
ChatGPT와 같은 GPT 기반의 언어모델이 작성한 글을 탐지할 수 있는, 2023년 1월에 나온 따끈따끈한 모델인, DetectGPT📡 에 대한 논문입니다.
최대한 논문의 모든 내용을 세세하게 읽고 풀번역 수준으로 리뷰하고자 하였습니다. 감사합니다 :)
Paper : https://arxiv.org/pdf/2301.11305.pdf
Code : https://ericmitchell.ai/detectgpt/
Instagram Review :
Abstract
(배경 & 문제) LLM(Large Language Model)이 작성한 문장의 유창함과 사실적 지식은 텍스트가 기계에 의해 작성되었는지 여부를 감지하는 시스템의 필요성을 높였습니다. 실제로 ChatGPT의 등장 이후 학생들은 LLM을 사용하여 텍스트 작성 과제를 할 수 있게 되었으며, 이로 인해 선생들은 학생의 학습 성취도를 정확하게 평가할 수 없게 되었습니다.
(해결) 본 논문에서는 먼저 LLM을 통해 작성된 텍스트가 모델의 로그 확률 함수(Log Probability Function)의 음의 곡률 영역을 차지하는 경향이 있음을 보여줍니다. 그 다음, 이 관찰을 활용하여 주어진 LLM에서 이러한 경로가 생성되는지 여부를 판단하기 위한 새로운 곡률 기반 텍스트 판별 기준을 정의합니다.
(방법론 & 모델) 이 논문에서 DetectGPT라고 부르는 이 방법론은 별도의 분류기를 훈련하거나, 실제 또는 생성된(Generated) 구절의 데이터를 수집하거나, 생성된 텍스트에 명시적으로 워터마킹을 진행할 필요도 없습니다. 이 방법론을 오직 파악하고자 하는 모델에 의해 계산된 로그 확률(Log Probability)과 다른 일반적인 사전 훈련된 대규모 언어 모델이 생성한 구절의 랜덤한 Perturbation만을 사용합니다.
(결과 & 평가) 본 연구를 통해 우리는 DetectGPT가 모델이 생성한 글을 탐지하기 위한 기존 제로샷(Zero-Shot) 기반 방법보다 뛰어나다는 것을 발견하였습니다. 특히 20B개의 매개변수를 가지는 GPT-NeoX에 의해 생성된 가짜 뉴스 기사의 탐지 Task에서 기존 AUROC 기준 0.81 정도에서 0.95로 큰 성능 향상을 가져왔습니다.
1. Introduction
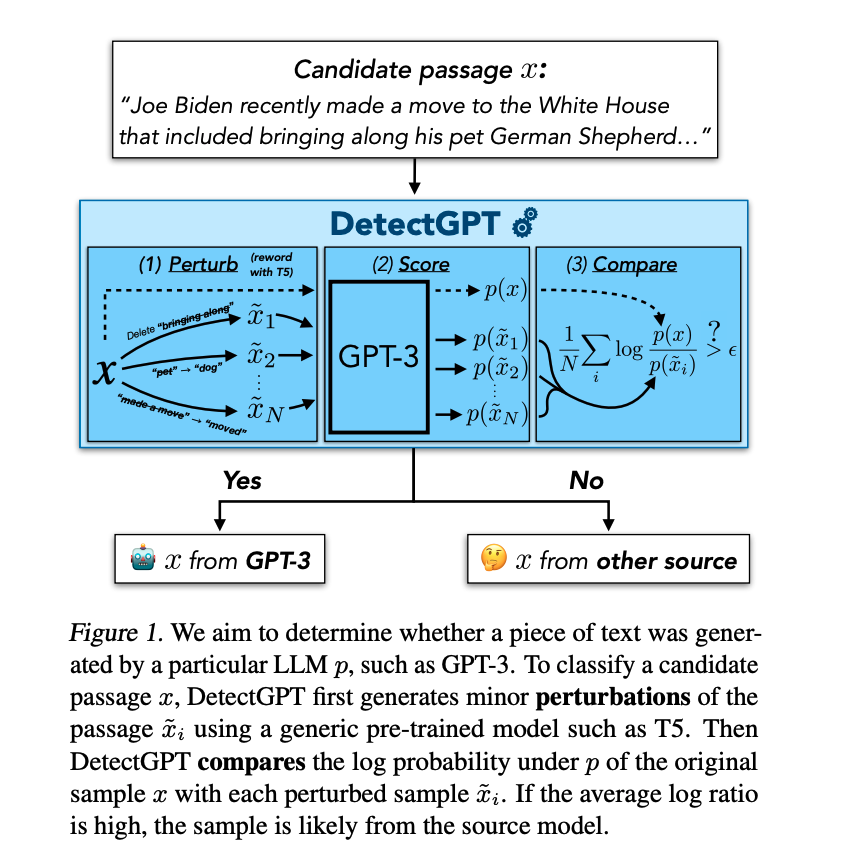
LLM(Large Language Model)은 다양한 사용자 쿼리에 대해 매우 유창한 응답을 생성할 수 있는 것으로 입증되었습니다. GPT3(Brown et al., 2020), PaLM(Chowdhery et al., 2022), ChatGPT(OpenAI, 2022)와 같은 모델들은 과학, 수학, 역사 및 시사, 사회적 이슈와 같은 다양한 분야에 대한 사용자의 복잡한 질문에 설득력 있는 답변을 할 수 있는 것으로 세상을 놀라게 했습니다.
