2020, DETR - meta
official github : https://github.com/facebookresearch/detr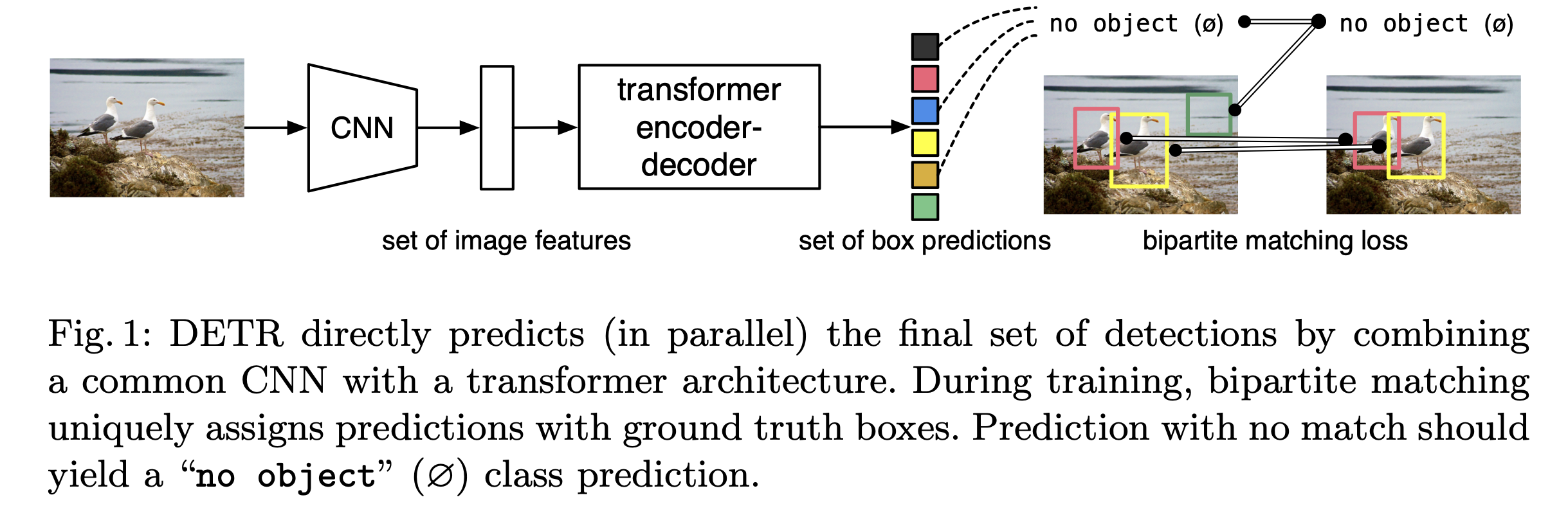
facebook AI 에서 2020년에 공개한 transformer 기반의 one-stage Object Detection model 입니다.
DeTr 논문에서 (2020년도) object detection model 의 문제점으로 지적하는 사항은 다음과 같습니다.
- object detection task 가 bounding box 와 category 를 전부 예측하는 set prediction 으로 심화되었으며, 대부분의 object detection model 은 surrogate detection 과 classification 으로 문제를 나누어서 푼다.
- surrogate detection 은 모델의 class를 고려하지 않고 bounding box 만 찾는 task 입니다.
- 찾아낸 bounding box 에 대해서 label classification 을 수행합니다.
- 또한 object detection 모델은 task 에 대한 사전 지식(prior knowledge)과 hand-designed components 가 많아 다루기 어렵다.
- spatial anchors or non-maximal suppression.
Detr 논문은 아래와 같은 solution 을 제안합니다.
- 해당 모델에서는 parallel decoding 을 통해 단일 모델로 end-to-end 로 bounding box regression 과 label classification 을 해결합니다.
- 해당 모델에서는 사전 지식과 object detection task, 혹은 object detection model 만을 위해서 짜여진 custom layer 가 없습니다.
Detr 논문에 대해서 조금 더 살펴보겠습니다.
