
💡오늘 배울 내용
loc/iloc을 통해서 데이터를 선택하는 방법에 이어, 일정한 조건을 만들어 데이터를 불러오는 방법을 알아봅시다.
🔎데이터 선택(조건)
불리안 인덱싱을 이용해서 조건에 맞는 데이터만 불러올 수 있습니다.
🔔데이터 불러오기
실습에 사용할 데이터 프레임입니다.
import pandas as pd
import numpy as np
data = {
'이름' : ['유재석', '박명수', '정준하', '노홍철', '정형돈', '하하'],
'지역' : ['서울', '부산', '부산', '서울', '서울', '서울'],
'나이' : [19, 23, 20, 25, 18, 21],
'국어점수' : [86, 90, 80, 65, 50, 60],
'수학점수' : [86, 100, 66, 70, 40, 80],
'코딩' : ['Python', 'Java', np.nan, 'Javascript', 'PYTHON', np.nan]
}
df = pd.DataFrame(data, index=['1번', '2번', '3번', '4번', '5번', '6번'])
df.index.name = '번호'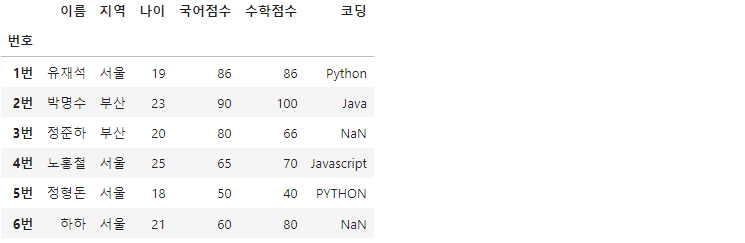
🔔불리안 인덱싱
불리안 인덱싱은 True일때는 값을 반환하고 False일때는 값을 반환하지 않는 것을 이용하는 것입니다. 조건을 적용한 필터를 만들어 놓고, 이 필터를 통해 데이터 프레임에서 원하는 값만 불러옵니다.
df['나이'] > 20
비교 연산자를 적용함으로써 불리안(Boolean) 변수를 값으로 하는 시리즈가 만들어집니다. 이 시리즈를 필터로 쓰면 조건에 맞는 값을 불러올 수 있습니다.
# (1)조건에 맞는 필터 생성
filt = df['나이'] > 20
df[filt]
# (2)필터를 생략
df[df['나이'] > 20]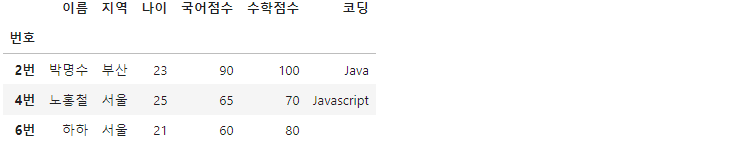
상단의 코드 (1)과 (2)는 df[] 구문에 필터(20 이상의 '나이' 값을 가진 자료만 출력)를 적용하여 3개의 자료를 골라 출력하고 있습니다.
df[~filt]
연산자 ~를 사용하여 출력하면, 조건과 반대되는 값들을 빠르게 보여줍니다.
🔔loc 사용하기
인덱스 이름을 사용해 값을 불러오는 df.loc[]문법에 불리안 인덱싱을 섞어 사용할 수 있습니다.

https://velog.io/@jhdai_ly/판다스Pandas데이터-선택Data-Selection1-기본-loc을-사용한-데이터-선택
df.loc[df['나이'] >= 20, '수학점수'] #행조건(불리안 인덱싱), 열조건(수학점수만 보고싶음)
df.loc[]은 행조건과 열조건이 필요합니다. 상단의 코드는 불리안 인덱싱을 통해 '나이'를 가지고 행을 선택하고, 열 조건에는 '수학점수' 컬럼을 명시하여 원하는 값을 시리즈로 불러옵니다.
df.loc[df['나이'] >= 20, ['이름', '지역','수학점수']]
대괄호로 여러개의 컬럼명을 감싸면 여러개의 컬럼을 볼 수 있습니다. 이와같은 활용이 어렵다면 지난번 학습했던 loc/iloc 개념을 복습해보길 바랍니다.
