
💡오늘 배울 내용
신경망 학습에서는 현재 모델의 상태를 '하나의 지표'로 표현합니다. 그리고 그 지표를 가장 좋게 만들어주는 가중치 매개변수의 값을 탐색하는 것입니다. 그 지표를 손실 함수(Loss Function)라고 합니다.
🔎손실 함수
신경망 학습에 있어 지표가 되는 함수를 손실 함수라고 합니다. 보통 예측값과 실제값(레이블)의 차이를 기준으로 손실 함수가 정의됩니다. 대표적인 손실함수인 평균 제곱 오차와 교차 엔트로피 오차를 알아봅시다.
🔔평균 제곱 오차
평균 제곱 오차(MSE, Mean Squared Error)의 수식은 다음과 같습니다.
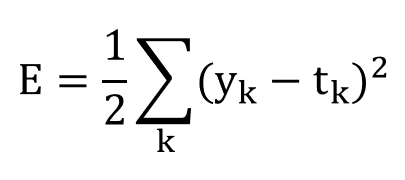
여기서 k는 데이터의 차원 수를 나타냅니다. yk와 tk는 각각 신경망이 추정한 값(신경망의 출력 값)과 정답 레이블을 나타냅니다.
예를 들면 y와 t배열을 각각 원-핫 인코딩으로 다음과 같이 표기할 수 있습니다.
>>> y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0]
>>> t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]y배열은 소프트맥스 함수의 출력이므로 확률로써 해석할 수 있습니다. t배열은 정답 레이블로 위의 경우에선 정답이 '2'로 표시된 정답 레이블임을 알 수 있습니다.
파이썬으로 평균 제곱 오차를 구현해봅시다.
def mean_squared_error(y, t)
return 0.5 * np.sum((y-t)**2)다음의 경우에서 y와 t는 넘파이 배열입니다.
# <평균 제곱 오차 계산 실습>
#정답 레이블이 가르키는 정답은 '2'
t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
#'2'일 확률이 가장 높다고 추정한 모델 결과
y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0]
print(mean_squared_error(np.array(y), np.array(t))
>> 0.097500000000000031
#'7'일 확률이 가장 높다고 추정한 모델 결과
y2 = [0.1, 0.05, 0.1, 0.0, 0.05, 0.1, 0.0, 0.6, 0.0, 0.0]
print(mean_squared_error(np.array(y2), np.array(t))
>> 0.59750000000000003해당 실험을 통해 신경망이 정답을 예측했다면 평균 제곱 오차가 작아지지만, 틀린 답으로 예측한 경우에는 오차가 매우 커짐을 알 수 있습니다.
🔔교차 엔트로피 오차
교차 엔트로피 오차(CEE, Cross Entropy Error)의 수식은 다음과 같습니다.
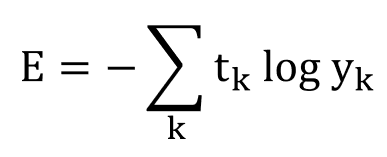
마찬가지로 k와 yk, tk는 각각 데이터 차원 수, 신경망의 출력, 정답 레이블을 의미합니다. 또한 log는 밑이 e인 자연로그입니다.
tk는 정답에 해당하는 인덱스의 원소만 1이고 나머지는 0이므로(원-핫 인코딩), 실질적으로 정답일 때의 추정(tk가 1일때의 yk)의 자연로그를 계산하는 식이 됩니다.
