
💡오늘 배울 내용
판다스 데이터프레임을 거시적인 맥락에서 확인하는 몇가지 방법들을 알아봅시다.
🔎DataFrame 확인
수치적으로 계산할 수 있는 데이터 값들의 정보들을 컬럼(column)별로 확인할 수 있습니다.
🔔데이터 불러오기
import pandas as pd
data = {
'이름' : ['유재석', '박명수', '정준하', '노홍철', '정형돈', '하하'],
'지역' : ['서울', '부산', '부산', '서울', '서울', '서울'],
'나이' : [19, 23, 20, 25, 18, 21],
'국어점수' : [86, 90, 80, 65, 50, 60],
'수학점수' : [86, 100, 66, 70, 40, 80],
'코딩' : ['Python', 'Java', '', 'Javascript', 'PYTHON', '']
}
df = pd.DataFrame(data, index=['1번', '2번', '3번', '4번', '5번', '6번'])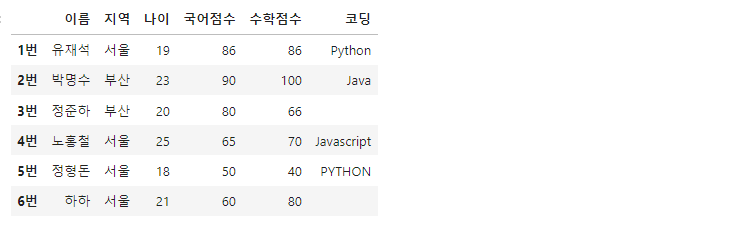
🔔실습
df.describe()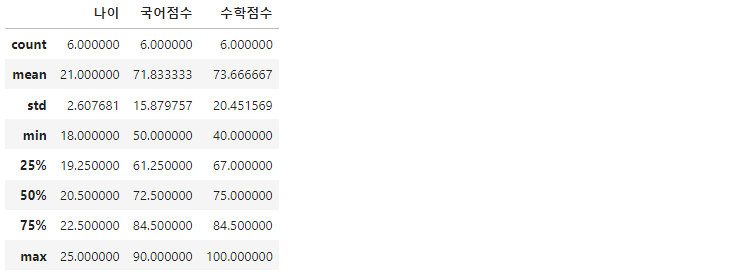
describe() 메서드를 통해 수치적으로 계산할 수 있는 데이터 '나이', '국어점수', '수학점수'에 대해 평균, 최대/최소, 표준편차 등의 전반적인 요약 통계량을 확인할 수 있습니다.
df.info()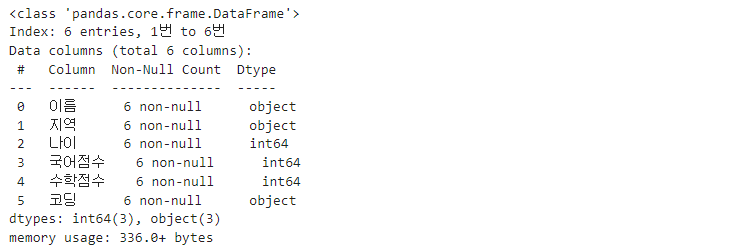
info() 메서드를 통해 데이터프레임을 구성하는 행과 열의 크기, 컬럼명, 컬럼을 구성하는 값의 자료형 등을 출력해볼 수 있습니다.
df.head() #처음 5개의 행(row)을 가져옴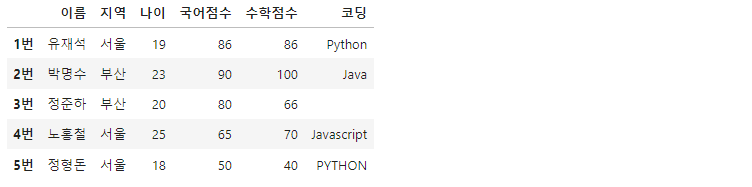
head() 메서드는 처음 5개의 행을 가져와 보여줍니다. 수많은 데이터들로 구성된 데이터프레임 전체를 불러오는게 부담스러울때, 전체적인 데이터 형태를 살펴보기에 좋습니다. head(n)의 형태로 처음부터 n개의 데이터를 불러올 수도 있습니다.
df.tail()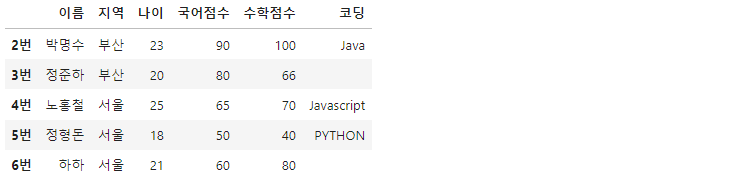
tail() 메서드는 마지막 5개의 행을 보여줍니다. 마찬가지로 tail(n)의 형태로 끝에서부터 n개의 데이터를 불러올 수도 있습니다.
df.values
인덱스를 제외한 값들을 2차원 배열 형태로 불러옵니다.
df.index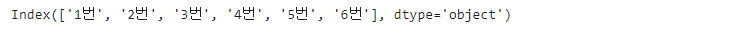
인덱스, 타입 정보등을 확인합니다.
df.columns
컬럼 명을 모두 불러옵니다.
df.shape
데이터프레임의 형상을 불러옵니다.
🔎Series 확인
데이터프레임의 컬럼명으로 Series를 호출하여 여러 정보들을 확인할 수 있습니다.
🔔데이터 불러오기
import pandas as pd
data = {
'이름' : ['유재석', '박명수', '정준하', '노홍철', '정형돈', '하하'],
'지역' : ['서울', '부산', '부산', '서울', '서울', '서울'],
'나이' : [19, 23, 20, 25, 18, 21],
'국어점수' : [86, 90, 80, 65, 50, 60],
'수학점수' : [86, 100, 66, 70, 40, 80],
'코딩' : ['Python', 'Java', '', 'Javascript', 'PYTHON', '']
}
df = pd.DataFrame(data, index=['1번', '2번', '3번', '4번', '5번', '6번'])
🔔실습
df['국어점수'].describe()
df['컬럼명'] 처럼 컬럼 명으로 시리즈를 호출 할 수도 있지만, describe() 메서드와 함께 쓰면 특정 컬럼명에 관련된 정보만 확인할 수 있습니다.
df['국어점수'].min()
>> 50
df['국어점수'].max()
>> 90
df['국어점수'].mean()
>> 71.83333333333333
df['국어점수'].sum()
>> 431확인하고 싶은 통계량을 개별적으로 확인하는 것도 가능합니다.
df['코딩'].count()
>> 4컬럼에 NaN이 포함된 자료라면, 데이터의 개수를 셀때 count() 메서드를 이용할 수도 있습니다.
df['지역'].unique()
>> array(['서울', '부산'], dtype=object)
df['지역'].nunique()
>> 2unique()는 중복을 제외하여 탐색한 자료를 불러옵니다. nunique()는 그 개수를 보여줍니다.