모델 구조
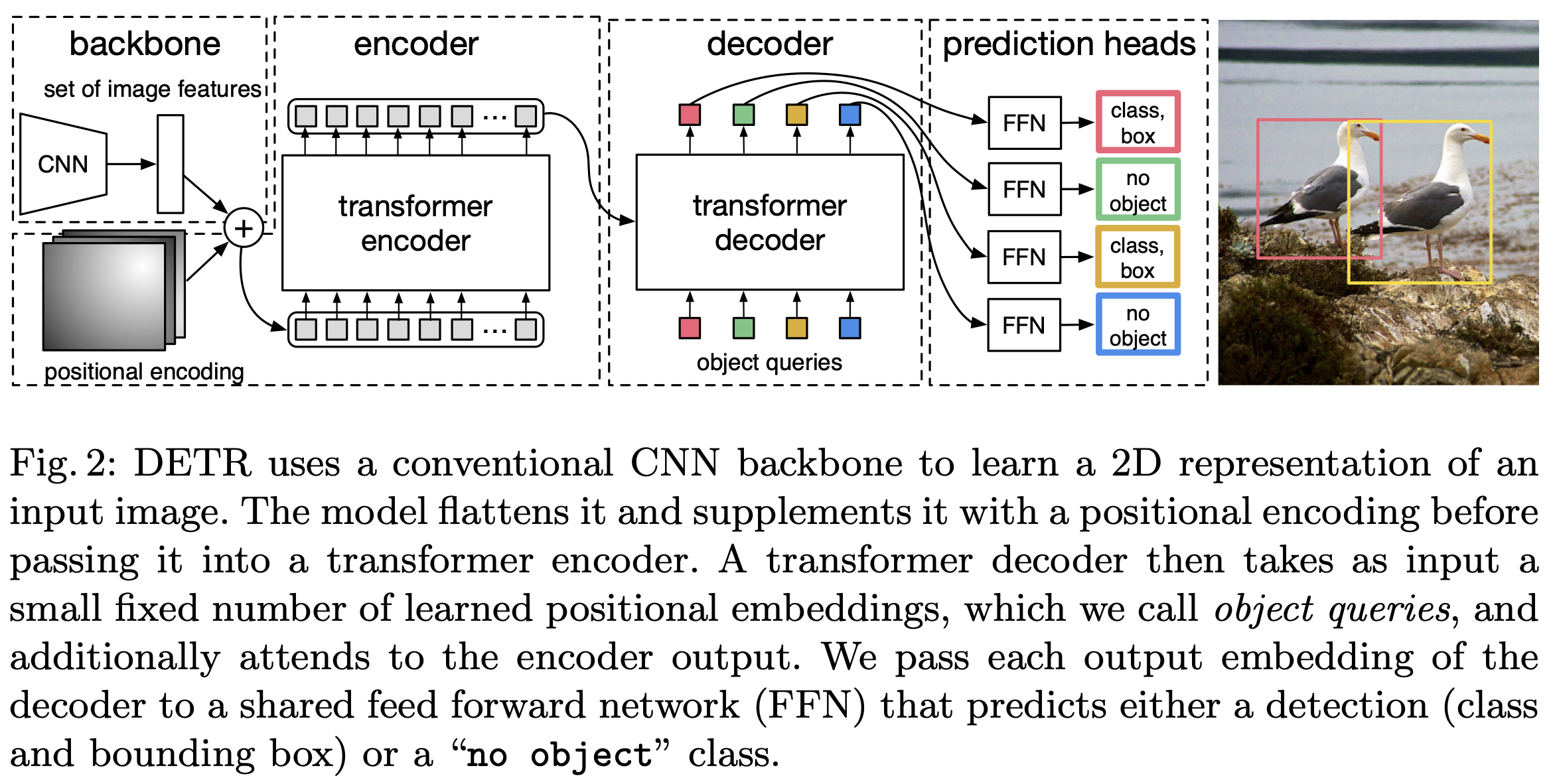
1. backbone
image backbone 으로는 CNN 계열 모델을 사용합니다. 대표적으로 ResNet 이 있습니다.
크기의 원본 이미지는 의 feature map 으로 변환됩니다.
2. Transformer encoder
먼저 convolution 을 이용해 의 feature map 을 로 feature size 를 조정합니다.
크기의 sequence length 와 차원 크기를 가지는 Transformer encoder input 으로 사용합니다.
transformer encoder 의 output vector 역시 차원의 크기를 가집니다.
3. Transformer decoder
일반적인 transformer decoder 와 다르게, transformer decoder 의 input 으로는 개의 object queries가 들어가게 됩니다.
N 은 DeTr 모델이 잡아낼 수 있는 최대 object 수로써 fixed value 입니다.