최근 일부 연구에서 설득력 있게 보이는 LLM 생성 응답이 종종 잘못된 것으로 밝혀지기도 했지만(Lin et al., 2022), 이렇게 인공지능이 작성한 텍스트는 어떤 지점, 예를 들어 대학생들 에세이 쓰기나 저널리즘,에서 인간의 노동을 대체할 수 있다는 점에서 여전히 매력적입니다.
그러나 LLM의 이러한 적용은 다양한 이유로 문제가 있습니다. 인공지능이 생성하는 표준 이상의 텍스트들은 선생들로 하여금 공정한 학생 평가를 어렵게 만들고, 학생들의 학습을 저해하며, 때로는 설득력 있지만 부정확한 뉴스 기사를 확신시킵니다. 불행하게도, 우리 인간은 기계가 생성한 텍스트와 인간이 작성한 텍스트를 분류할 수 없습니다. 관련 실험(Gehrmann et al., 2019) 결과, 인간은 우연보다 약간 나은 정도로만(ㅠㅠ) 기계가 생성한 텍스트를 탐지해낼 수 있었습니다. 따라서 많은 연구자들이 인간이 인식하기 어려운 신호(생성된 텍스트의 어떠한 특징)를 식별할 수 있는 자동 탐지 방법을 고려하게 되었습니다. 아마 이러한 방법들은 교사들과 뉴스 독자들에게 그들이 소비하는 텍스트가 인간에 의해 작성되었다는 확신을 가지는데 더 많은 자신감을 줄 수 있으리라 예상합니다.
이전 연구(Jawahar et al., 2020)에서와 같이 본 연구는 이진 분류의 형태로 기계 생성 텍스트를 탐지하는 문제를 연구하였습니다. 구체적으로, 본 연구는 후보 문단이 대규모 언어 모델에 의해 생성되었는지 여부를 분류하는 것을 목표로 합니다. 여러 선행 연구들에서 기계가 생성한 텍스트를 감지하기 위해 새로운 NN을 학습시키는 방법을 다루었지만, 이러한 접근 방식은 학습된 주제에 지나치게 오버피팅되는 경향이 있을 뿐만 아니라, 새로운 언어 모델이 출시될 때마다 이를 탐지하는 모델을 새로 학습시켜야 한다는 것을 포함한 여러 단점이 있었습니다. 따라서 본 연구는 어떤 종류의 Fine Tuning이나 Adaptation 없이 소스 모델 자체를 사용하여 자체 샘플을 탐지하기 위해 Zero-Shot Learning을 고려하였습니다. 기존에 제로샷 기반 기계 생성 텍스트 감지를 위한 일반적인 방법은 생성된 텍스트와 임계값의 토큰 당 평균 로그 확률(Average per-token Log Probability)을 평가하는 것이었습니다.(Solaiman et al., 2019; Germann et al., 2019; Ipolito et al., 2020) 그러나 탐지에 대한 이 방법론들은 후보 문단에 대한 중요한 정보를 포함할 수도 있는 문단 주변의 학습된 확률 함수를 무시한다는 점에서 문제가 있었습니다.
