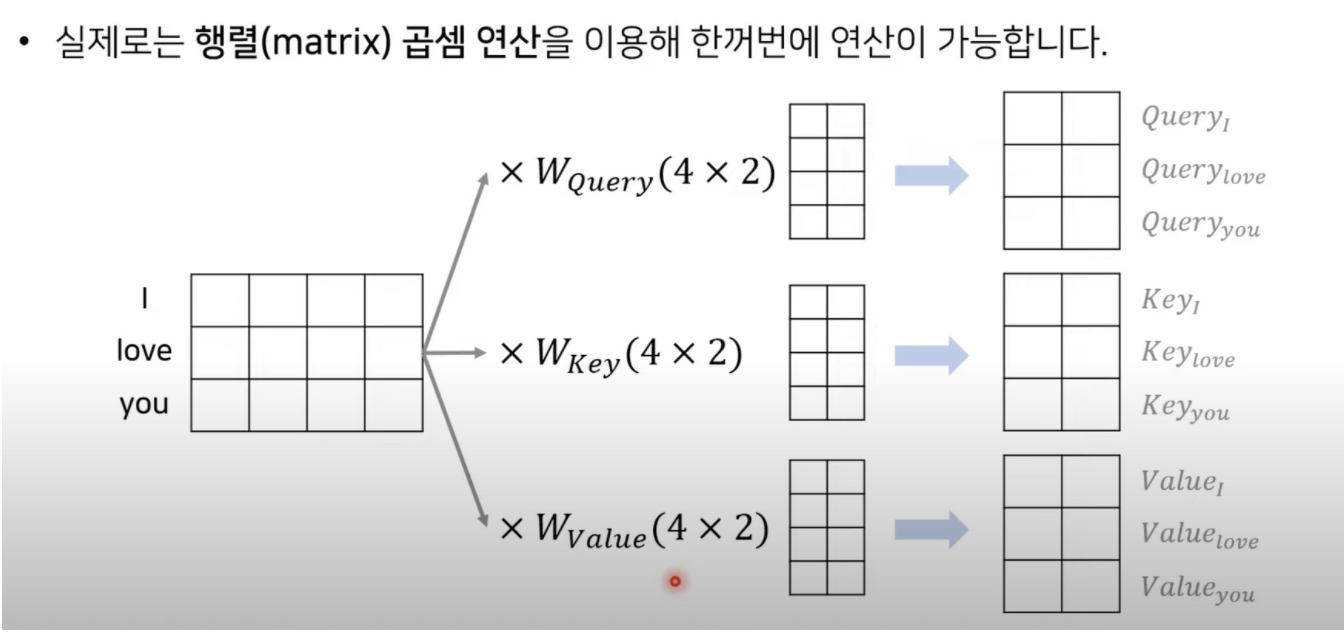
쿼리 , 키 , 벨류가 구해진다.
