
💡 오늘 배울 내용
순전파 신경망으로 MNIST 데이터를 학습시켜 손글씨를 인식하는 과정을 실습해봅시다. 순전파 신경망은 앞에서부터 차례대로 연산을 진행하고, 가중치와 편향(매개변수) 값들을 업데이트 하는 과정이 없습니다. 즉, 이때 알맞게 구성된 매개변수 세트가 이용됩니다.
🔎MNIST 데이터셋
MNIST는 기계학습 분야에서 아주 유명한 데이터셋으로, 간단한 실험부터 논문으로 발표되는 연구까지 다양한 곳에서 이용되고 있습니다.
MNIST 데이터셋은 0부터 9까지의 숫자 이미지로 구성됩니다. 훈련(train) 이미지가 6만장, 시험(test) 이미지가 1만장 준비되어 있습니다. 여기서 훈련 이미지는 신경망 모델을 훈련하는데 사용되고 시험 이미지는 훈련된 모델의 성능을 평가하는데 사용됩니다.
🔔데이터의 형상
MNIST 이미지 데이터는 28 x 28 크기의 회색조 이미지이며, 각 픽셀은 0에서 255의 값을 취합니다. 더 자세히는 픽셀의 색이 흰색에 가까울 수록 255에 가까운 값을, 검정에 가까울 수록 0의 값을 취합니다. 각 이미지에는 '7', '2, '8'과 같이 그 이미지가 실제 의미하는 숫자가 레이블로 붙어 있습니다.

MNIST 이미지 데이터중 숫자 3이 라벨로 붙어있는 데이터 하나를 임의로 가져왔습니다. 다음과 같이 숫자 3을 컴퓨터가 읽을때는 원소가 0과 255사이의 숫자로 구성된 28 x 28 크기의 2차원 배열로 받아들인다는 것을 알 수 있습니다.
참고로 MNIST 이차원 이미지를 해당 사진처럼 출력하기 위해서는 flatten을 False로 설정하여야하고 아래처럼 파이썬 코드를 추가하여 print option을 설정해주어야 합니다.
np.set_printoptions(linewidth=150, threshold=1000)🔔데이터 불러오기
import sys
import os
# 부모 디렉토리의 파일을 가져올 수 있도록 설정
sys.path.append(os.pardir)
# dataset 폴더의 mnist파일에서 load_mnist 함수 import
from dataset.mnist import load_mnist
#load_minst()를 통한 데이터 불러오기
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False)
# 각 데이터의 형상 출력
print(x_train.shape)
>> (60000, 784)
print(t_train.shape)
>> (60000, )
print(x_test.shape)
>> (10000, 784)
print(t_test.shape)
>> (10000, )load_mnist() 함수는 MNIST 데이터를 "(훈련 이미지, 훈련 레이블), (시험 이미지, 시험레이블)"의 형식으로 반환합니다. 함수의 매개변수로는 normalize, flatten, one_hot_label 세가지를 설정할 수 있습니다.
각각의 매개변수를 알아보기 전에, load_mnist()함수가 어떠한 식으로 데이터를 가져오는지 이해해봅시다. 데이터의 형상을 보면 이를 쉽게 이해할 수 있습니다. flatten과 normalize값은 각각 True와 False로 설정되어있습니다.
x_train은 훈련 이미지로, 형상은 (60000, 784)입니다. 즉, 60000행 784열로 된 2차원 배열입니다. 여기서 60000은 훈련 이미지가 60000장 있기 때문이고, 784열은 MNIST 이미지 데이터의 크기가 28 x 28이기 때문입니다. 한 행에 한 장씩의 이미지 데이터가 flatten되어 저장되어 있는 것입니다.