이에 따라 이 논문에서는 간단한 가설💊을 제시합니다. 모델이 생성한 텍스트의 사소한 재작성(trivial rewrites)은 원래 샘플보다 모델에서 로그 확률이 낮은 경향이 있는 반면, 인간이 작성한 텍스트의 사소한 재작성은 원래 샘플보다 더 높거나, 혹은 더 낮을 수 있다는 것입니다.
즉, 인간이 작성한 텍스트와 달리 모델이 생성한 텍스트는 로그 확률 함수가 음의 곡률을 갖는 영역(예 : 로그 확률의 로컬 최대값)에 있는 경향이 있다는 것입니다. 이 논문에서는 위에서 세운 가설을 경험적으로 검증하고, 사소한 재작성 또는 변화가 대체할 수 있는 언어 모델에서 오는 경우에도 다양한 LLM에 걸쳐 가설이 참임을 발견하였습니다. 그리고 이 관찰을 활용하여 자동화된 기계 생성 텍스트 탐지를 위한 제로샷 방법론인 DetectGPT를 구현하였습니다.

소스 모델인 에서 문단이 작성되었는지 테스트하기 위해, DetectGPT는 후보 문단의 로그 확률을 보다 낮은 성능을 가지는 모델을 통해 작은 변화를 준 결과의 평균 로그 확률과 비교합니다. 미세 변화된(Perturbated) 문단이 원본 문단보다 평균 로그 확률이 낮은 경향이 있다면 후보 문단은 소스 모델인 에서 왔을 가능성이 높습니다.
본 논문의 실험은 DetectGPT가 기계 생성 텍스트를 탐지하기 위한 기존 제로샷 기반 방법들보다 더 정확하며, 특히 기계가 생성한 뉴스 기사를 탐지할 때 여러 소스 모델에 대해 기존 SOTA보다 AUROC 기준 0.10 이상의 향상을 가져왔음을 발견하였습니다.
🟡따라서 본 논문의 기여는 다음과 같습니다.🟡
1) 기계가 생성한 텍스트의 로그 확률 함수의 곡률이 인간이 작성한 텍스트보다 모델 샘플에서 훨씬 더 큰 음의 값을 가지는 경향이 있다는 가설의 경험적 검증
2) 1)의 가설을 바탕으로 인공지능의 생성한 텍스트를 탐지할 수 있는 실용적인 알고리즘을 제안
2. Related Work
점점 더 큰 LLM들이 많은 자연어처리 관련 벤치마크들에서 성능을 획기적으로 향상시키고 있으며, 심지어 주제에 맞고 설득력 있는 텍스트들을 생성할 수 있는 기능까지 제공하고 있습니다.
GROVER 모델(Zellers et al., 2019)은 실제처럼 보이는 뉴스 기사를 생성하기 위해 특별히 학습된 최초의 LLM이엇으며, 인간 평가자들은 GROVER가 생성한 기사를 인간이 작성한 기사만큼 신뢰하였으며, 심지어 인간이 작성한 것들보다 조금 더 신뢰할 수 있다고 평가하였습니다. 같은 논문에서 저자들은 GROVER가 생성한 텍스트를 더 잘 감지해내는 Detector도 제안하였으며, GROVER가 생성해낸 텍스트를 다른 언어 모델이 생성한 것들보다 더 잘 감지할 수 있는 것도 발견하였습니다. 그러나 최근 선행 연구들(Bakhtin et al, 2019; Uchendu et al., 2020)은 기계가 생성한 텍스트를 탐지하기 위해 명시적으로 학습된 모델이 해당 텍스트의 도메인이나 소스 모델의 학습 분포에 지나치게 오버피팅 되는 경향이 있음을 지적하였습니다.
