
💡오늘 배울 내용
모든 데이터를 대상으로 손실 함수의 합을 구하려면 시간이 걸립니다. 데이터의 일부를 추려 계산하는 방법을 미니 배치 학습이라고 합니다. 미니 배치 학습을 알아보고, 이 학습에 사용되는 교차 엔트로피 오차를 구현해봅시다. 또한 손실 함수를 설정하는 본질적인 이유에 대해 알아봅시다.
🔎미니 배치 학습
기계학습 문제는 훈련 데이터를 사용해 학습합니다. 구체적으로는 훈련 데이터에 대한 손실 함수의 값을 구하고, 그 값을 최대한 줄여주는 매개변수를 찾아내는 과정입니다. 이렇게 하려면 모든 훈련 데이터를 대상으로 손실 함수 값을 구해야 합니다. 즉, 훈련 데이터가 100개 있으면 그로부터 100개의 손실 함수 값들의 합을 지표로 삼는 것입니다.
이렇게 하면 손실 함수의 값들의 합(오차)를 통해 모델의 정확도를 알 수 있고, 모델의 파라미터를 수정해보며 모델의 정확도를 향상시킬 수 있게 됩니다.
훈련 데이터 모두에 대한 손실 함수의 합을 구하는 방법을 생각해볼까요? 여러개의 훈련 데이터에서 교차 엔트로피 오차를 구하는 방법을 알아봅시다.
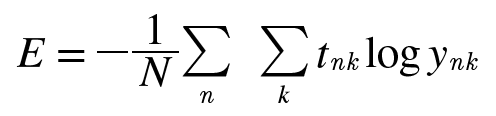
데이터가 N개라면, nk는 n번째 데이터의 k번째 값을 의미합니다. (ynk는 신경망의 출력, tnk는 정답 레이블입니다.) 수식이 복잡해보이지만, 손실함수 식을 단순히 N개의 데이터로 확장했을 뿐입니다.
수많은 데이터들을 모두 신경망에 한번씩 통과시켜 출력층 값을 얻고, 이를 정답 레이블과 계산하여 평균 손실 함수 값을 얻을 수 있는 것입니다.
MNIST 데이터 셋은 훈련 데이터가 60,000개 입니다. 원래대로라면 60,000장의 이미지 데이터를 모두 신경망에 한번씩 통과시키고, 손실 함수 값을 모두 구한 뒤 더해야 하지만 이런 경우 시간이 너무 많이 걸릴 수 있습니다.
신경망 학습에서는 훈련 데이터로부터 일부만 골라 학습을 수행합니다. 즉, 미니 배치 학습은 데이터 일부를 추려 전체의 '근사치'로 이용하는 방법입니다. 이 일부를 '미니 배치'라고 합니다.
훈련 데이터에서 지정한 수의 데이터를 무작위로 골라내는 코드를 작성해봅시다. MNIST 데이터셋을 읽어오는 코드는 다음과 같습니다. 정규화는 True로 설정하고, 원 핫 인코딩 방식을 사용하여 데이터를 불러옵니다.
import sys
import os
# 부모 디렉토리의 파일을 가져올 수 있도록 설정
sys.path.append(os.pardir)
# numpy 라이브러리 임포트
import numpy as np
# dataset 폴더의 mnist파일에서 load_mnist 함수 import
from dataset.mnist import load_mnist
#load_minst()를 통한 데이터 불러오기
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
# 각 데이터의 형상 출력
print(x_train.shape)
>> (60000, 784)
print(t_train.shape)
>> (60000, 10)앞에 코드에서 MNIST 데이터의 훈련 데이터는 60,000개 이고, 784열로 된 이미지 데이터임을 알 수 있습니다. 또 정답 레이블은 10줄짜리 데이터입니다.
넘파이의 np.random.choice()함수를 통해 무작위로 10장을 빼낼 수 있습니다. 무작위로 빼낸다는 것은 데이터 일부를 추려 손실 함수 계산을 하기 위함입니다.
import numpy as np
#총 훈련 이미지의 개수를 셉니다.
train_size = x_train.shape[0]
#손실 함수 계산에 몇개의 데이터를 이용할지 정합니다.
batch_size = 10
#몇번째 데이터로 손실 함수 계산을 할지 인덱스가 원소인 배열을 만듭니다.