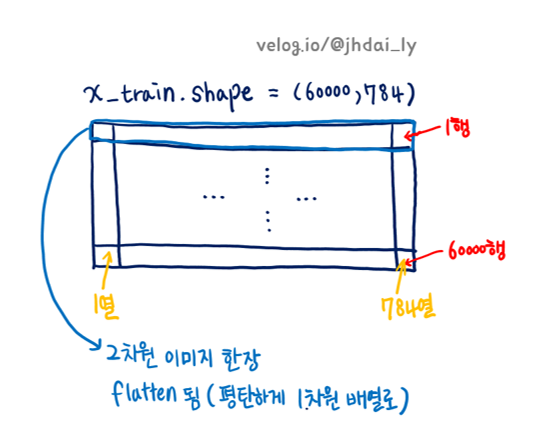
t_train은 훈련 레이블로, 형상은 (60000, )입니다. 즉, 60000개의 원소를 가진 일차원 배열입니다. 훈련 레이블이란 훈련 이미지 60000장과 일대일로 대응되는 정답 값입니다. x_train[0]의 이미지 데이터가 의미하는 숫자가 3이라면, t_train[0]에는 '3'이 저장되어있습니다. 물론 어떠한 방식으로 t_train이 정답값이 저장될지는 load_mnist()함수의 one_hot_label 매개변수를 이용하여 조절할 수 있습니다.
x_test는 시험 이미지로, 형상은 (10000, 784)입니다. 즉, 10000행 784열로 된 2차원 배열입니다. 여기서도 x_train의 형상을 설명할 때와 같은 이유로 한 행에 한 장씩의 이미지 데이터가 총 1만장 flatten되어 저장되어 있습니다.
t_test는 시험 레이블로, 시험 이미지에 일대일로 대응되는 정답 값이 저장되어 있습니다.
load_mnist()의 매개변수를 각각 알아봅시다. 세 매개변수 모두 인수로 bool 값(True/False)를 갖습니다. 먼저 normalize는 입력 이미지의 픽셀 값을 0.0~1.0 사이의 값으로 정규화할지를 정합니다. False로 입력하면 픽셀은 원래의 값 0~255 사이의 값을 유지합니다. 정규화 하는 원리는 단순히 픽셀 값을 255로 나누는 것입니다.
flatten은 평탄화를 의미하는 것으로, 입력이미지를 1차원 배열로 만들지 정합니다. False로 입력하면 입력 이미지 한장은 1 x 28 x 28의 형상(3차원 배열)으로 저장됩니다. True로 설정하면 784개의 원소로 이루어진 1차원 배열로 저장합니다.
세번째 변수인 one_hot_label은 레이블을 원-핫 인코딩 형태로 저장할지를 정합니다. 원-핫 인코딩 방식이란 레이블을 [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]처럼 정답을 뜻하는 원소만 1, 나머지는 0으로 저장하는 방식입니다.
🔔데이터 확인하기
import sys
import os
import numpy as np
sys.path.append(os.pardir)
from dataset.mnist import load_mnist
from PIL import Image
#넘파이로 저장된 데이터를 PIL용 데이터 객체로 변환하여 이미지로 보여주는 함수
def img_show(img):
pil_img = Image.fromarray(np.uint8(img))
pil_img.show()
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False)
#훈련 이미지 한장(x_train[0])을 변수 img에 저장함.
img = x_train[0]
#훈련 레이블 한장(t_train[0]을 변수 label에 저장함.)
label = t_train[0]
print(label)
>> 5
print(img.shape)
>> (784, )
#원래 이미지 모양으로 복구
img = img.reshape(28,28)
print(img.shape)
>> (28, 28)
img_show(img)
img_show 함수를 통해 x_train[0]에 저장되어있는 데이터를 이미지 형태로 출력해보았습니다. t_train[0]에 '5'가 저장되어있는 것에서도 알 수 있듯 해당 이미지는 숫자 5를 의미합니다.
🔎신경망의 추론 처리
load_mnist() 함수를 통해 수많은 이미지들을 1차원 배열(flatten)로 된 숫자로 변환시킬 수 있음을 알았습니다. 이제 이 784개의 픽셀(0~255사이의 값)들을 신경망에 투입하여, 어떤 숫자를 의미하는지에 대한 y값(출력층에서 확률이 출력됨)을 얻어낼 차례입니다.