다른 연구들은 신경 표현(Neural Representation)(Bakhtin et al., 2019; Solaiman et al., 2019; Uchendu et al., 2020; Ipolito et al., 2020; Fagni et al., 2021), Bag-of-words 특징(Solaiman et al., 2019; Fagni et al., 2021), 수작업된 통계적 특징(Gehrman et al., 2019)을 기반으로 기계 생성 텍스트 탐지를 위한 지도 모델을 학습시켰습니다.
특히 Solaiman et al.(2019)은 생성 모델에서 평균 로그 확률을 기반의 간단한 제로샷 텍스트 탐지 방법을 제안하였으며, 본 연구는 해당 연구를 바탕으로 제로샷 기반 기계 생성 텍스트 탐지의 기준을 세웠습니다. 본 연구에서는 비슷하게 생성 모델을 사용하여 제로샷 방식으로 자체 생성을 감지하지만, 샘플 자체는 Raw Log Probability가 아니라 샘플 주변의 로그 확률의 지엽적 곡률 추정(Local Curvature of the Log Probability)을 기반으로 하는 다른 접근 방식을 채택하였습니다. 기계 생성 텍스트 탐지에 대한 전체적인 가이드라인은 Jawahar et al.(2020)을 참조하였습니다.
본 연구는 생성된 텍스트의 탐지가 쉬운 상황은 가정하지 않습니다. DetectGPT는 표준 LLM 샘플링 전략을 사용하여 일반적으로 사용 가능한 높은 성능의 LLM에서 생성된 텍스트를 탐지합니다.
3. The Zero-Shot Machine-Generated Text Detection Problem
💡 Zero-Shot Learning이란?
Zero-Shot은 쉽게 말하면 "모델이 학습 과정에서 배우지 않은 작업을 수행하는 것"을 의미합니다. 다음과 같은 생성 모델들에서의 예시를 들 수 있습니다.
1. 유인나의 목소리로 음성을 생성하도록 학습된 TTS 모델이 예시 샘플을 이용하여 아이유의 목소리로도 음성을 생성하는 것
2. 셰익스피어처럼 글을 쓰도록 학습된 자연어 생성 모델이 마크 트웨인의 스타일로 글을 쓰는 것
3. 학습 과정에서 존재하지 않았던 종류의 이미지도 생성하는 것
이렇게 직접적으로 학습하지 않은 task에 대해 수행하는 다양한 응용들이 있으며, 모델이 특정한 작업을 수행하도록 학습되지 않았음에도 해당 작업을 수행할 수 있도록 하는 것을 Zero-Shot Learning이라고 합니다!
📌 그렇다면 Zero-Shot Learning이 어떻게 가능한가?
학습 task로써 매우 다양한 task를 수행할 수 있게 된다거나, 일반화된 task를 수행할 수 있게 되는 Zero-Shot Learning을 하는 이유는 학습 과정에서 모델이 의미 정보(Semantic Information)을 적절히 배우도록 하기 위해서입니다. 음성 모델이 음성을 구성하는 성분들을 이해하도록 하고, 자연어 모델이 해당 언어 자체를 이해하도록 하며, 이미지 모델이 이미지의 특성 자체를 이해할 수 있도록 하는 것입니다.이렇게 각 도메인의 일반화된 지식을 이해하도록 모델이 학습하면, 각 도메인에 속하는 다양한 task에 적응할 수 있게 됩니다. 따라서 최근에는 특정 task의 성능을 높이기 위한 지도학습(Supervised Learning) 방법이 아니라, 입력 데이터 자체에 대한 이해와 표현력을 높이기 위한 비지도학습(Unsupervised Learning)과 자기지도학습(Self-Supervised Learning) 같은 기술이 고도화되고 있습니다.