그리고 object queries 는 미리 학습된 개의 위치 인코딩 값으로써, 훈련 과정에서 학습됩니다.
4. prediction head
transformer decoder 의 output 인 개의 object 에 대해서 3-layer FFN 과 linear projection layer 을 (따로) 통과합니다.
FFN 은 bounding box 의 중앙 좌표, 높이 그리고 너비를 예측하며, linear layer 는 class label 을 예측합니다.
Detr 은 정답 label 에 추가로 "no object" label 을 계산합니다.
모델 학습
1. loss
1-1. bipartite matching loss
문제가 bounding box 의 좌표와 class label 을 동시에 계산하기 때문에, 전혀 다른 class 에 대한 bounding box 의 예측은 오히려 성능을 악화시킬 수 있습니다. Detr 논문은 bipartite matching loss 를 제안합니다.
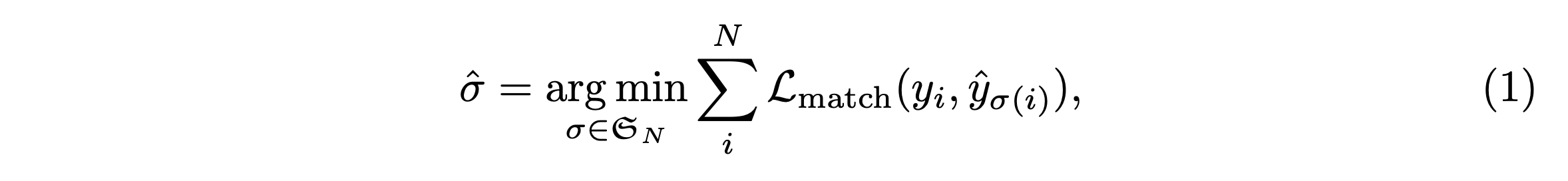
라는 어려워 보이는 식으로 적혀있지만, 의미는 아래와 같습니다.
각 object 예측(bounding box, class) 에 대해서 전체 loss 가 가장 적어지도록 하는 정답에 대해서만 loss 를 계산한다.
즉, 각 예측 값을 전체 loss 가 가장 적어지도록 하는 정답과 matching 해준다.
본 모델은 최적 matching 을 찾는 문제를 최적 할당 알고리즘인 hungarian algorithm 을 통해 해결했습니다.
1-2. classification loss
cross entropy loss 를 사용합니다.
1-3. bounding box loss
bounding box 에 대한 l1 loss 와 generalized IOU loss 를 weighted sum 해서 사용합니다.
l1 loss 는 bounding box 의 크기에 따라 값이 크게 변하기 떄문에 giou loss 를 사용한다고 합니다.

1-4. Hungarian loss
1-1, 1-2, 1-3 을 전부 더합니다.
1-1. 에서 사용된 의 classification loss 와 bounding box loss 의 weighted sum 입니다. 다만, 예측된 class 가 "no object" 인 경우에 대해서는 bounding box loss 를 고려하지 않습니다.
그 후 hungarian algorithm 으로 matching된 예측값-결과값 쌍에 대해서 loss 를 계산합니다.
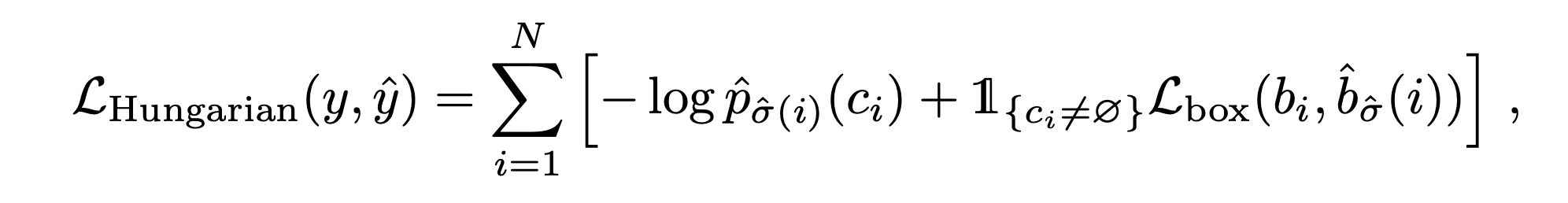
2. Train
COCO2017 detection dataset, panoptic segmentation dataset 을 사용했습니다.