🔔조건연산자 활용
조건문을 작성할때 사용하는 연산자를 사용하여 조건을 구성할 수 있습니다. 대표적으로 & (그리고)와 | (또는)이 있습니다.
df.loc[(df['나이']>=20) & (df['지역']=='부산')]
조건연산자 그리고(&)를 사용해 두가지의 컬럼('나이', '지역')을 검사하여 해당하는 자료 두개를 출력하고 있습니다. df.loc[]에 행 조건만 입력(행 조건에 맞는 모든 컬럼 출력)한 예입니다.
df.loc[(df['나이']<20) | (df['수학점수']>80)]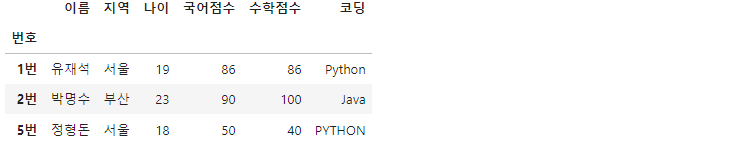
조건연산자 또는(|)을 사용해 두가지의 컬럼('나이', '수학점수')을 검사하여 해당하는 자료 세개를 출력하고 있습니다. 역시 df.loc[]문법의 기준으로 봤을때는 행 조건만 입력한 것입니다.
🔔str 함수
문자열과 관련된 함수를 통해 조건에 맞는 필터링을 할 수 있습니다. 데이터프레임 컬럼의 자료형이 object(문자열)인 경우 이와같은 필터링이 유용할때가 많습니다.
filt = df['이름'].str.startswith('유') #'유'씨 성을 가진 사람
print(filt)
>>
str 함수 startswith(해당하는 문자로 시작하는지 검사)를 사용하면 불리안(boolean) 타입의 변수가 값으로 된 시리즈가 만들어집니다. 이 시리즈를 사용하여 불리안 필터링과 같은 원리로 데이터프레임의 원하는 값을 불러오는 것입니다.
filt = df['이름'].str.startswith('유') #'유'씨 성을 가진 사람
df[filt]
'이름' 컬럼의 데이터중 '유'로 시작하는 값을 가지고 있는 데이터는 '1번' 인덱스의 자료 하나임으로 한개의 자료가 출력된 것을 확인할 수 있습니다.
filt = df['이름'].str.contains('하') #이름에 '하'가 들어가는 사람
df[filt]
str 함수 'contains(해당하는 문자가 포함되는지 검사)'를 사용하여 '하'가 포함된 '3번'과 '6번' 인덱스의 자료가 출력됐습니다.
coding = ["python", "java"]
filt = df['코딩'].isin(coding)
print(filt)
>>
우선, .isin() 메서드는 리스트를 입력받아 리스트에 해당하는 값이 해당 컬럼의 데이터들에 들어있는지 검색하여 불리안 타입의 시리즈를 만들어 냅니다. 상단의 코드에서 모든 값들이 False인 이유는 우리의 데이터프레임의 '코딩' 컬럼에는 'python'과 'java'라는 값이 없기 때문입니다. 자세히 보면 'python'이 아닌 'Python'과 'PYTHON'으로 저장되어 있고, 'java'가 아닌 'Java'로 저장되어 있습니다.
이러한 문제를 해결하기 위해 문자열 함수 str.lower()를 사용할 수 있습니다.
coding = ["python", "java"]
filt = df['코딩'].str.lower().isin(coding)
df[filt]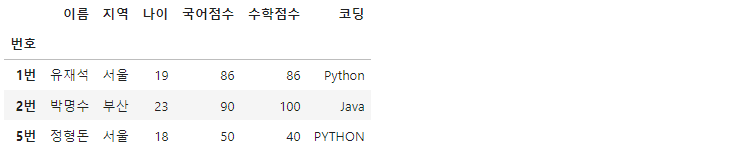
상단의 코드는 문자열 함수 str.lower()을 사용해 대소문자의 구별 없이도 값을 출력할 수 있도록 조정한 것입니다. df['코딩']에 먼저 str.lower()가 적용됐고(해당 컬럼의 모든 값들이 소문자로 바뀜),.isin()메서드가 이후에 값을 필터링하여 출력합니다. 참고로 .isin() 메서드는 앞에 Series가 올때 리스트, set과 같은 자료형을 입력받을 수 있습니다.
#NaN 데이터 처리할때 조심
filt = df['코딩'].str.contains('Java', na=False)
df[filt]
str.contains() 함수를 사용할때 주의점이 있습니다. 적용하고자 하는 컬럼에 NaN(빈) 데이터가 존재하는 경우입니다. contains() 함수가 불리안(Boolean) 자료형으로 된 시리즈를 만들때 NaN 데이터를 어떻게 취급(True or False) 할 것인지 정해주어야 합니다. 상단의 코드에는 값이 없는 NaN 데이터를 False로 취급해주고 있기때문에 출력 결과로 뜨지 않는 것입니다.