본 논문에서는 제로샷 기반 기계 생성 텍스트 탐지를 연구하였는데, 이는 텍스트 조각 또는 후보 문단 가 소스 모델 의 샘플인지 여부를 탐지하는 문제입니다. 이 문제의 경우 탐지를 수행하기 위해 사람이 라벨링하거나 생성한 샘플에 대한 엑세스는 가정하지 않았다는 점에서 '제로샷(Zero-Shot)'입니다.
이전 연구들과 마찬가지로, 본 연구는 탐지기(Detector)가 샘플의 을 평가할 수 있는 '화이트 박스(White-Box)' 설정(Gehrmann et al., 2019)을 연구합니다. 여기서 화이트 박스 설정은 모델 아키텍처 또는 매개 변수에 대한 액세스를 가정하지 않습니다. GPT3와 같은 LLM용 대부분의 공용 API는 스코어링 텍스트를 사용할 수 있지만 일부 예외가 존재합니다. 따라서 대부분의 실험에서 화이트 박스 설정을 고려하지만, 소스 모델 가 아닌 다른 모델을 사용하여 텍스트의 점수를 매기는 실험은 섹션 5.2를 참조하시기 바랍니다.
본 연구에서 제안하는 DetectGPT는 후보 문단의 '근처(Nearby)'에 있는 문단을 생성하기 위해 일반적인 사전 훈련된 Mask-filling 모델을 사용합니다. 이러한 Mask-filling 모델은 대상 도메인에 대한 Fine-tuning이나 Adaptation 없이 기성 모델(Off-the-shelf)을 사용합니다.
4. DetectGPT : Zero-Shot Machine-Generated Text Detection with Random Perturbations
(이 부분은 논문과 다름. 본인의 이해를 바탕으로 서술한 것임!)

DetectGPT의 전반적인 알고리즘은 위와 같으며 요약하자면 다음과 같은 흐름입니다.
`input` : 텍스트 문단`x`, 소스 모델 `$p_theta$`, 미세 변화 함수 `q`, 변화 결과의 개수 `k`
1. `q`함수를 통해 `x`에서 Perturbated된 분포를 생성합니다.
2. 1에서 생성된 분포에 대한 Expectation을 추정합니다.
3. 미세 변화 불일치도(Perturbation Discrepancy) `d(x, p_theta, q)`를 추정합니다.
4. 정규화를 진행 후 분산을 계산하며, 분산을 바탕으로 계산된 값에 따라
인간이 생성한 텍스트인지, 기계가 생성한 텍스트인지 판단합니다.DetectGPT는 소스모델 의 샘플이 일반적으로 인간 텍스트와는 달리 의 로그 확률 함수의 음의 곡률 영역에 있다는 가설을 기반으로 합니다. 즉 생성된x에 미세 변화를 주는 함수를 적용하면 그렇게 생성된 미세 변화 텍스트의 분포는 사람이 작성한 텍스트에 비해 평균 Perturbation Discrepancy가 상대적으로 커야 한다는 것을 의미합니다.
여기서 Perturbation Fuctionq는 x의 의미를 보존하면서 인간에게 x의 문장 중 하나를 다시 쓰라고 요청한 결과와 크게 다르지 않으며, 본 연구에서는 Perturbation Function의 개념을 사용하여 미세 변화 불일치도(Perturbation Discrepancy) d를 정의합니다.
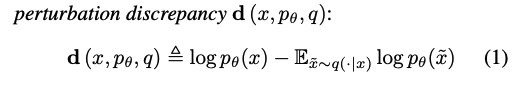
이러한 흐름에서 이 논문을 관통하는 중요한 가설은 다음과 같습니다.
만약q가 데이터에서 표본을 생성하면d는 생성된 표본 분포x에 대해 높은 확률로 양수입니다.
반면 사람이 쓴 텍스트의 경우d는 모든x에 대해 0으로 근사합니다.