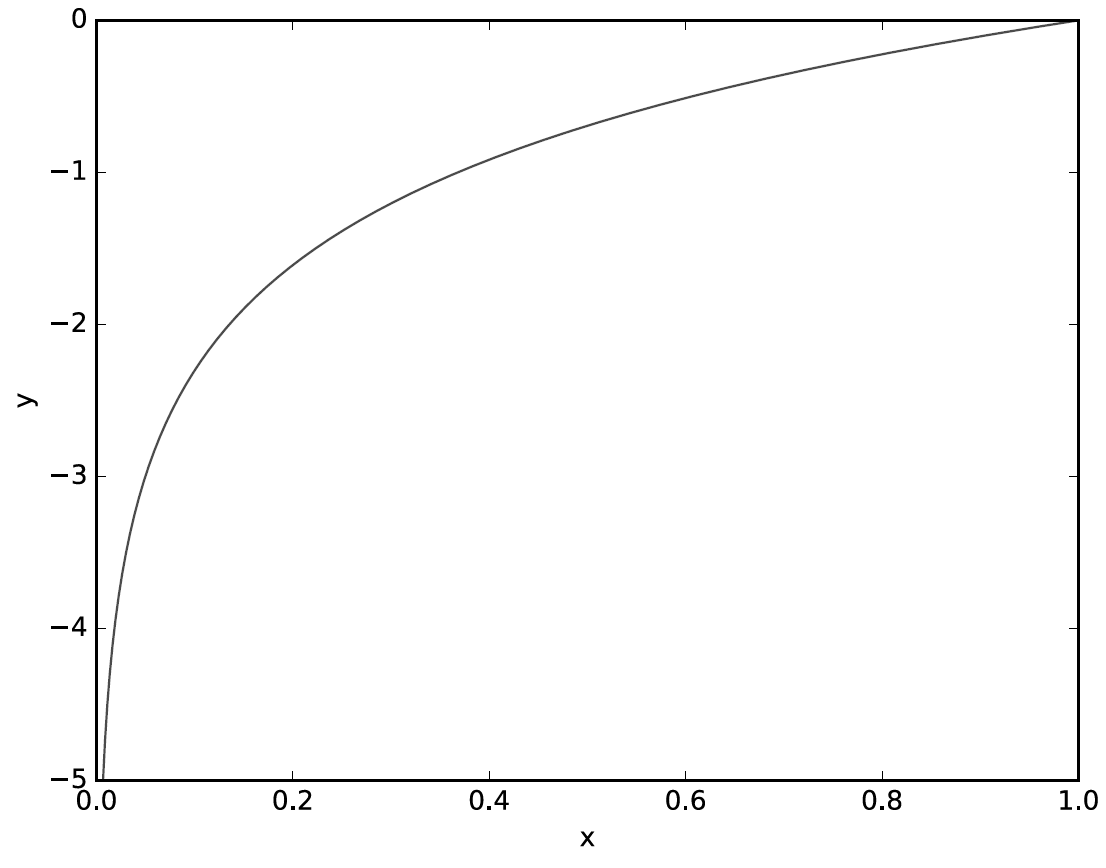
자연로그 y = logx 그래프를 통해 알 수 있는 것 처럼 모델의 추정이 틀렸다면 yk는 낮은 값이 되고 log(yk)의 값 또한 낮아져서 오차가 커집니다.
import numpy as np
def cross_entropy_error(y, t):
delta = 1e-7
return -np.sum(t *np.log(y + delta))다음은 교차 엔트로피 오차를 식으로 구현한 것으로 np.log를 계산할때 아주 작은 값인 delta를 더해주어 log0이 되는것을 방지해주고 있습니다. -log0은 -inf가 되어 더 이상 계산을 진행할 수 없기 때문입니다.

# <교차 엔트로피 오차 계산 실습>
#정답 레이블이 가르키는 정답은 '2'
t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
#'2'일 확률이 가장 높다고 추정한 모델 결과
y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0]
print(cross_entropy_error(np.array(y), np.array(t))
>> 0.51082545709933802
#'7'일 확률이 가장 높다고 추정한 모델 결과
y2 = [0.1, 0.05, 0.1, 0.0, 0.05, 0.1, 0.0, 0.6, 0.0, 0.0]
print(cross_entropy_error(np.array(y2), np.array(t))
>> 2.3025840929945458모델이 정답을 맞췄을때의 오차는 0.51이지만, 오답을 출력한 모델의 교차 엔트로피 오차는 무려 2.3입니다. 즉, 오차가 낮은 첫번째 모델의 추정이 정확하다고 판단할 수 있습니다.
두 오차 함수는 모두 오차를 계산해서 모델의 정확도를 측정할 수 있지만 평균제곱오차 함수는 정답과 오답의 모든 확률을 고려하고, 교차 엔트로피 오차 방식은 정답의 확률만을 고려한다는 차이점도 있습니다.
