
💡오늘 배울 내용
동일한 값을 가진 것들끼리 뭉쳐서 계산을 쉽게 할 수 있습니다. 그룹화 문법을 공부해봅시다.
🔎데이터 불러오기
import pandas as pd
import numpy as np
data = {
'이름' : ['유재석', '박명수', '정준하', '노홍철', '정형돈', '하하'],
'지역' : ['서울', '부산', '부산', '서울', '서울', '서울'],
'전공' : ['문과', '이과', '이과', '이과', '문과', '문과'],
'나이' : [19, 23, 20, 25, 18, 21],
'국어점수' : [86, 90, 80, 65, 50, 60],
'수학점수' : [86, 100, 66, 70, 40, 80],
'코딩' : ['Python', 'Java', np.nan, 'Javascript', 'PYTHON', np.nan]
}
df = pd.DataFrame(data, index=['1번', '2번', '3번', '4번', '5번', '6번'])
df.index.name = '번호'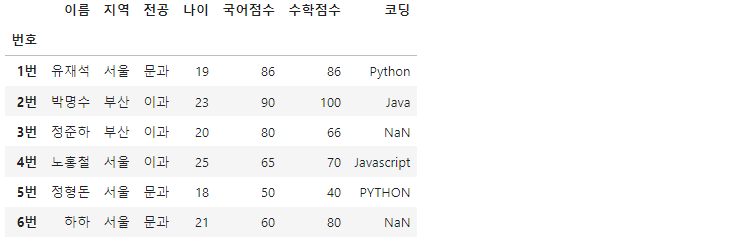
🔎groupby()
같은 값을 하나로 묶어 통계 또는 집계 결과를 얻기 위해 사용하는 것이 groupby()입니다. 기본적인 groupby() 문법을 알아봅시다.
🔔mean()
'지역' 별로 값들의 평균을 구하고 싶을때 groupby().mean()을 이용합니다. 그룹 지정을 하면, 자동으로 그룹 라벨이 index가 됩니다. 인덱스를 없애라면 groupby()의 옵션으로 as_index=False를 설정할 수 있습니다.
df.groupby('지역').mean()
df.groupby('전공')['국어점수'].mean()
>> 전공
문과 65.333333
이과 78.333333
Name: 국어점수, dtype: float64상단의 코드는 '전공'을 기준으로 묶은 뒤, '국어점수'의 평균을 확인하는 코드입니다. '국어점수' 외에도 여러개를 확인하고 싶다면, [['국어점수', '수학점수', '나이']] 처럼 팬시 인덱싱을 이용하면 됩니다.
그룹 지정은 여러개를 할 수도 있습니다.
df.groupby(['지역', '전공']).mean()
상단의 코드는 '지역'과 '전공' 두가지를 그룹으로 지정하여 평균을 확인합니다.
🔔mean().sort_values()
그룹 지정 후, 정렬하여 출력 할 수 있습니다. 자료들의 평균을 지정한 기준에 맞게 순서대로 출력합니다.
df.groupby('지역').mean().sort_values('국어점수')
df.groupby('지역').mean().sort_values('국어점수', ascending=False)
상단의 코드를 보면, '지역'으로 묶은 후, '국어점수'를 기준으로 순서를 정해 출력되고 있는 것을 확인 할 수 있습니다.
🔔sum()
df.groupby(['지역']).sum()
'지역'을 기준으로 묶은 후, 값들을 다 합한 결과를 출력합니다.
df.groupby(['지역', '전공']).sum()
값들을 다 합한 결과를 출력하되, '지역'과 '전공' 두가지를 기준으로 합니다.
🔔count()
df.groupby()[].count()
df.groupby('지역')['코딩'].count()
>> 지역
부산 1
서울 3
Name: 코딩, dtype: int64'지역'을 기준으로 묶은 뒤, '코딩' 컬럼에 저장된 데이터의 수를 셉니다.
df.groupby('지역')[['이름', '코딩']].count()
'지역'을 기준으로 묶은 뒤, '이름'과 '코딩' 컬럼에 저장된 데이터 수를 세서 각각 보여줍니다. 부산 지역의 두 명의 학생 중 프로그래밍 언어를 아는 학생은 한명이 있고, 서울 지역의 세명의 학생 중 프로그래밍 언어를 아는 학생은 세명이 있음을 알 수 있습니다.
🔔value_counts()
df.groupby()[].value_counts()
df.groupby('지역')['전공'].value_counts()
>> 지역 전공
부산 이과 2
서울 문과 3
이과 1
Name: 전공, dtype: int64value_counts()는 값별로 데이터의 수를 출력해주는 함수입니다. 상단의 코드는 '지역'을 기준으로 묶고, '전공' 컬럼에 들어있는 데이터 수를 출력합니다.
df.groupby('지역')['전공'].value_counts().loc['서울']
>> 전공
문과 3
이과 1
Name: 전공, dtype: int64loc() 문법을 이용하여 그중 '서울'에 해당하는 데이터만 불러올 수 있습니다.
df.groupby('지역')['전공'].value_counts(normalize=True).loc['서울']
>> 전공
문과 0.75
이과 0.25
Name: 전공, dtype: float64value_counts의 옵션으로 normalize=True를 선택하면 비율을 확인할 수 있습니다.
🔎groupby() 특성
groupby() 오브젝트 특성입니다. groupby()에 붙여 사용합니다.
🔔get_group()
그룹 안에 데이터를 확인하고 싶을때 groupby().get_group()을 이용합니다.
df.groupby('지역').get_group('서울')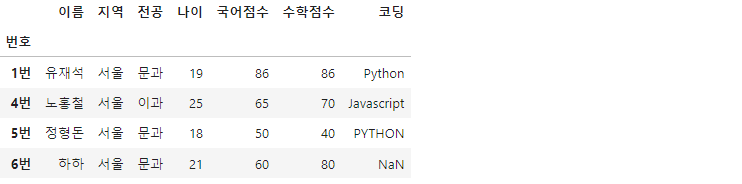
'지역'을 기준으로 했을때 '서울'에 해당하는 자료들을 불러옵니다.
🔔size()
각 그룹의 사이즈를 확인할때 groupby().size()를 이용합니다.
df.groupby('지역').size()
>> 지역
부산 2
서울 4
dtype: int64df.groupby('지역').size()['서울']
>> 4전체 자료에서 '지역'을 기준으로 묶었을때 각각 몇개로 묶이는지(size)를 시리즈로 반환해서 보여줍니다. 반환된 배열에서 특정 그룹의 사이즈만을 얻을 수도 있습니다.