여기서 를 인간의 재작성이 아닌 T5(Raffel et al., 2020)과 같은 Mask-Filling 모델을 통해 생성된 샘플이라고 정의하면 우리는 자동화되고 확장 가능한 방식으로 가설 4.1을 경험적으로 테스트할 수 있습니다. 본 논문에서는 T5 언어모델을 사용하여 미세 변화 분포 데이터를 생성하는 방식으로 실험을 진행하였습니다.
이러한 맥락에서 우리는 단순히 Perturbation Discrepancy의 임계값을 설정함으로써 텍스트가 모델 에 의해 생성되었는지 여부를 탐지해낼 수 있습니다. 실제로 Expectation 값을 추정하는 데에 사용되는 관찰된 값의 표준 편차에 의해 Perturbation Discrepancy를 정규화하는 것이 일반적으로 AUROC를 약 0.02 정도 증가시킨다는 것을 발견하였기에, 정규화된 버전의 미세 변화 불일치도를 사용하였습니다.
Interpretation of the Perturbation Discrepancy as Curvature

위의 그림 3은 미세 변화 불일치도가 유용할 수 있음을 시사하지만, 무엇을 측정하는지는 명확하지 않습니다. 엄밀하게 말하면, 우리는 미세 변화 불일치가 후보 문단 근처의 로그 확률 함수의 국소 곡률 측정에 근접하며, 더 구체적으로는 로그 확률 함수의 헤시안의 음의 추적(The negative trace of the Hessian of the log probability function)에 비례한다는 것을 보여주어야 합니다.
이산 데이터의 미분 불가능성(non-differentiability)을 처리하기 위해 q를 통한 작은 변화가 원본과 유사한 의미를 유지하는 유효한 편집에 해당하는 잠재적 의미 공간(Latent Semantic Space)에 존재하도록 고려합니다. T5 모델은 자연어를 모델링하기 때문에 우리는 이 미세 변화가 임의의 편집이라기보다는 원래 구절의 그러한 의미있는 변형을 대략적으로 포착할 것으로 설계하였습니다.
5. Experiments
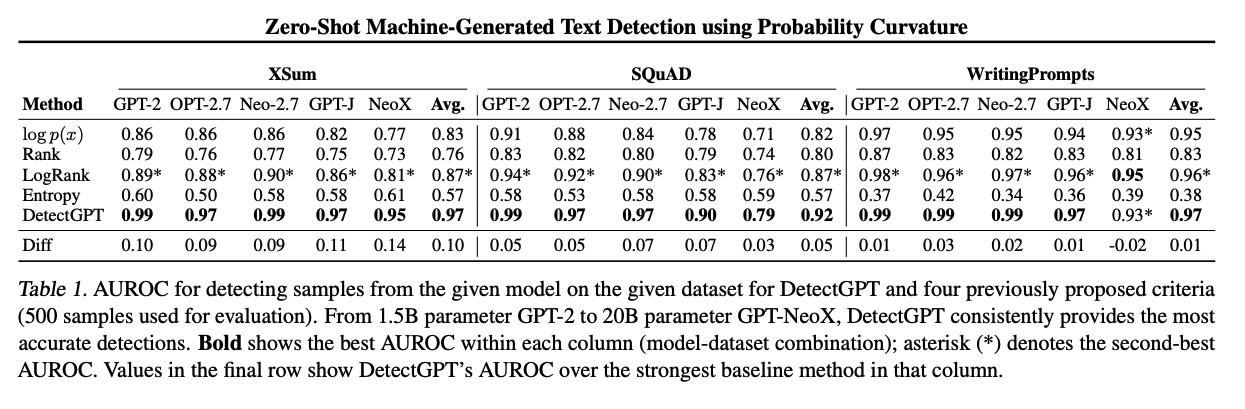
Dataset & Metrics
Datasets 본 연구에서는 일상에서 흔히 접할 수 있는 다양한 도메인의 LLM 사용 케이스들을 바탕으로 6가지 데이터셋을 사용하였습니다.