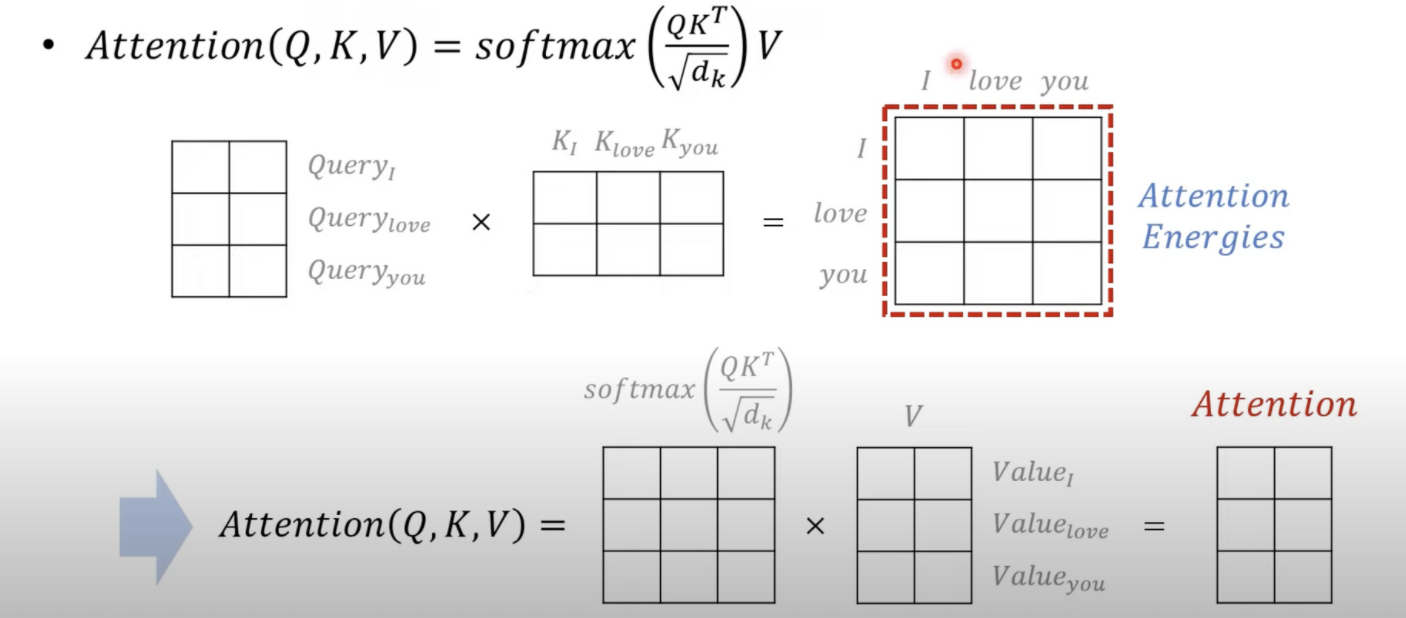
어텐션 에너지가 구해지는데 i , love , you 와 같은 단어의 갯수만큼의 크기를 가진다(행렬)
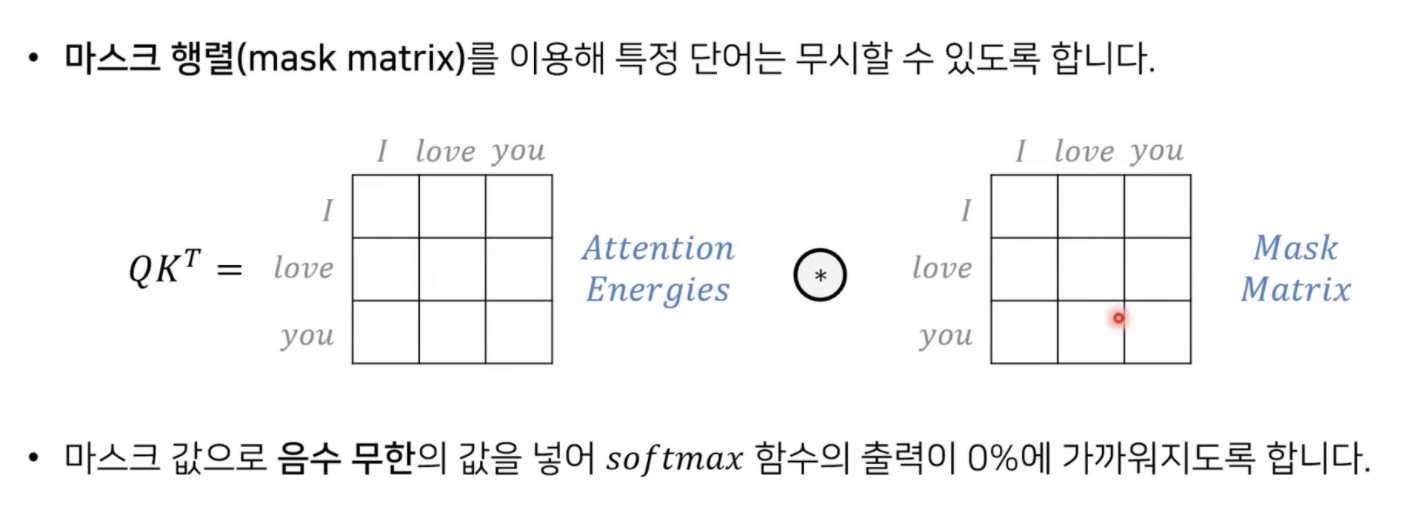
어떠한 단어는 참고하지 않을 수 있게 - 무한이라 하는 소프트맥스를 취하면 거의 0%가 나오게 된다고 한다.