learning rate 는 기본적으로 를, 백본 모델의 parameter 에 대해서는 값을 사용하였습니다. weight decay 는 를 사용하며 초기화는 Xavier init 방법을 사용했습니다.
small object detection 을 해결하기 위해서 backbone 으로 사용된 resnet 의 첫번째 convolution 의 stride 를 제거하고 마지막에 dilation 을 추가해서 배 큰 feature 를 처리하는 모델도 함께 학습시켰습니다.
augmentation. resizing 는 shortest size 가 최소 480, 최대 880 의 값을 가지고 longest size 가 1333 의 최댓값을 가지도록 합니다. 테스트 단에서는 보통 (800, 800) 사이즈로 리사이징 합니다. random crop 을 적용해서 유의미한 성능 향상을 보였다고 합니다.
3. Result
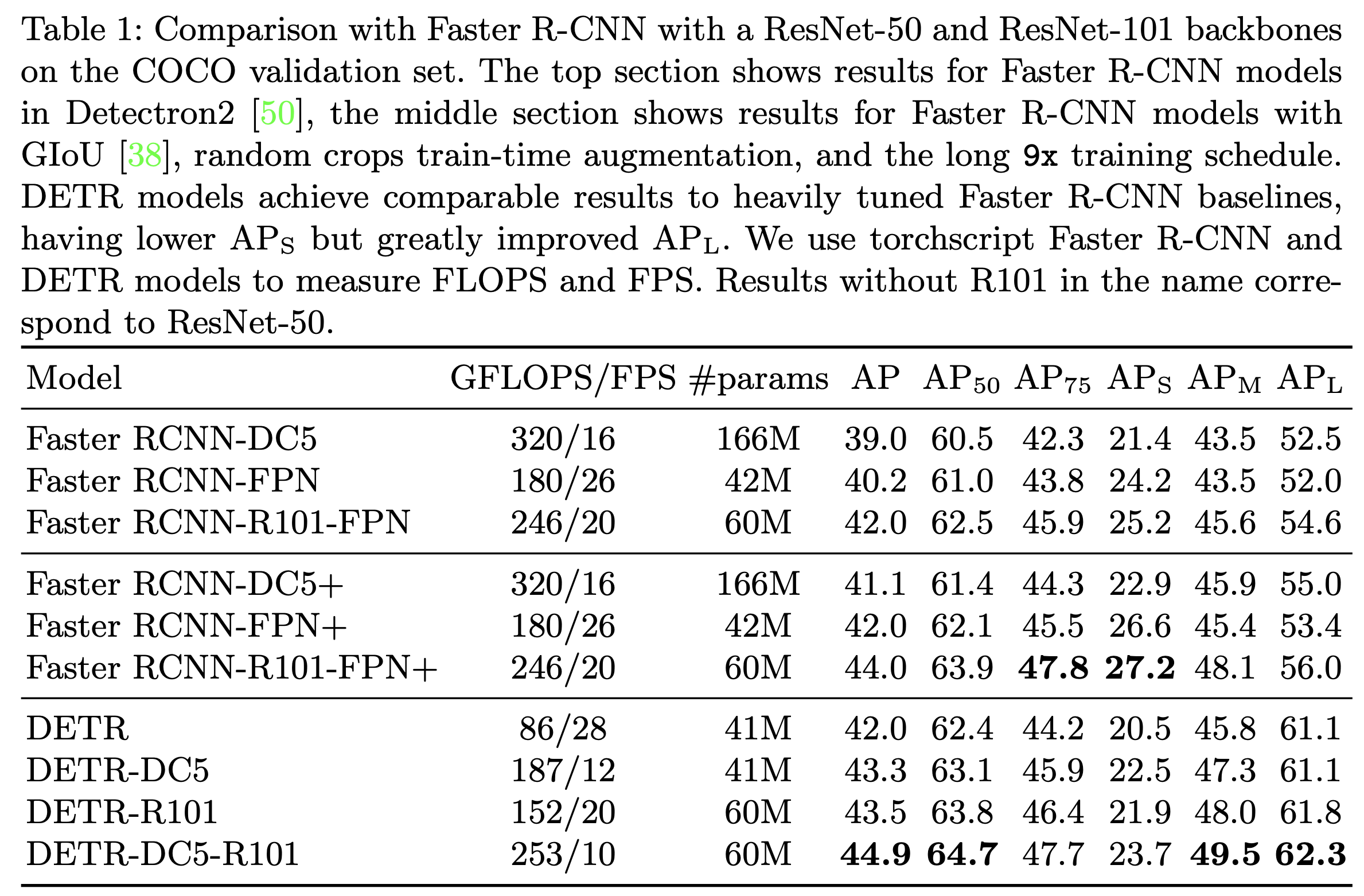
faster R-CNN 과 비교해 전반적인 성능 향상이 있었습니다. 다만 과 은 약간 떨어졌습니다. dilation 과 stride 제거를 한 DETR-DC~ 모델도 faster-RCNN-FP5 에 비해서 성능이 낮습니다. 가 아주 약간 낮은 점은 신경이 쓰이긴합니다.