- XSum(Narayan et al., 2018) : 가짜 뉴스 탐지
- SQuAD(Rajpurkar et al., 2016) : 위키피디아 문단 기반 학술 에세이
- Reddit WritingPrompts(Fan et al, 2018) : 기계 생성 창작 스토리
- WMT16 Englist & German(Bojar et al., 2016) : 영어와 독일어 전반
- PubMedQA(Jin et al., 2019) : 공중 의학 QA
Metric AUROC를 기준으로 성능을 측정하였으며, 이는 탐지기가 기계가 생성한 예제를 인간이 작성한 예제보다 더 높게 순위를 매길 확률로 해석될 수 있습니다.
Results
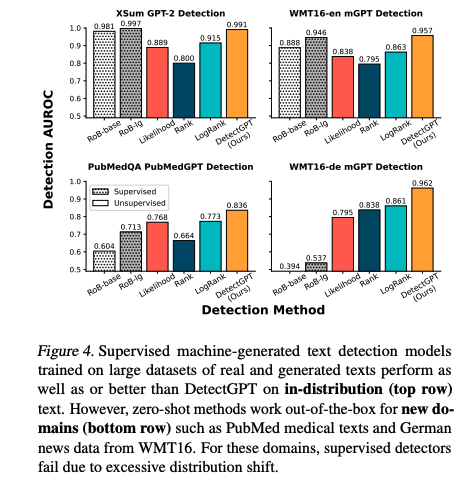
- 실제 텍스트와 생성된 텍스트로 구성된 대규모 데이터셋에 대해 학습된 기계 생성 텍스트 탐지 모델은 in-distribution(위쪽 행) 텍스트에서 DetectGPT와 동등하거나 더 나은 성능을 발휘하는 모델도 있었습니다.
- 그러나 제로샷 방법은 PubMed와 같은 의료 텍스트 및 WMT16의 독일 뉴스 데이터와 같이 새로운 도메인(아래쪽 행)에 대해 즉시 사용할 수 있을 정도로 괜찮은 성능을 보입니다.
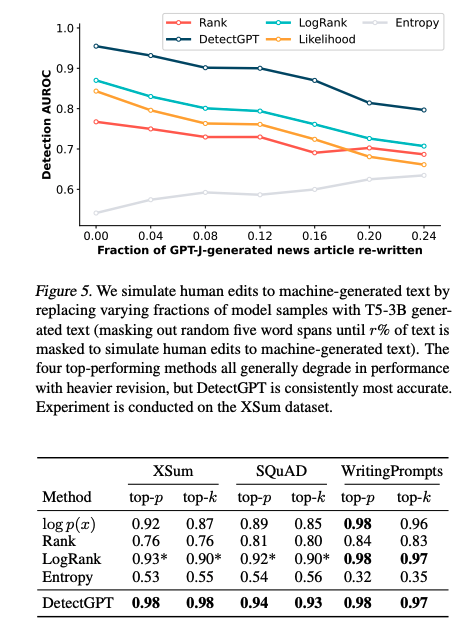
- 모델 샘플의 다양한 부분을 T5-3B로부터 생성된 텍스트로 대체하여 기계가 생성한 텍스트에 대한 인간의 편집을 시뮬레이션하였습니다.
- 가장 성능이 좋은 네가지 방법은 일반적으로 수정 버전이 클수록 성능이 저하되었지만, DetectGPT는 생성된 텍스트의 크기에 따라 감소하지는 하지만 그래도 괜찮은 정도(0.85 이상)의 성능을 보입니다.
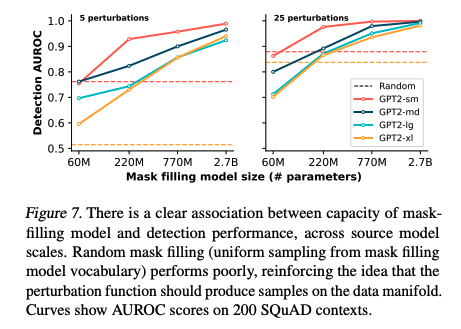
- 모든 소스 모델의 척도에 걸쳐서 Mask-Filling Model의 용량(Capacity)와 기계 생성 텍스트 탐지 성능 사이에 명확한 연관성이 있었습니다.
