💡오늘 배울 내용
데이터프레임의 컬럼과 row(행)을 수정, 삭제, 추가하는 방법을 알아봅시다.
🔎컬럼(Column)
컬럼은 같은 타입의 자료형으로 되어있는 데이터프레임의 세로줄 영역입니다.
🔔데이터 불러오기
import pandas as pd
import numpy as np
data = {
'이름' : ['유재석', '박명수', '정준하', '노홍철', '정형돈', '하하'],
'지역' : ['서울', '부산', '부산', '서울', '서울', '서울'],
'나이' : [19, 23, 20, 25, 18, 21],
'국어점수' : [86, 90, 80, 65, 50, 60],
'수학점수' : [86, 100, 66, 70, 40, 80],
'코딩' : ['Python', 'Java', np.nan, 'Javascript', 'PYTHON', np.nan]
}
df = pd.DataFrame(data, index=['1번', '2번', '3번', '4번', '5번', '6번'])
df.index.name = '번호'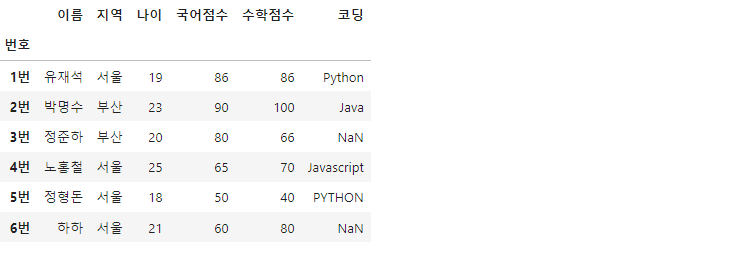
🔔컬럼 수정
- replace() 메서드
- 컬럼 수정 후 재(再)바인딩
df['지역'].replace({"서울":"경기", "부산":"대구"}, inplace=True)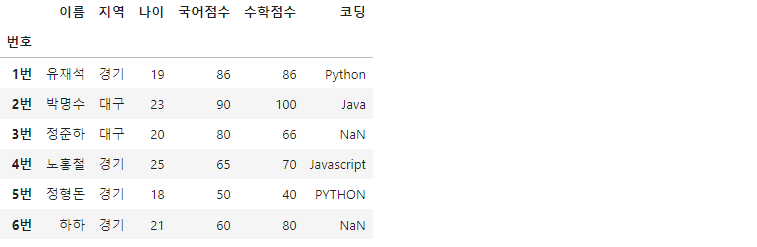
'지역' 컬럼에 '서울'과 '부산'이 '경기'와 '대구'로 바꼈다면, replace() 메서드를 통해 컬럼 내용을 수정해줄 수 있습니다.
df['코딩'] = df['코딩'].str.lower()
df대소문자가 섞여있는 '코딩'컬럼을 모두 소문자로 바꾸고 싶다면, 문자열 함수 str.lower()을 적용할 수 있습니다. df['코딩']에 str.lower() 함수를 적용하면 컬럼이 수정된 시리즈가 불러지는데, 이를 다시 df['코딩']에 바인딩해줌으로써 데이터프레임을 수정할 수 있습니다.
모두 대문자로 바꾸려면, str.upper()함수도 있습니다.
🔔컬럼 추가
df['점수총합'] = df['국어점수'] + df['수학점수']
df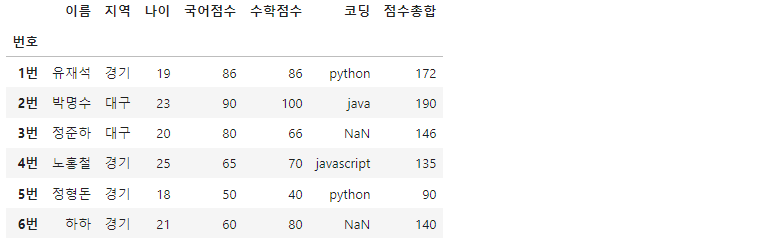
다음과 같이 새로운 컬럼을 추가할 수 있습니다.
df['결과'] = '불합격' #결과 컬럼 생성 후, '불합격'으로 초기화하기
df.loc[df['점수총합']>160, '결과'] = '합격' #총합 160 넘으면 '합격'
df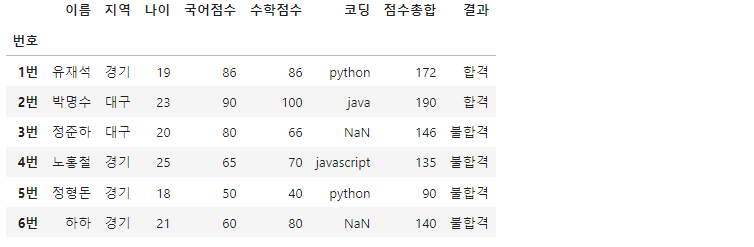
상단의 코드는 '결과'라는 새로운 컬럼을 만들고, df.loc() 메서드를 사용하여 두 점수의 합 160을 기준으로 합격과 불합격을 나누고 있습니다.
