
💡오늘 배울 내용
'결측치'란 데이터프레임 내 비어있는 데이터를 의미합니다. 데이터의 결측치를 처리하는 메서드들을 배워봅시다.
🔎데이터 채우기
데이터프레임 내의 결측치(NaN) 데이터들을 채울때 df.fillna()메서드를 사용할 수 있습니다.
🔔데이터 불러오기
실습에 사용할 데이터입니다.
import pandas as pd
import numpy as np
data = {
'이름' : ['유재석', '박명수', '정준하', '노홍철', '정형돈', '하하'],
'지역' : ['서울', '부산', np.nan, '서울', '서울', '서울'],
'나이' : [19, 23, 20, 25, 18, 21],
'국어점수' : [86, 90, 80, 65, 50, 60],
'수학점수' : [86, 100, 66, 70, 40, 80],
'코딩' : ['Python', 'Java', np.nan, 'Javascript', 'PYTHON', np.nan]
}
df = pd.DataFrame(data, index=['1번', '2번', '3번', '4번', '5번', '6번'])
df.index.name = '번호'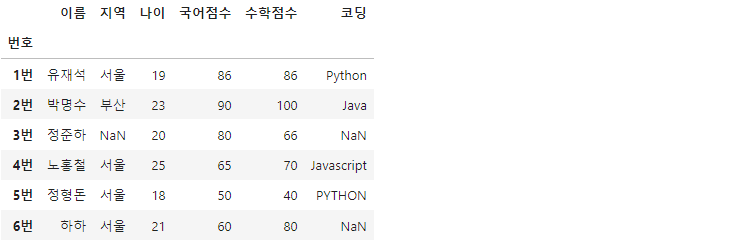
🔔결측치 지정하기
결측치(Missing Value)는 말 그대로 데이터에 값이 없는 것을 뜻합니다. 줄여서 'NA'라고 표현하기도 하고, 다른 언어에서는 Null 이란 표현을 많이 씁니다. 결측치는 데이터를 분석하는데에 있어서 매우 방해가 되는 존재입니다.
결측치를 지정하고 싶다면, 넘파이를 임포트하여 np.nan을 통해 쉽게 지정할 수 있습니다.
import numpy as np
df['지역'] = np.nan #지역 데이터 전체를 NaN으로 채움
df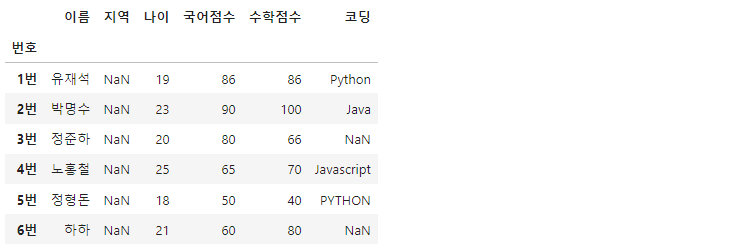
상단의 코드는 데이터프레임의 '지역'컬럼 내 데이터들을 모두 결측치로 지정한 모습입니다.
🔔df.fillna()
df.fillna('') #NaN 데이터를 빈칸으로 채움
df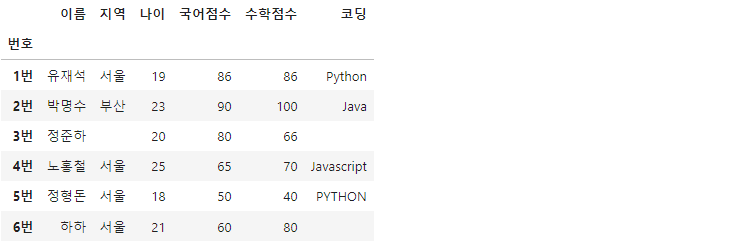
위의 데이터에서 결측치는 총 세군데입니다. NaN으로 되어있는 결측치들을 빈칸으로 채웠습니다. 만약 데이터프레임에 바로 반영시키려면 inplace 옵션을 이용할 수 있습니다.
df.fillna('없음') #NaN 데이터를 '없음'으로 채움
df
결측치를 무엇으로 채울지는 임의로 정할 수 있습니다. 이번에는 결측치 데이터가 '없음' 문자열로 채워졌습니다.