- Random Mask Filling의 경우 성능이 좋지 않아 Perturbation Function이 데이터 매니폴드에서 샘플을 생성해야한다는 의견을 뒷받침합니다.
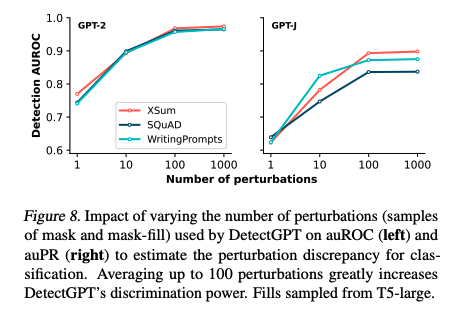
6. Discussion
DetectGPT and Watermarking
Perturbation Function에 대한 한가지 해석은 원래 문단과 의미론적으로 유사한 리프레시를 생성하는 것입니다. 이러한 재구사가 원래 문단보다 체계적으로 확률이 낮은 경우, 모델은 사용된 특정 구문에 대한 편향을 노출하고 있습니다. 즉, 인간의 글을 완벽하게 모방하지 않는 LLM은 본질적으로나 암시적으로나 자신을 'Watermaking'합니다. 이러한 해석에 따라 모델 출력에 워터마킹 편향(Watermarking Bias)을 수동으로 추가하려는 연구(Aaronson, 2022; Kichenbauer et al., 2023)들이 계속되고 있으며, 이를 통해 LLM이 계속 개선되더라도 DetectGPT와 같은 방법의 효과를 더욱 향상시킬 수 있습니다.
Limitation
DetectGPT와 같은 방법론의 구조 상 합리적인 Perturbation Function을 찾아내는 것이 중요합니다. 본 연구에서는 T5와 같은 기존의 Mask-Filling 모델을 사용하였으나, 사용하는 모델이 의미있는 재구사를 하지 못한다면 일부 도메인에서 성능이 저하되어 곡률 추정치(Curvature Estimate)의 품질이 저하될 수 있습니다. 더 잘 조정된 Perturbation Function이나 더 효율적인 곡률 추정치의 발견이 필요합니다.
My Opinion 👨🎓
매우 간단하면서도 효율적인 방식이라고 생각됩니다. 도메인과 관계없이 적용할 수 있는 Zero-Shot 방법이라는 점에서 가능성이 무궁무진하다고 판단됩니다.
GPT나 BERT 보다 더 나은 언어모델이 개발됨에 따라 '텍스트를 생성하는 언어 모델'을 활용하는 분야에서 인간과 다름없는 텍스트를 생성하고자 하는 모델과 기계가 작성한 텍스트를 탐지하는 모델이라는 창과 방패의 대결이 계속 이어질 것 같습니다.
둘 중 누군가 이기게 되는 것과는 상관없이
AI보다 좋은 텍스트를 생성하지 못하는 인간,
AI가 생성하는 텍스트를 탐지해내지 못하는 인간,
우리 인간은 소외되고 있으며 앞으로도 소외될 것이라는 점에서 안타까움을 느낍니다😭
(잘못된 점이 있다면 댓글로 피드백 부탁드립니다!🙏)
(참조하시게 된다면 출처 표시를 꼭 해주시길 부탁드립니다!🙏🙏🙏)
.
.
.
Reference

3개의 댓글

저도 대학원 논문 세미나로 이 논문을 준비하고 있는데
너무 훌륭하고 이해하기 쉽게 리뷰해주셔서
처음 논문 읽을 때 많은 도움이 되었습니다
감사합니다!
아주 인상적인 논문이에요! 해설 감사합니다. 환공님 멋져요!!