4. Segmentation
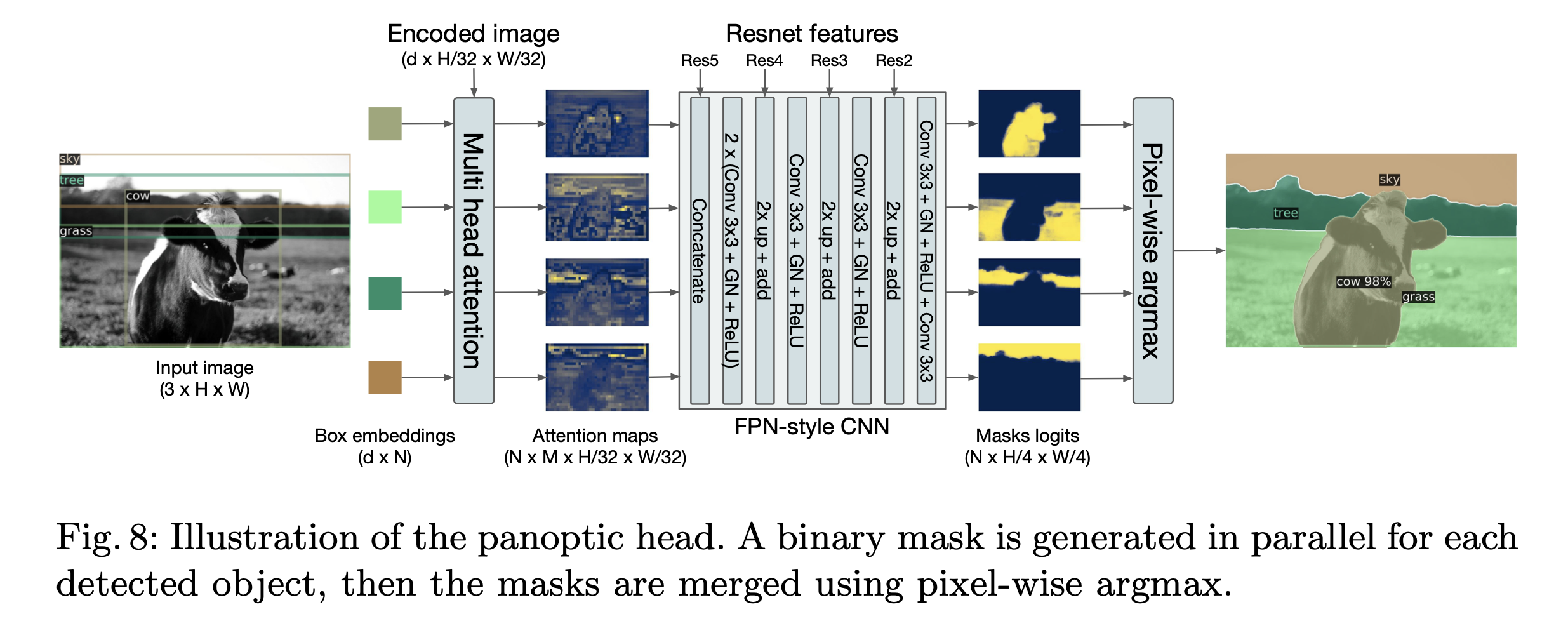
논문에서는 추가로 DeTR 을 통해 segmentation 을 수행합니다.
5. 기타
Pubtables dataset 논문에서 DeTR 을 이용해 table detection 과 structure recognition 그리고 functional analysis 를 수행하는 Table Transformer 가 발표되었습니다.
official github : https://github.com/microsoft/table-transformer
