
💡오늘 배울 내용
DataFrame 객체를 액셀, CSV, 텍스트 파일 등의 형태로 저장하고 불러오는 방법을 알아봅시다.
🔎데이터 확인하기
data = {
'이름' : ['유재석', '박명수', '정준하', '노홍철', '정형돈', '하하'],
'지역' : ['서울', '부산', '부산', '서울', '서울', '서울'],
'나이' : [19, 23, 20, 25, 18, 21],
'국어점수' : [86, 90, 80, 65, 50, 60],
'수학점수' : [86, 100, 66, 70, 40, 80],
'코딩' : ['Python', 'Java', '', 'Javascript', 'PYTHON', '']
}
df = pd.DataFrame(data, index=['1번', '2번', '3번', '4번', '5번', '6번'])
print(df)
>>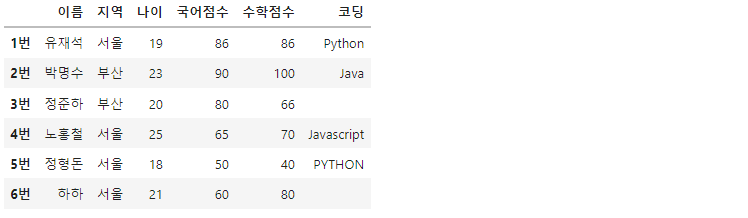
실습을 진행할 데이터입니다.
🔎데이터프레임 저장
판다스의 데이터프레임(DataFrame)을 CSV 파일, 텍스트 파일, 엑셀 파일로 저장해봅시다.
🔔CSV 파일(.csv)
df.to_csv('Jumsoo.csv', encoding='utf-8-sig', index=False)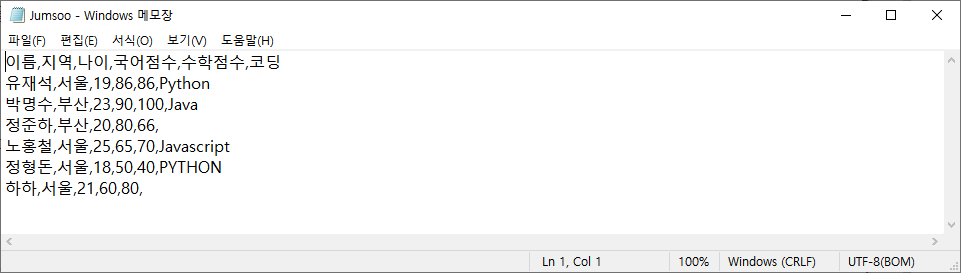
CSV파일이란 'comma-separated values'의 준말로 몇가지 필드를 쉼푤로 구분한 텍스트 데이터 및 텍스트 파일을 말합니다. to_csv() 메서드를 통해 데이터프레임을 CSV파일로 저장할 수 있습니다. 옵션으로 index=False를 지정하면 인덱스를 포함하지 않고 저장됩니다. 지정을 안하면 기존의 index가 별도의 컬럼으로 저장되게 됩니다.
🔔텍스트 파일(.txt)
df.to_csv('Jumsoo.txt', sep='\t', index=False) #tab로 구분된 txt파일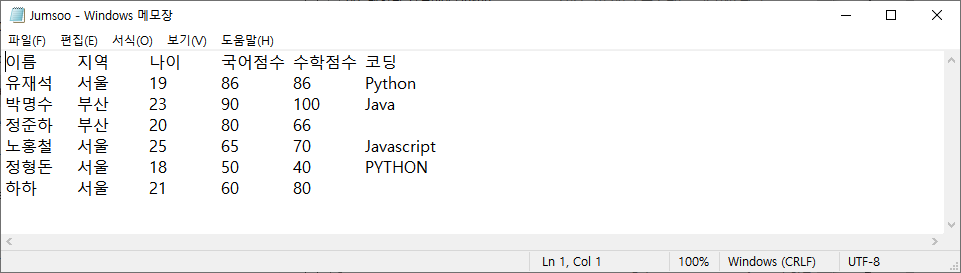
CSV파일로 저장하는 것과 같은 방법으로 텍스트 파일(.txt) 형식으로도 저장할 수 있습니다. sep 옵션을 통해 구분자를 다른 것으로 바꾸는 것도 가능합니다. sep옵션을 사용하지 않으면 CSV파일처럼 콤마를 구분자로 저장합니다.
🔔엑셀 파일(.xlsx)
df.to_excel('Jumsoo.xlsx', sheet_name='점수', index=False)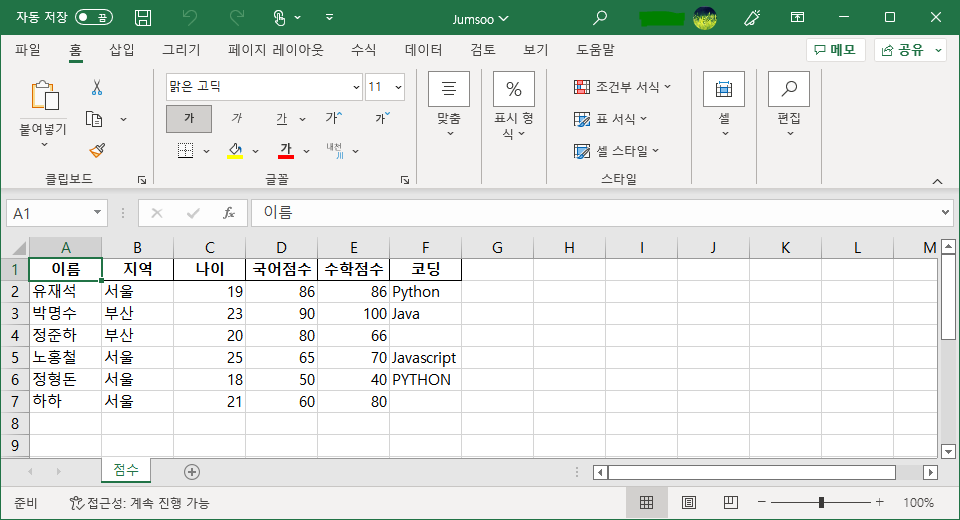
to_excel() 메서드를 통해 DataFrame을 엑셀 파일 형식으로 저장할 수 있으며, 저장시 파일명을 지정합니다. CSV파일을 저장할때와 마찬가지로 index=False 옵션을 사용하면 인덱스를 포함하지 않습니다. sheet_name을 별도로 지정하여 저장할 시트의 이름을 변경할 수도 있습니다.