🔔컬럼 삭제
df.drop(columns=['점수총합'], inplace=True)
dfdrop() 메서드를 통해 기존의 컬럼을 삭제할 수 있습니다.
🔎Row(행)
행은 데이터프레임의 가로줄 부분으로 다양한 컬럼들로 구성되는 담고있는 하나의 개체에 해당합니다. 데이터를 다시 불러와 실습해봅시다.
🔔데이터 불러오기
import pandas as pd
import numpy as np
data = {
'이름' : ['유재석', '박명수', '정준하', '노홍철', '정형돈', '하하'],
'지역' : ['서울', '부산', '부산', '서울', '서울', '서울'],
'나이' : [19, 23, 20, 25, 18, 21],
'국어점수' : [86, 90, 80, 65, 50, 60],
'수학점수' : [86, 100, 66, 70, 40, 80],
'코딩' : ['Python', 'Java', np.nan, 'Javascript', 'PYTHON', np.nan]
}
df = pd.DataFrame(data, index=['1번', '2번', '3번', '4번', '5번', '6번'])
df.index.name = '번호'
🔔Row 추가
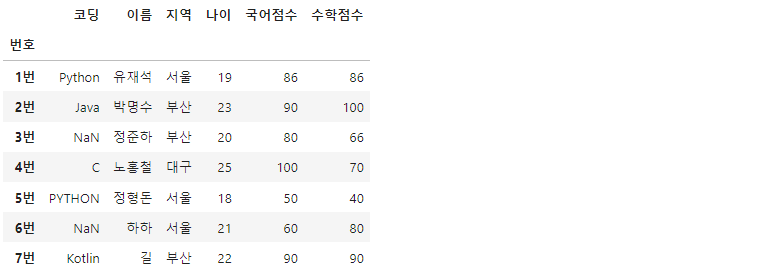
df.loc['7번'] = ['길', '부산', 22, 90, 90, 'Kotlin']
df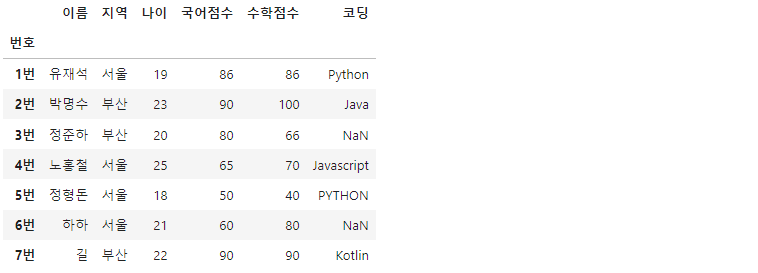
df.loc메서드로 새롭게 만들 row를 지정하고, 각각 자료형에 맞는 값들을 리스트형태로 바인딩해주면 됩니다.
🔔셀 수정
df.loc['4번', '국어점수'] = 100
df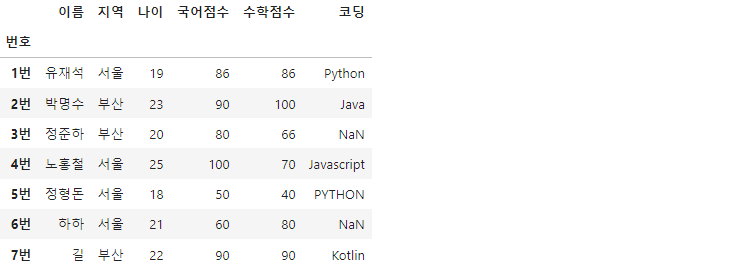
데이터프레임 내 데이터 중, 수정하고 싶은 셀이 있을때 자유롭게 값을 바꿀 수 있습니다. 역시 df.loc메서드로 행과 열을 선택해주고, 새로운 값을 바인딩해주면 됩니다.
df.loc['4번', ['지역', '코딩']] = ['대구', 'C']
df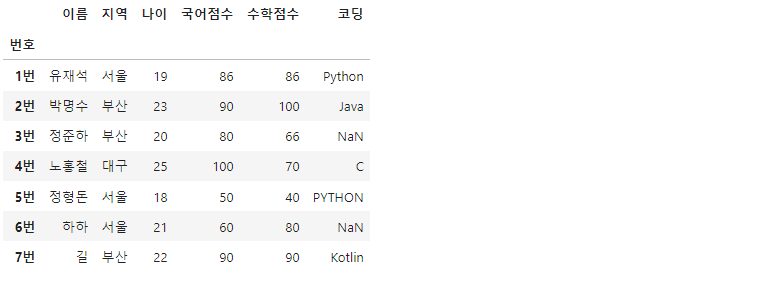
팬시 인덱싱으로 한 행에서 두가지 값을 한번에 바꿀 수도 있습니다.
🔎컬럼 순서 변경
컬럼들을 리스트로 저장하고, 슬라이싱과 더하기 문법으로 컬럼의 순서를 변경할 수 있습니다. 바로 위 코드를 이어서 실습해봅시다.
cols = list(df.columns)
df = df[[cols[-1]] + cols[0:-1]]
df