
1. Logistic Regression : 확률 계산
많은 문제에 확률 추정치가 출력으로 필요하다. 로지스틱 회귀는 매우 효율적인 확률 계산 메커니즘이다. 실제로 반환된 확률을 다음 두 방법 중 하나로 사용할 수 있다.
- '있는 그대로'
- 이진 카테고리로 변환
확률을 '있는 그대로' 사용하는 방법을 살펴보겠다. 한밤중에 개가 짖는 확률을 예측하기 위해 로지스틱 회귀 모델을 만든다고 가정한다면 이 확률은 다음과 같이 표시합니다.
P(bark | night)
로지스틱 회귀 모델이 예측한 p(bark | night)가 0.05이면 개 주인은 1년 동안 약 18번(번) 놀라서 깨게 될 것이다.
startled = P(bark | night) X nights
18 ~= 0.05 * 365
많은 경우 로지스틱 회귀 출력을 binary classification problem의 해결 방법으로 매핑한다. 이진 분류 문제의 목표는 가능한 두 라벨(예: '스팸' 또는 '스팸 아님') 중 하나를 올바로 예측하는 것이며, 매핑에 대한 더 자세한 내용은 이후 모듈에서 집중적으로 다룰 것이다.
로지스틱 회귀 모델의 출력이 어떻게 항상 0과 1 사이에 포함되는지 궁금할 수도 있다. 공교롭게도 다음과 같이 정의된 시그모이드 함수가 동일한 특성을 갖는 출력을 생성한다.
시그모이드 함수(sigmoid function)는 다음 그래프와 같다.
시그모이드 함수 x축은 원시 추론 값으로, y축은 0에서 +1까지 연장된다(0과 +1 제외).
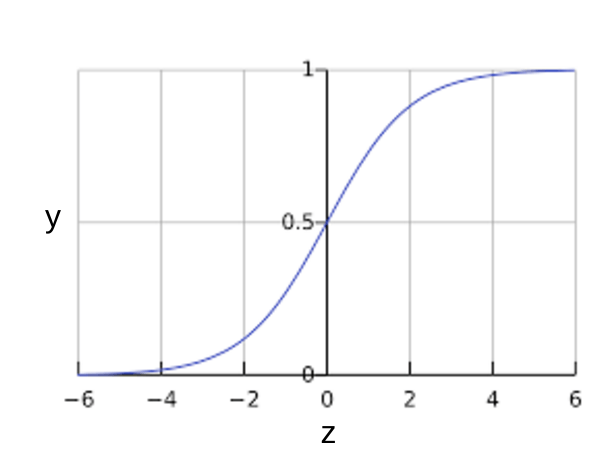
그림 1: 시그모이드 함수
z가 로지스틱 회귀를 사용하여 학습된 모델의 선형 레이어의 출력을 나타내는 경우 sigmoid(z)는 0과 1 사이의 값(확률)을 생성하며, 수학적 표현으로는 다음과 같다.
여기서
y'는 특정 예에 관한 로지스틱 회귀 모델의 출력이다.
-w값은 모델의 학습된 가중치이고,b는 편향이다.
-x값은 특정 예에 대한 특성 값이다.
z는 z를 '1' 라벨(예: '개가 짖음')의 확률을 '0' 라벨(예: '개가 짖지 않음')의 확률로 나눈 값의 로그로 정의할 수 있는 시그모이드 상태의 역수이므로 로그 오즈(log-odds)라고도 한다.
다음은 ML 라벨이 포함된 시그모이드 함수이다.

그림 2: 로지스틱 회귀 출력
2. Logistic Regression example
다음과 같은 편향과 가중치를 학습한 특성이 세 개인 로지스틱 회귀 모델이 있다고 가정합니다.
-
b= 1 -
w1= 2 -
w2= -1 -
w3= 5
또한 지정된 예의 특성 값이 다음과 같다고 가정합니다. -
x1= 0 -
x2= 10 -
x3= 2
따라서 로그 오즈는
이며, 다음과 같습니다.
결과적으로 이 특정 예의 로지스틱 회귀 예측값은 0.731입니다.

시그모이드 함수의 플롯 X = 1이므로 y = 0.731입니다.
3. 손실 및 정규화
(1) 손실 함수
선형 회귀의 손실 함수는 제곱 손실이다. 다만 로지스틱 회귀의 손실 함수는 로그 손실로 다음과 같이 정의된다.
로그 손실
여기서
- (x,y)∈D는 라벨이 있는 예(x,y 쌍)가 많이 포함된 데이터 세트.
y는 라벨이 있는 예의 라벨. 로지스틱 회귀이므로 y 값은 모두 0 또는 1이어야 함.y'는 x의 특성 세트에 대한 예측 값(0~1 사이의 값).
로그 손실 방정식은 정보 이론에서 말하는 섀넌의 엔트로피 측정과 밀접한 관련이 있다. 또한 우도 함수의 음의 로그로 y의 Bernoulli 분포를 가정한다. 실제로 손실 함수를 최소화하면 최대 우도 추정치가 생성된다.
(2) 로지스틱 회귀의 정규화
정규화는 로지스틱 회귀 모델링에서 매우 중요하다. 정규화하지 않으면 로지스틱 회귀의 점근 특성이 고차원에서 계속 손실을 0으로 만들려고 시도하며, 결과적으로 대부분의 로지스틱 회귀 모델에서 모델 복잡성을 줄이기 위해 다음 두 전략 중 하나를 사용한다.
- L2 정규화
- 조기 중단, 즉 학습 단계 수 또는 학습률을 제한
- 세 번째 전략인 L1 정규화에 관해서는 후속 모듈에서 설명하겠다.
각 예에 고유 ID를 할당하고 각 ID를 자체 특성에 매핑한다고 가정하자. 정규화 함수를 지정하지 않으면 모델이 완전히 과적합된다. 모델이 모든 예에서 손실을 0으로 만들려고 하지만 0으로 만들지 않아 각 표시 특성의 가중치를 +무한대 또는 -무한대로 만들기 때문이다. 한 예에서 하나만 발생하는 드문 교차가 아주 많은 경우 특성 교차가 포함된 고차원 데이터에서 이러한 일이 발생할 수 있다.
다행히 L2나 조기 중단을 사용하면 이러한 문제가 발생하지 않는다.
.
.
.
강의 링크 : 구글 머신러닝 단기집중과정