mask matrix를 취하면 특정단어는 무시하고 어텐션을 수행시킨다.
Multi-Head Attention
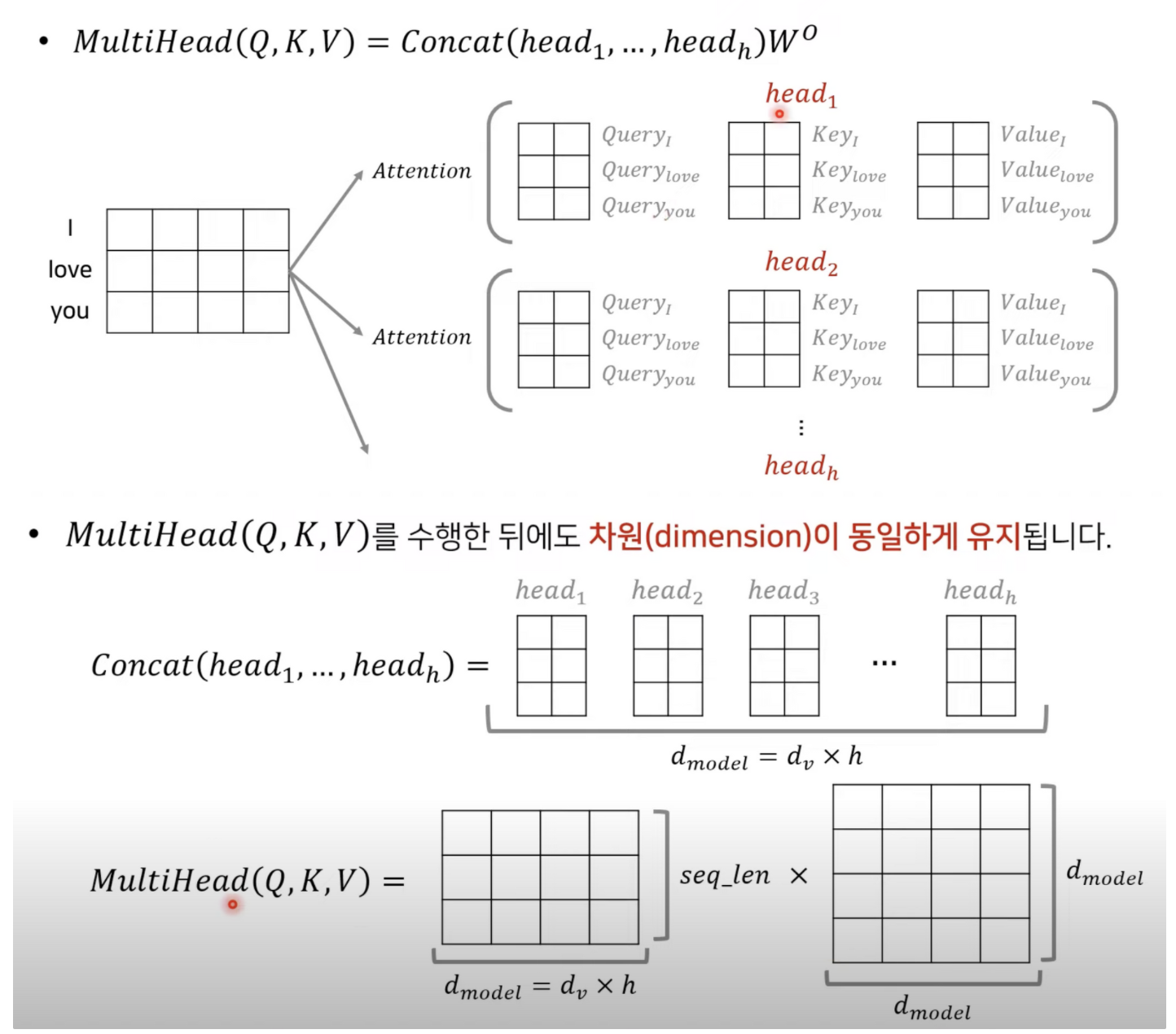
결과적으로 입력디멘전과 출력이 동일해서 차원이 유지되게 된다.