신경망의 입력층 뉴런은 784, 출력층 뉴런은 10개로 구성합니다. 입력층 뉴런의 수가 784개인 이유는 MNIST 이미지(28 x 28)를 flatten 하면 784개의 픽셀로 된 1차원 배열로 나타낼 수 있기 때문이고, 해당 배열에 들어있는 숫자 하나하나를 뉴런 하나하나에 대응시킬 것입니다. 마찬가지로 출력층 뉴런이 10개인 이유는 MNIST 데이터가 0~9 사이의 숫자를 레이블로 갖는 데이터이기 때문입니다. 반드시 MNIST 데이터는 0과 9사이의 숫자 하나를 의미할 것입니다.
은닉층의 개수와 뉴런 수는 임의로 정합니다. 여기서는 총 두개의 은닉층으로, 첫번째 은닉층에는 50개의 뉴런을, 두번째 은닉층에는 100개의 뉴런을 배치할 것입니다. 784개의 뉴런을 가진 입력층, 50개와 100개의 뉴런을 가진 은닉층, 10개의 뉴런을 가진 출력층을 위해 매개변수가 몇개 필요할지도 적당히 계산할 수 있을 것입니다.
#get_data() 함수
def get_data():
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False, one_hot_label=False)
return x_test, t_test
#init_network() 함수
def init_network():
with open("sample_weight.pkl",'rb') as f:
network = pickle.load(f)
return network
#predict() 함수
def predict(network, x):
W1,W2,W3 = network['W1'],network['W2'],network['W3']
b1,b2,b3 = network['b1'],network['b2'],network['b3']
a1 = np.dot(x,W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1,W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2,W3) + b3
y = softmax(a3)
return yget_data() 함수는 앞서 설명했던 load_mnist()함수를 사용하여 MNIST 데이터를 가져옵니다. get_data()를 실행하면 x_test(시험 이미지)와 t_test(시험 레이블)을 저장합니다.
init_network() 함수는 pickle 파일인 sample_weight.pkl에 저장된 '학습된 가중치 매개변수'를 읽습니다. 이 파일에는 가중치와 편향 매개변수가 딕셔너리 변수로 저장되어있습니다. 참고로 pickle이란 프로그램 실행 중에 특정 객체를 파일로 저장하는 기능입니다. 저장해둔 pickle 파일을 로드하면 실행 당시의 객체를 즉시 복원할 수 있습니다.
predict() 함수는 network(가중치와 편향 매개변수 데이터)와 x를 입력값으로 받아 순전파 신경망을 통과하고 최종 결과값인 y값을 돌려주는 함수입니다. 여기서 말하는 x란 입력층에 들어갈 입력 이미지입니다.

조금 더 자세히 설명하자면, 딕셔너리 변수 network 변수에는 적절한 매개변수가 저장되어 있어서 predict()함수를 통해 x를 입력받으면, 이 매개변수를 통해 순전파 신경망을 작동시키는 것입니다. predict()함수의 코드에서 a1=np.dot(x, w1)+b1은 입력층의 신호가 첫번째 은닉층으로 이동하며 행렬곱 연산으로 가중치 합을 계산합니다. 또한 z1=sigmoid(a1) 코드에서는 활성화 함수를 적용하여 다음 은닉층으로 신호를 보낼 준비를 끝냅니다. 이렇게 계속 신호를 보내는 과정을 이어가고, 출력층에서 softmax 함수까지 적용하고 나면 이 결과를 y에서 출력하게 됩니다.
그렇다면 함수를 사용해 신경망에 의한 추론을 실행해보고 정확도를 평가해봅시다.
