임베딩 - Bag of words
단어 빈도를 이용하는 방법
- 단어 사전을 미리 구축 → 무작위로 corpus 내에 단어를 꺼내서 라벨을 부여
- 문장 속 단어 빈도를 표시한다
장점
쉽고 직관적이다 문장을 숫자로 변환
단어 빈도를 기반으로 문서 유사도를 파악 할 수 있다.
단점
단어의 빈도만 고려할 뿐 순서 고려 x
세상에는 단어가 너무 많다.
단어가 늘어나면 배열의 크기가 10만개 ~ 100만개로 커지지만, 대부분의 값은 0이다
—> One Hot Vector 와 같은 문제가 일어난다.
CODE
docs = ['오늘 동물원에서 원숭이를 봤어',
'오늘 동물원에서 코끼리를 봤어 봤어',
'동물원에서 원숭이에게 바나나를 줬어 바나나를']
def BagOfWords(docs):
# 띄어쓰기 단위로 토큰화
doc_ls = [ doc.split() for doc in docs]
# 각 고유 토큰에 인덱스를 지정
word2idx = defaultdict(lambda : len(word2idx))
for doc in doc_ls :
for token in doc:
word2idx[token]
# BoW 생성 -> 크기가 어떻게 될까요? row # : 문장개수 & col # unique한 token의 개수
Bow_ls = []
for i, doc in enumerate(doc_ls) :
bow = np.zeros(len(word2idx), dtype=int)
for token in doc :
token_idx = word2idx[token] # 딕셔너리에서 인덱스 조회
bow[token_idx] += 1 # 토큰의 위치 (columns) += 1
Bow_ls.append(bow)
return word2idx, Bow_ls 시각화
sorted_vocab = sorted((value, key) for key, value in word2idx.items()) #인덱스에 따라 정렬
vocab = [v[1] for v in sorted_vocab]
for i in range(len(docs)):
print("문서{} : {}".format(i, docs[i]))
pd.DataFrame([BoW_ls[i]], columns = vocab)단어의 순서를 고려하지 않은 BOW
docs = ['나는 양념 치킨을 좋아해 하지만 후라이드 치킨을 싫어해',
'나는 후라이드 치킨을 좋아해 하지만 양념 치킨을 싫어해']
이처럼 결과를 출력하면 둘다 동일하게 피처값이 출력이 된다.
하지만 이를 보완 및 하드코딩의 어려움을 보완하고자 누가 사이킷런에 만들어 놨다 !!!
하드코딩 !!!!!!!!!!!!으
사이킷런을 통한 카운터벡터라이즈
docs = ['오늘 동물원에서 원숭이를 봤어',
'오늘 동물원에서 코끼리를 봤어 봤어',
'동물원에서 원숭이에게 바나나를 줬어 바나나를']
from sklearn.feature_extraction.text import CountVectorizer
# 객체생성
count_vect = CountVectorizer()
# 변환하기
BoW = count_vect.fit_transform(docs) #핏 트랜스폼
BoW.toarray()[0]
# 시각화하기
vocab = count_vect.get_feature_names()
for i in range(len(docs)) :
print("문서{} : {}".format(i, docs[i]))
pd.DataFrame([BoW.toarray()[i]], columns=vocab)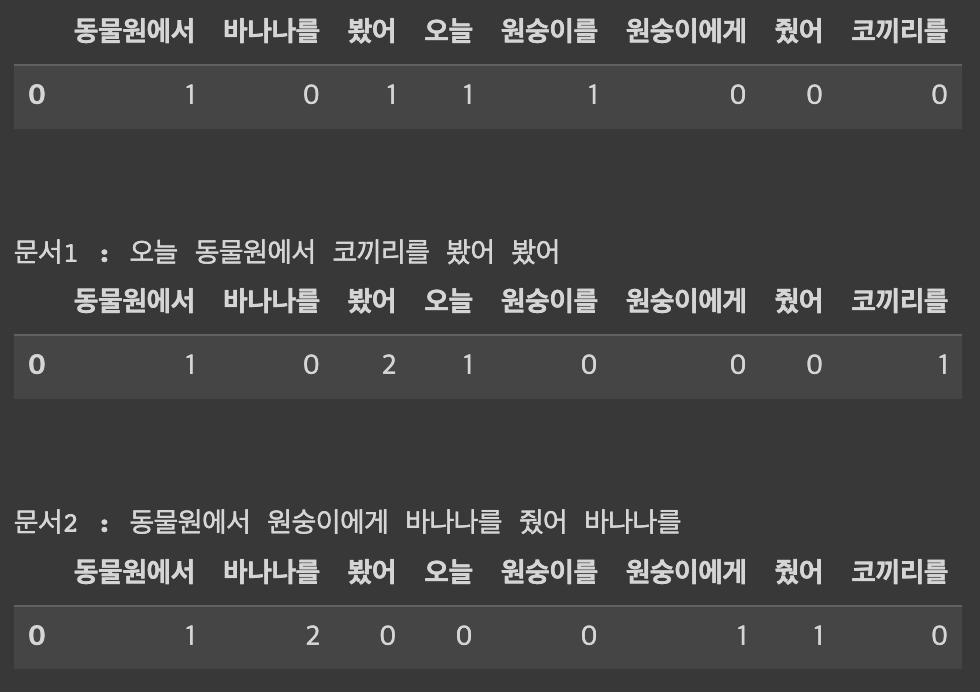
https://intrepidgeeks.com/tutorial/n422-natural-language-processing-word-dispersion

AI engineer