Attention 의 종류
Encoder Self-Attention: 각각의 단어가 서로 어떠한 관계를 가지는지 어텐션을 수행한다.전체 문장간이 관계를 연관있는지 본다.
Masked Decoder Self-attention : 앞쪽에 있던 단어만 참고하도록 각각의 단어들 중 앞쪽의 단어들만 참고해서 치팅 되지 않도록 정상 모델 학습하도록 수행
Encoder-Decoder Attention: 쿼리가 디코더에 있고 키 벨류가 인코더가 있다. 디코더 값에 있는 쿼리 값이 인코더의 키, 벨류 값을 참조한다.
Self-Attention

it 이란 단어는 the , tree , it 에 관련 높은 스코어가 출력 각각의 단어들이 어떤 연관성을 가지는지 시각화 가능
트랜스포머 정리
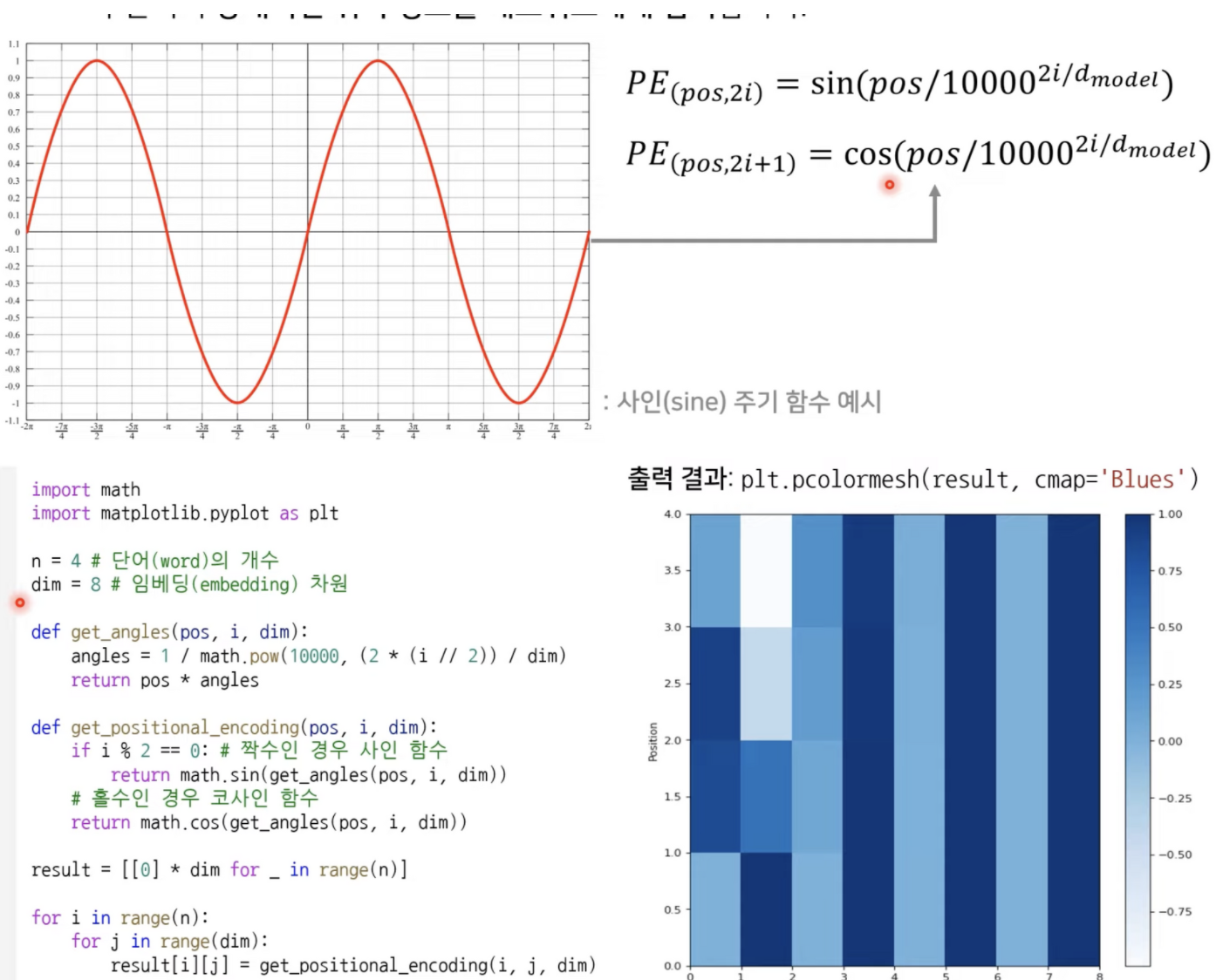
Positional Encoding
각 단어의 상대적인 위치 정보를 네트워크에게 입력한다.
논문 리딩