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]다음은 실제로 돌려본 모습입니다. 이 함수가 출력한 배열을 미니배치로 뽑아낼 데이터의 인덱스로 사용하면 됩니다.
np.random.choice(60000, 10)
>> array([ 8013, 14666, 58210, 23832, 52091, 10153, 8107, 19410, 27260, 21411 ])🔎배치용 교차 엔트로피 오차 구현
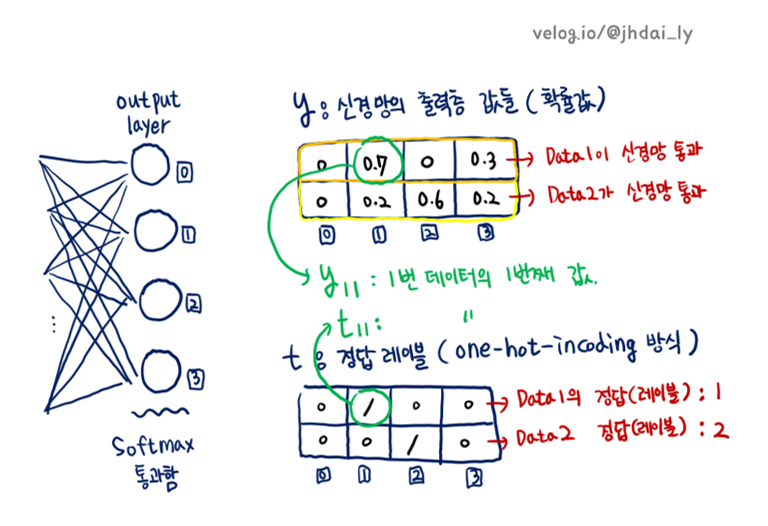
데이터가 하나일때와 데이터가 배치로 묶여 입력될 경우 모두를 처리할 수 있게 교차 엔트로피 오차를 구현해봅시다.
데이터가 하나일때를 조건문으로 구별하여 선처리를 해주어야 합니다. 데이터가 하나라면 신경망의 출력층 값들을 나타내는 y배열이 1차원이므로 조건을 y.ndim == 1: 처럼 설정합니다.
def cross_entropy_error(y, t)
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(t * np.log(y)) / batch_size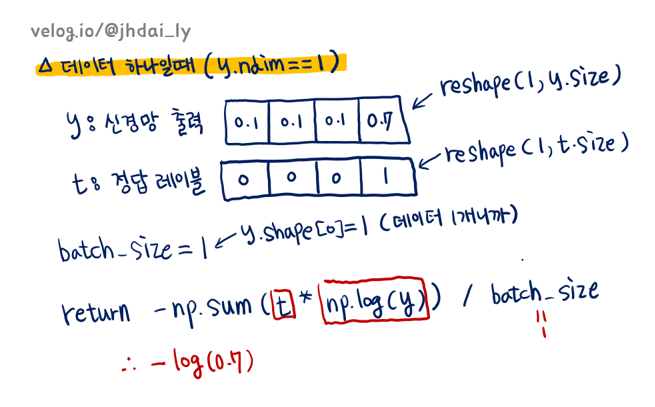

위의 구현은 정답 레이블이 원-핫 인코딩으로 표기되었을때에 적합하고, 정답 레이블이 숫자 레이블로 주어졌을때는 교차 엔트로피 오차를 다음과 같이 구현할 수 있습니다.
def cross_entropy_error(y, t)
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t])) / batch_size이 구현의 핵심은, 원-핫 인코딩일 때 t가 0인 원소는 교차 엔트로피 오차도 0이므로 그 계산은 무시해도 좋다는 것입니다. 다시 말하면 정답에 해당하는 신경망의 출력만으로도 교차 엔트로피 오차를 계산할 수 있습니다.
그래서 원-핫 인코딩 시 t * np.log(y) 였던 부분을 레이블 표현일 때는 np.log(y[np.arange(batch_size), t])로 구현합니다.
🔎손실 함수와 정확도
숫자 인식의 경우도 궁극적인 목적은 높은 정확도를 끌어내는 매개변수 값을 찾는 것입니다. 그렇다면 정확도라는 지표가 있는데도 손실함수라는 중간 과정을 거치는 것일까요?
다음 장에서 이를 미분으로 자세히 설명하지만, 간단하게 말하면 정확도를 지표로 하게 되면(100장 중 32장을 인식하므로 정확도는 32%) 정확도가 개선된다고 하더라도 그 값이 불연속적인 띄엄띄엄한 값으로 바뀌어버립니다.
하지만 손실함수를 지표로 삼았다면 사진 한장을 인식했다고 끝이 아니라 사진 한장을 인식하는 과정에서의 파라미터가 얼마나 정확한지도 계산할 수 있게 됩니다. 즉, 더욱더 민감하게 모델의 정교함을 측정할 수 있다는 것입니다. 참고로 매개변수의 값이 조금씩 변하면 그의 반응하여 손실함수의 값은 연속적으로 변화합니다.

이는 계단함수를 활성화 함수로 사용하지 않는 이유와 일맥상통합니다.