#x에 x_test(시험 이미지)저장
#t에 t_test(시험 레이블)저장
x, t = get_data()
#가중치와 편향(매개변수)를 network에 저장
network = init_network()
#정답을 맞춘 case를 count하기 위한 변수
accuracy_cnt = 0
#x_test의 길이(시험 이미지의 개수)만큼 반복문을 수행
for i in range(len(x)):
y = predict(network,x[i]) #추론을 수행
p = np.argmax(y) #확률이 가장 높은 원소의 인덱스를 얻음
# 정답을 맞춘 case를 count
if p == t[i]:
accuracy_cnt += 1
print('Accuracy:' + str(float(accuracy_cnt)/len(x)))predict() 함수의 마지막 과정에서는 소프트맥스 함수를 통과하게되고, 각 레이블의 확률을 넘파이 배열로 변환합니다. 예를 들면 [0.1, 0.3, 0.2, ..., 0.04]처럼 반환됩니다.
argmax()함수가 이 배열에서 값이 가장 큰(확률이 가장 높은) 원소의 인덱스를 구합니다. 이것이 바로 예측 결과가 됩니다.
🔎배치 처리
형상에 집중하여 조금 전의 구현을 다시 살펴봅시다.
#x에 x_test(이미지)를 저장합니다.
x, _ = get_data()
#network 변수 딕셔너리 안에 저장된 매개변수들을 불러옵니다.
network = init_network()
W1, W2, W3 = network['W1'], network['W2'], network['W3']
#만장의 이미지가 2차원 배열로 잘 저장되어있음.
print(x.shape)
>> (10000, 784)
#출력층 노드 수가 784개, 첫번째 은닉층의 노드수가 50개 이므로
print(W1.shape)
>> (784, 50)
#첫번째 은닉층의 노드수가 50개, 두번째 은닉층의 노드수가 100개 이므로
print(W2.shape)
>> (50, 100)
#두번째 은닉층의 노드수가 100개, 출력층의 노드수가 10개 이므로
print(W3.shape)
>> (100, 10)x에 이미지 한장씩 넣어 통과시키면 첫번째 은닉층, 두번째 은닉층, 출력층의 활성화 함수까지 통과하여 y에는 원소가 10개인 1차원 배열이 저장됩니다.

이미지 여러장을 한번에 넣는 것을 생각해봅시다. 가령 이미지 100개를 묶어 predict() 함수에 전달할 수 있따면 시간을 절약할 수 있을 것입니다. 이처럼 하나로 묶은 입력 데이터를 배치(batch)라고 합니다.
100개를 한 묶음으로 predict()함수에 넣는다면 배치처리를 위한 가중치 배열들은 다음과 같은 형상이 될 것입니다.

우선, 이미지 한 장당 784의 픽셀(출력층 : 784개의 뉴런)을 갖음으로 100 x 784인 이차원 배열이 x에 전달되어야 합니다. 이 이차원 배열은 W1, W2, W3 가중치 묶음이 차례대로 연산에 적용되어 결국 100 x 10의 이차원 배열이 y값에 저장되는 것입니다. 100 x 10의 이차원 배열은 출력층의 10개의 뉴런에 맞는 10개의 원소 묶음이 100개(100묶음을 한 묶음으로 집어넣었음으로) 있는 것입니다.
x, t = get_data()
network = init_network()
batch_size = 100 # 배치 크기
accuracy_cnt = 0
#x_test의 길이(시험 이미지의 개수)만큼, 배치 크기 간격만큼 반복문을 수행
for i in range(0, len(x), batch_size):
#batch_in에 입력 이미지를 배치 크기만큼 묶어서 보관해둠
batch_in = x[i:i+batch_size]
#batch_in의 저장된 한 묶음씩 predict()를 통과후 y에 저장
y = predict(network, batch_in)
#axis=1(각 행에 모든 열에서 동작)을 기준으로 최댓값의 인덱스 반환
p = np.argmax(y, axis=1)
#한 묶음씩 예측 성공한 개수를 다 더한후 총 accuracy_cnt에 저장
accuracy_cnt += np.sum(p==t[i:i+batch_size])
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))다음은 배치처리를 직접 구성한 것입니다. range() 함수가 반환하는 리스트를 바탕으로 x[i:i+batch_size]에서 입력 데이터를 묶습니다. x[i:i+batch_size]는 입력 데이터의 i번째부터 i+batch_n-1번째까지의 데이터를 묶는다는 의미입니다.