abstract : 아키 텍처는 전적으로 어텐션기반의 매커니즘이다. 어텐션만 활용하면서 행렬곱을 이용하여 병렬적으로 데이터 처리가 가능하다. 시퀀스데이터를 처리하는 과정에서 성능이 좋다. 구문분석과 같은
- 소개
토큰의 순서정보를 갱신 시키는 모델들이었다. 토큰의 갯수만큼 입력에 넣어야 하기 때문에 병렬적인 처리가 어렵다. 번역에서는 문장의 길이만큼 입력을 수행행야 하기 때문에 메모리, 속도에서 비효율성을 초래 할 수 있다.
attention 소스문장에서 가중치를 구하게해서 출력단어를 보다 효과적으로 생성시킨다. 리커런스한 특성을 아예 없애고 어텐션 매커니즘만 활용해서 행렬곱 , 위치정보가 포함된 시퀀스를 을 처리 가능하다.
- 백그라운드
selft attention :
하나의 시퀀스가 있을때 그 시퀀스에 포함되어있는 위치에 대한 정보가 서로에게 서로가 가중치를 부여해 만들어
레프리젠테이션을 해주는 것이다. I am a boy 가 있을때 각각의 가중치를 부여한다
- 모델 아키텍쳐
rnn 만큼은 단어의 갯수만큼 임베딩의 입력값이 정해진다. 모델을 리커런트로 이용하지 않고 시퀀스의 정보를 한번에 입력에 정보를 주는게 특징입니다.
