💡오늘 배울 내용
데이터를 통해 결과를 얻어내는 방법은 여러가지 단계에 거쳐 진화해왔습니다. 신경망(딥러닝) 이외에도 데이터를 통해 기계를 학습시키는 여러 방법을 살펴봅시다.

🔎데이터 주도 학습
데이터를 가지고 결과를 얻어내는 세가지의 방법이 있습니다.
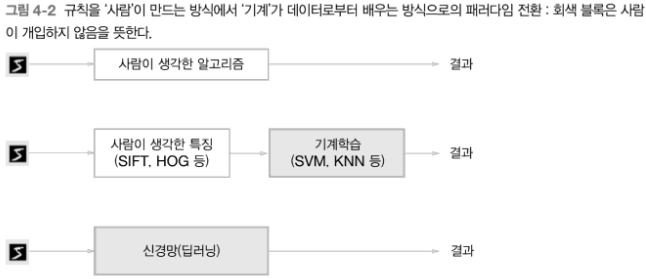
여러 손글씨 이미지를 보고 '5'인지 아닌지를 구별하는 프로그램을 만든다고 합시다. 가장 단순하지만 구현은 어려운 방법으로 5를 특징짓는 규칙을 사람이 생각하고, 이를 알고리즘화 하는 방법이 있을 수 있습니다. 물론 사람마다 버릇이 달라 숨은 규칙성을 명확한 로직으로 만드는 것은 매우 까다롭습니다.
'5'를 인식하는 알고리즘을 설계하는 대신, 주어진 데이터를 활용할 수도 있습니다. 이미지에서 특징을 추출하고, 그 특징의 패턴을 기계학습 기술로 학습하는 것입니다. 입력 데이터를 특징 벡터(Feature Vector)로 기술하고 변환된 벡터를 가지고 지도 학습 방식의 분류 기법(SVM, KNN 등)을 적용하는 것이 그 예 입니다. 컴퓨터 비전 분야에서는 특징 벡터로 SIFT, SURF, HOG를 많이 사용했었습니다. 이러한 방법을 통틀어 머신러닝(기계학습=Machine Learning)이라고 부릅니다.
세번째 방법은 드디어 딥러닝(신경망)을 활용하는 것입니다. 신경망(딥러닝)은 이미지를 있는 그대로 학습합니다. 머신러닝에서는 특징을 사람이 설계해야하지만, 신경망은 이미지에 포함된 중요한 특징까지도 기계가 스스로 학습합니다. 이런 특징때문에 딥러닝을 종단간 기계학습(end-to-end machine learning) 이라고도 합니다.
🔎훈련/시험 데이터
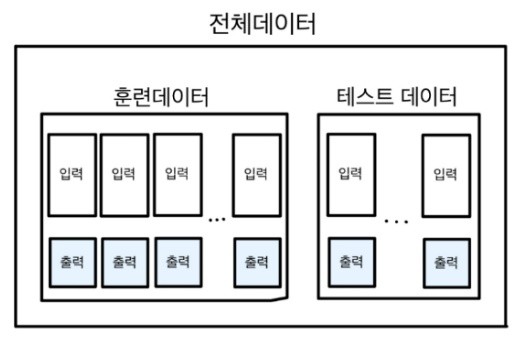
기계학습 문제는 훈련 데이터와 시험 데이터로 나눠 학습과 실험을 수행합니다. 우선 훈련 데이터만 사용하여 학습하면서 최적의 매개변수를 찾습니다. 그리고 시험 데이터를 사용해 앞서 훈련한 모델의 실력을 평가하는 과정을 거칩니다.
데이터를 나누는 이유는 아직 보지 못한 데이터로도 문제를 풀어내는 범용 능력을 제대로 평가하기 위함입니다.
데이터셋 하나로만 학습과 평가를 수행하면 한 데이터셋에 지나치게 최적화(Overfitting)된 모델을 얻을 수도 있습니다. 이러한 오버피팅을 주의해야 객관적으로 훌륭한 모델을 설계할 수 있습니다.