🔎CSV 파일 열기
df = pd.read_csv('Jumsoo.csv')
print(df)
>>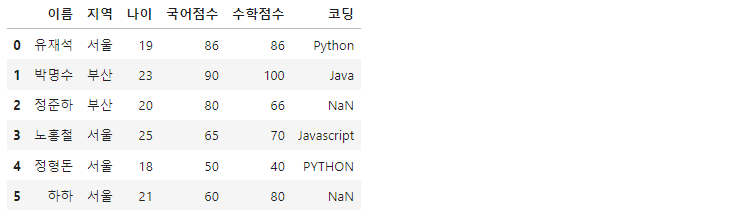
read_csv()를 통해 CSV 파일을 데이터프레임으로 불러올 수 있습니다. RangeIndex가 새롭게 생성됩니다. 당연히 기존에 인덱스를 포함하여 저장했더라도 column으로 인식하여, 밀어내고 RangeIndex가 1열에 생성됩니다.
🔔skiprows
df = pd.read_csv('Jumsoo.csv', skiprows=1)
print(df)
>>
파일을 불러올때 skiprows=n 옵션을 사용하면 지정한 갯수만큼의 행(row)을 건너뛰고 읽어들입니다. 인덱스는 읽어들인 후 생성됩니다.
df = pd.read_csv('Jumsoo.csv', skiprows=[1, 3])
print(df)
>>
skiprows=[] 옵션은 지정한 순서의 행(row)을 제외하고 읽어들입니다. 순서는 0부터 시작하고 역시 인덱스는 읽어들인 후 생성됩니다.
🔔nrows
df = pd.read_csv('Jumsoo.csv', nrows=3)
print(df)
>>
nrows=n 옵션을 통해 지정한 갯수 만큼의 행(row)만 가져올 수 있습니다.
df = pd.read_csv('Jumsoo.csv', skiprows=2, nrows=2)
print(df)
skiprows와 nrows를 섞어서 데이터 출력을 조절할 수 있습니다. skiprows=2를 통해 두개의 열이 제외됐고, nrows=2를 통해 컬럼명으로 사용될 열을 제외하고 정준하, 노홍철 열 두개가 찍힌 것을 확인할 수 있습니다.
🔎텍스트 파일 열기
df = pd.read_csv('Jumsoo.txt', sep='\t')
print(df)
>>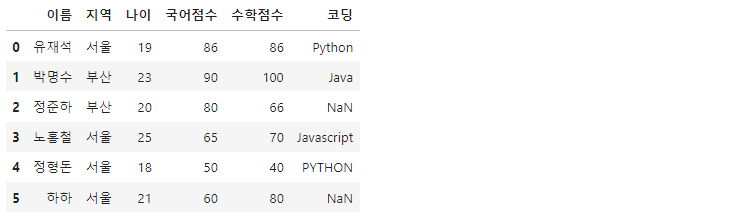
텍스트 파일을 생성할 때 sep='\t'를 통해 구분자를 지정했음으로 불러올때도 sep설정을 해주어야 합니다.
df = pd.read_csv('Jumsoo.txt', sep='\t', index_col='이름')
print(df)
>>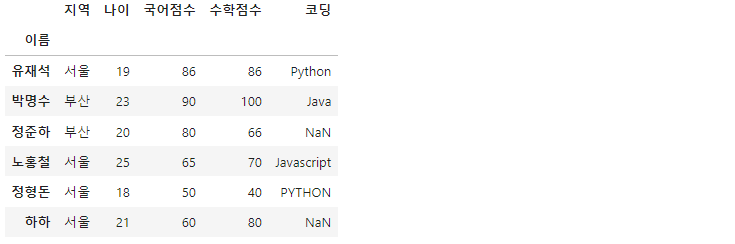
read_csv()의 옵션 중, index_col 옵션을 통해 특정 열 이름으로 인덱스를 지정할 수 있습니다.
🔎엑셀 파일 열기
df = pd.read_excel('Jumsoo.xlsx', index_col='이름')
print(df)
>>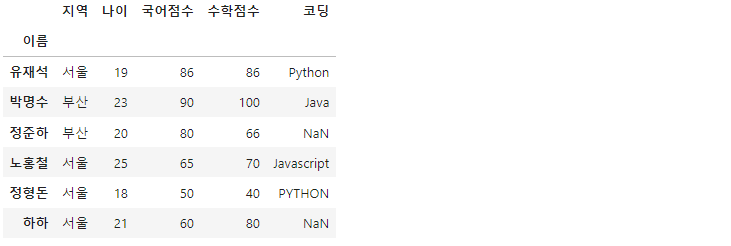
read_excel() 메서드를 이용하여 엑셀 파일을 데이터프레임으로 불러올 수 있습니다. index_col 옵션을 통해 원하는 컬럼을 인덱스로 쓸 수 있습니다.