df['코딩'].fillna('확인중', inplace=True)
df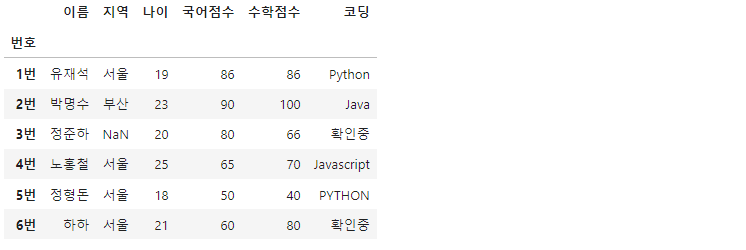
상단의 코드에서처럼 데이터프레임 전체의 결측치를 한번에 채우지 않고, 원하는 컬럼만 채우는 것도 가능합니다.
🔎데이터 제외하기
결측치는 데이터 분석에 방해가 될 가능성이 높습니다. 데이터프레임 내의 결측치(NaN)를 포함하는 데이터들을 지울때 df.dropna()메서드를 사용할 수 있습니다. 데이터 채우기 실습과 같은 데이터프레임을 불러와 실습을 진행합니다.
🔔df.dropna()
df.dropna(inplace=True) #전체 데이터 중에서 NaN을 포함하는 데이터 삭제
df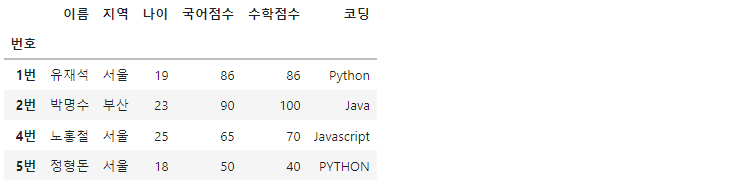
전체 데이터 중에서 결측치를 포함하는 데이터(행;row)를 지워버립니다.
🔔dropna() 옵션
dropna() 메서드를 사용할때 axis와 how옵션을 사용할 수 있습니다.
dropna() 옵션
- axis : index(0) or columns(1)
- how : any or all
axis 옵션에는 index와 columns가 있습니다. axis로 index를 지정하면, 결측치 데이터를 지울때 결측치가 포함된 행을 지웁니다. axis로 columns를 지정하면, 결측치가 들어있는 컬럼을 지웁니다. 나머지 데이터는 보존하겠다는 의미입니다.
how 옵션에는 any와 all이 있습니다. how로 any를 지정하면 결측치가 하나라도 있을때 결측치를 지운다는 의미입니다. how로 all을 지정하면 axis 매개변수에 따라 결정된 행 혹은 열에 대해, 모든 값이 결측치여야 삭제가 이루어집니다.
df.dropna(axis='index', how='any') #NaN가 하나라도 있는 row 삭제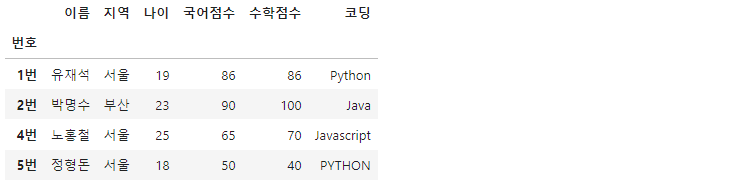
how 옵션이 any임으로 결측치가 하나라도 있는 행을 삭제합니다.
df.dropna(axis='columns', how='all')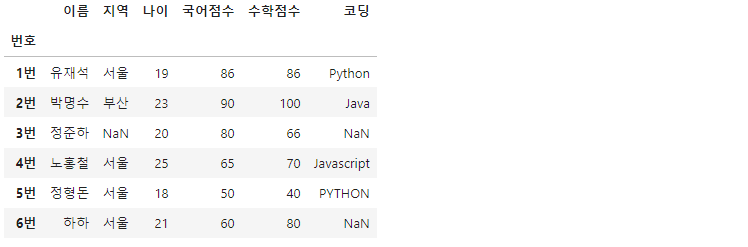
how 옵션이 all임으로 모든 컬럼 내 데이터가 결측치여야 삭제가 이루어집니다. 즉, 어떤 데이터도 삭제되지 않았습니다.
