
원핫 인코딩을 한다는 것은?
RED, GREEN, BLUE → Label Encoding (0, 1, 2)→ One-Hot Encoding
ex) bias 때문에 편견이 생길 수 있다. DATA bias → Model bias
단점 : 차원크기의 문제, 의미를 담지 못하는 문제
#데이터가 있는 리스트 선언
word_ls = ['호날두','메시','김덕배','음바페']
# key 와 word를 담을 빈 딕셔너리 선언
word2idx
for i in range(len(set(word_ls))):
word2idx[word_ls[i]]=i
파이썬 함수 defaultdict
from collections import defaultdict
딕셔너리에 미리 키와 인덱스를 설정해주어야 하는데 초깃값 설정 개념의 함수다
dic_b = defaultdict(list)
dic_b['a'].append('우디')
dic_b
새로운 키를 입력과 동시에 초기화 시켜주는 방법
defaultdict를 이용한 원핫인코딩
import numpy as np
word_ls2 = ['호날두','메시','김덕배','음바페']
def one_hot_encoder(word_ls2):
word2idx_2 = defaultdict( lambda : len(word2idx_2))
# {단어: 인덱스}
for word in word_ls2:
word2idx_2[word]
# one hot vectors 로 만드는 작업
one_hot_vecotors = np.zeros((len(word_ls),len(word2idx_2)))
for i, word in enumerate(word_ls):
index = word2idx[word]
one_hot_vectors[i, index] = 1
return one_hot_vectors또다른 방법
word2idx={}
# set 중복제거 set() - [사과,사과,원숭이, 바나나] 사과의 중복을 제거
for i in range(len(set(word_ls))):
word2idx[word_ls[i]]=i
word2idx
for i, k in enumerate(word2idx):
word2idx[k]=i
word2idx라벨 인코딩하기
from numpy import array
from numpy import argmax
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
# 라벨 인코더 객체 만들기
label_enc = LabelEncoder()
# 변환하기
int_enc = label_enc.fit_transform(values)
print(int_enc)One hot Encoding
# 원핫인코더 객체 생성하기
onehot_enc = OneHotEncoder(sparse=False) #내용물 확인 false 배열을 확인가능
# 배열 형변환하기
temp = values.reshape(len(values), 1) # n:1 matrix로 변환 2차원 배열로 바꿈
print(temp)
# 배열 원핫인코딩 적용하기
oh_output = onehot_enc.fit_transform(temp)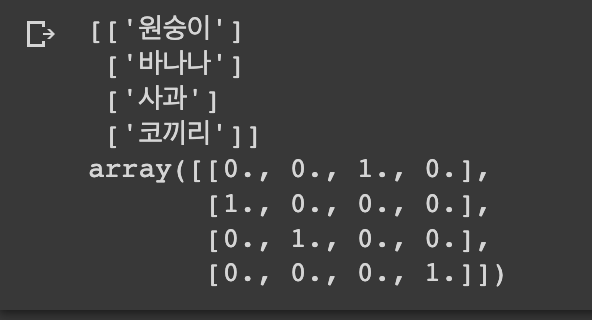
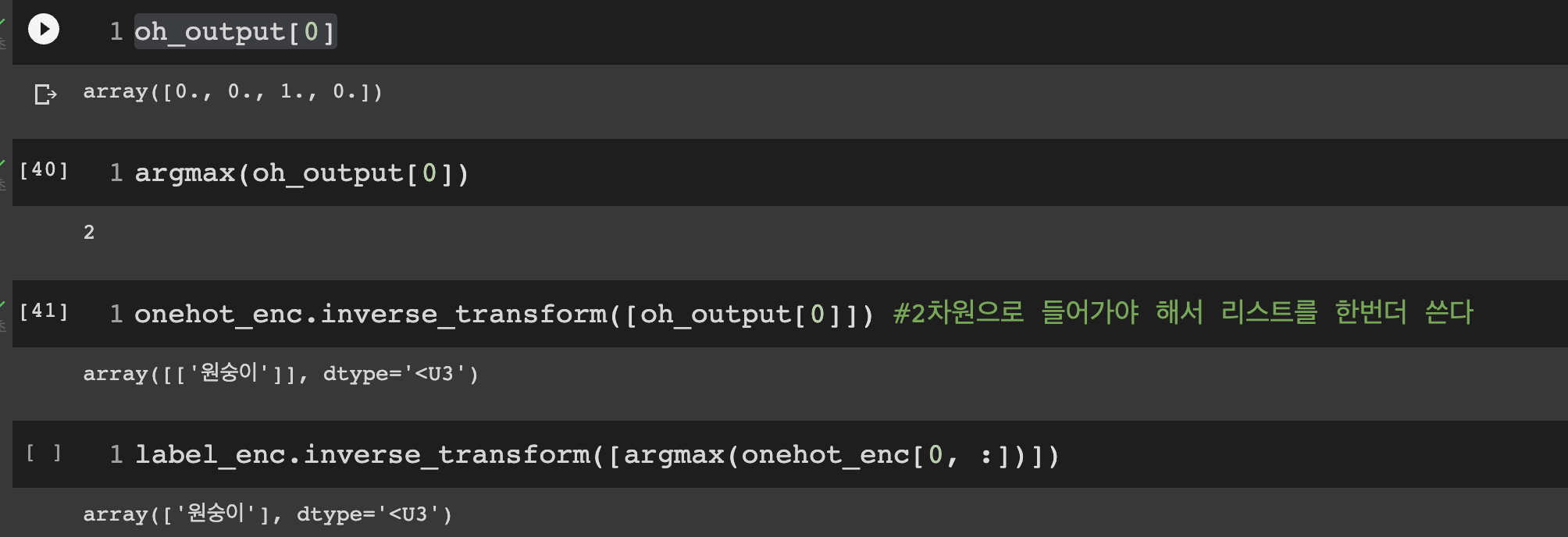
- pythom numpy 기본 문법 공부를 해두어야 한다.

AI engineer