인코더 : 여러번 인코더 레이어가 중첩되어 사용하며 , 임베딩 벡터의 차원은 512
디코더: 학습난이도를 낮추어 글로벌옵티마를 찾을수 있도록 모델을 설계했고, 디코더의 셀프어텐션 마스크를 씌워서 마스크가 붙은형태로 멀티헤더 어텐션을 사용하게 할 수 있도록 사용
Scaled Dot - Product Attention
- query → key 에 대해서 행렬곱을 함 (Matmul)
- 소프트맥스에 들어가기 위해 Scale 을 해주는데 key의 차원의 루트를 씌운다
- mask 벡터는 필요할때 사용
- 소프트맥스를 취해서 각각의 키에대해서 중요도의 값을 확률의 형태로
- 벨류와 그 형태 값을 구해서 attention value 값을 구한다
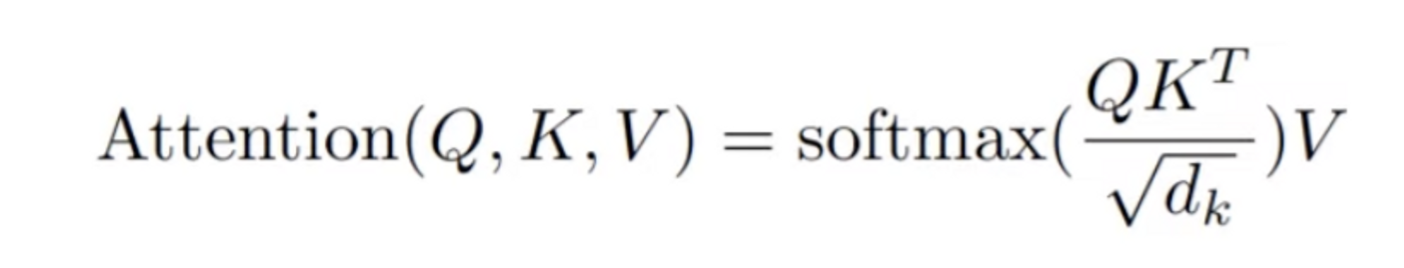
쿼리와 키를 곱해버린다. Dot - product attention 을 수행하는게 효율적이었다.
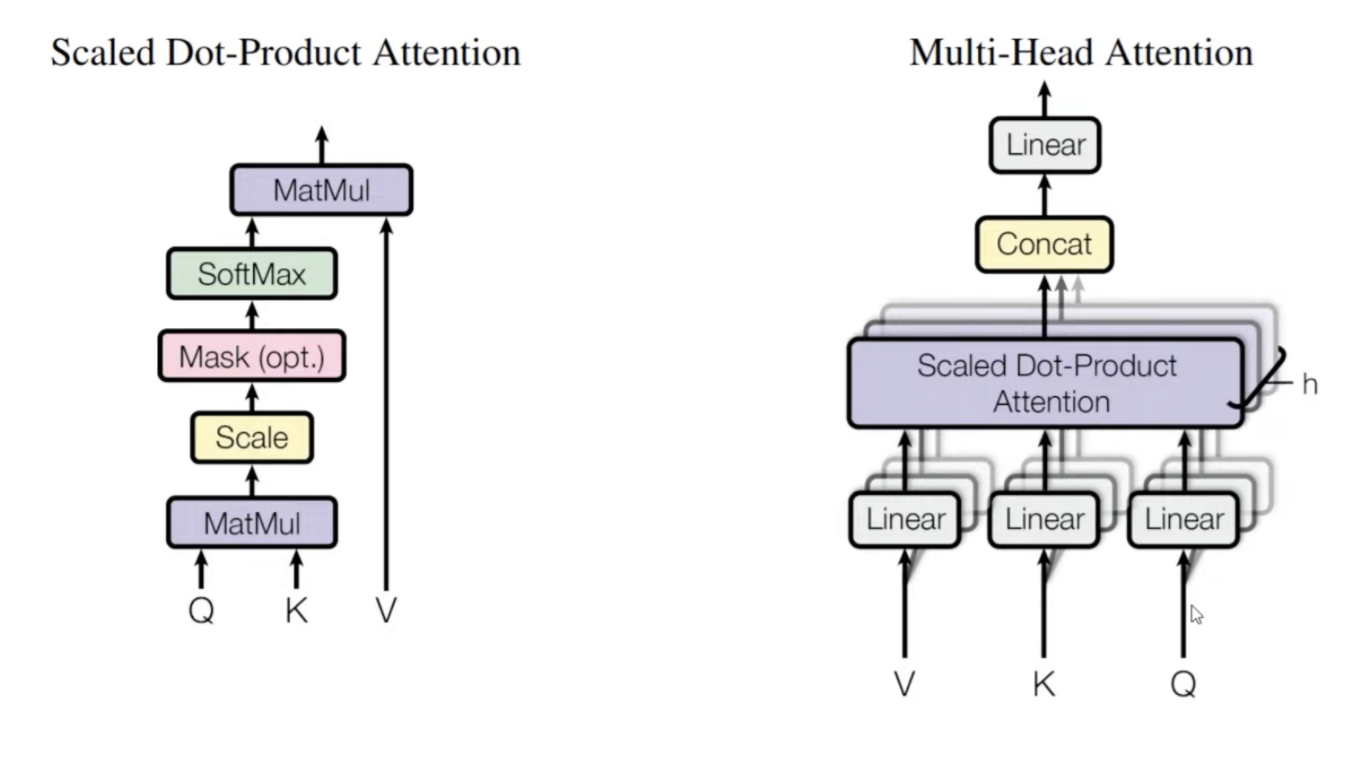
Multi-Head attention
입력값이 들어왔을때 v, k ,q 에 대해 들어오면 임베딩 차원을 쿼리, 키, 벨류의 차원으로 바꿔주고 어텐션을 하고
기존의 스케일드 닷과 콘캣처리해서 같은 차원이 되도록 묶어준다. 입 출 디멘전은 같다.
헤드가 여러개란 의미다. 각각의 헤드의 값을 어텐션을 수행해 이어붙힌다.
어텐션은 어디서 쓰이냐?
셀프 어텐션 : 쿼리 = 키 = 벨류 인코더 파트에서 사용된다.
인코드 디코드 어텐션 : 디코드에서 씀 , 출력 단어를 만들기 위해 어떤단어에 초점을 맞추면되는지 계산하는과정
정형파 함수를 사용했을때 보다 성능이 좋아진다?
셀프어텐션이 왜 유리한가 : 3가지의 장점
- 각각의 레이어마다 계산복잡도가 줄어든다
- 리커런트가 없애면서 병렬 처리
- 롱 레인지 디펜던스도 잘 처리할 수 있다
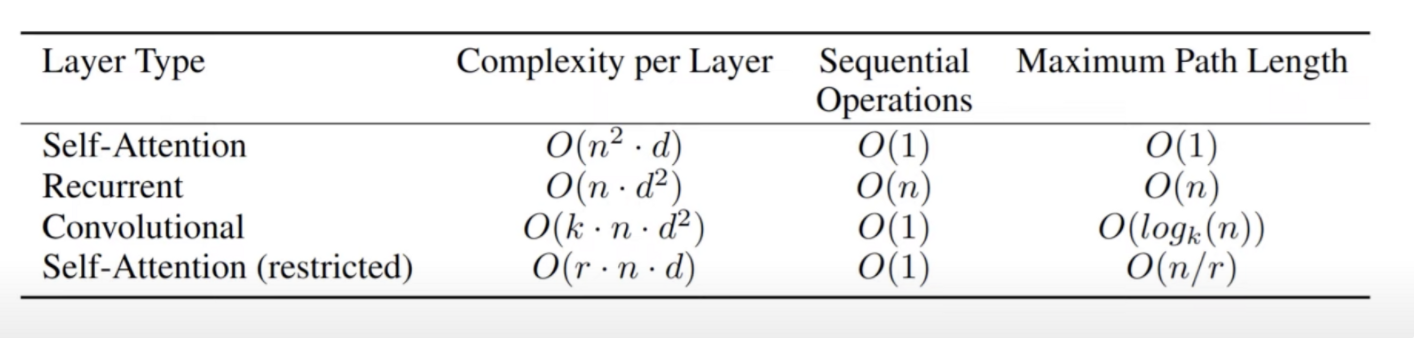
O(1) 한번에 처리가 가능하다.
n은 단어의 갯수 이기 때문에 n2 d가 n d2 보단 더 작기 때문에 더 효율적이다.
후기 : 정말 어렵다 NLP 논문 자체도 난이도가 엄청 올라간거 같다 내가 이걸 그냥 혼자 해석한다..상상이 안감.. 나동빈님 감사합니다. 그래도 절반 이상은 이해한거 같다.
