IEEE, 2021, Swintransformer - microsoft
CVPR, 2022, SwinTransformerV2 - microsoft 0. 기존 이미지 모델에 대해
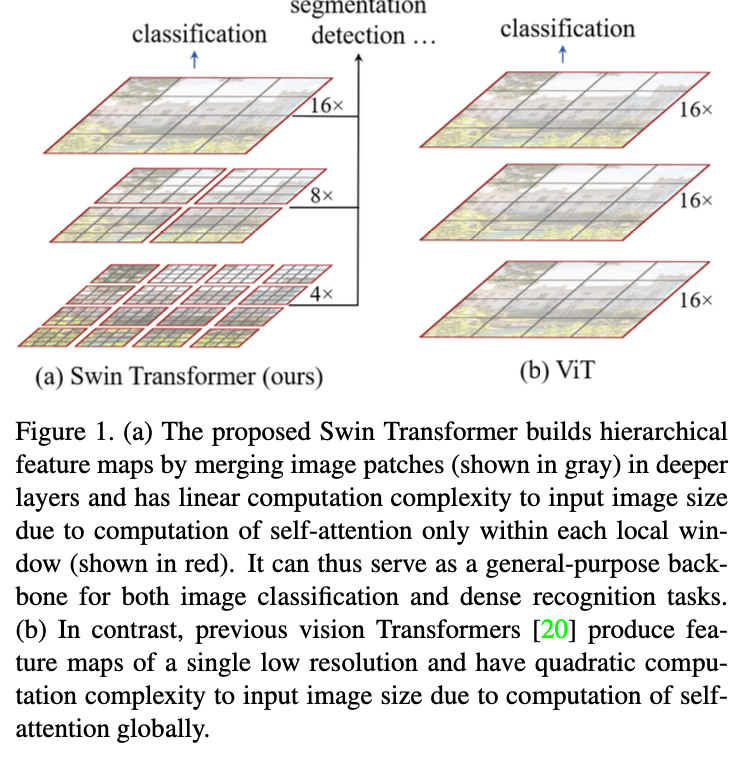
CNN 계열부터 transformer 계열까지 다양한 이미지 모델들이 발표되었지만 classification model 과 segmentation, object detection model 은 분리되어 개발되어 왔습니다.
classification model 과 segmentation model의 가장 큰 차이점은 모델이 바라보는 spatial information 의 범위 차이일것입니다. classification 은 이미지의 전체적인 특징을 봐야하지만, semantic segmentation task 는 pixel 단위의 정보 학습이 필요합니다.
CNN 계열 모델은 pixel 단위 정보 학습을 위해 다양한 strategy 를 사용합니다.
- detection task 에서는 전통적인 region of interest 추출을 통해 특정 부분의 feature 를 뽑고,
- segmentation task 에서는 resolution 단위로 feature 를 뽑아서 사용하는 feature pyramid network(FPN), U-Net 등이 제안되어 왔습니다.
1. transformer based image 모델의 문제점
transformer 계열의 이미지 모델은, 이미지를 일정한 크기의 patch 로 나눈뒤 각각의 patch feature 를 token 으로 사용하는 transformer 를 기반으로 하는 이미지 모델입니다.
Vision Transformer 의 발표 이후로 Transformer 계열 모델이 classification task 에서 보여준 성능적 우위에도 불구하고, segmentation task 에서는 Transformer 계열의 모델이 거의 사용되지 않습니다. 당연히, 이유가 있습니다.
1.0. patch size issue.
Transformer 모델의 기본 단위는 text model 의 Token 역할을 하는 image patch 입니다. Vision Transformer models 은 16x16, 32x32 크기의 image patch를 사용했으며, 이는 transformer 계열 모델에서 일반적으로 사용하는 patch size지만 high-resolution image 의 pixel 단위 feature 를 catch 하기에는 너무 큰 사이즈입니다.
1.1. quadratic complexity
그럼 patch size 를 줄이면 되지 않을까요? 그것 역시 Transformer base image model 에서는 쉽지 않습니다.
patch size 를 줄이게된다면, patch number 가 증가하게 됩니다. 그런데 Transformer 계열 모델에는 self-attention module 이 포함되어 있으므로 patch number 에 quadratic 한 계산 복잡도를 가지게 됩니다.
조금 더 나가보자면, patch size 를 반으로 줄인다면 (32x32 -> 16x16) 전체 patch 수는 제곱배 늘어나고...
계산량은 네제곱배 늘어나게 됩니다. 어마어마하죠.
input 이미지의 크기 역시 같은 문제를 야기합니다. 요약하자면, transformer 계열 모델에서는 self-attention module 로 인해 low spatial feature 를 추출하기가 쉽지 않습니다.
2. SwinTransformer
2.0. how swin solves quadratic complextiy?
transformer 계열의 이미지 모델 뿐만 아니라 텍스트 모델에서도 매우 큰 Input 을 다루기 위한 연구는 계속 되어 왔습니다. 역시 문제는 self-attention module 입니다.
가장 잘 알려진 방법은 window attention 입니다.
이름에서 알 수 있듯이, 제한된 크기의 window 내에서만 attention 을 적용하는 방법입니다. 어려운 설명은 하지 않아도 될 듯 합니다!
또, 여기서 다른 방법들이 파생됩니다.
- sliding window attention : windwo 를 slide 시키면 attention 을 수행합니다.
- dilated window attention : window 에 dilation 을 줍니다.
- using global tokens : 몇 몇 token 들은 attention 과정에서 전체 token 을 보며, 또 전체 token 이 볼 수 있습니다.
- linaer computation : matrix computation 을 전부 풀어서 계산합니다. time complexity 는 늘어나겠지만, 제한된 GPU 메모리에서 연산을 수행하기 위한 방법입니다.
2.1. windowed self-attention
얘기했던 대로, 특정한 크기의 patch 로 뭉친 window 안에서만 self-attentoin 을 수행합니다.
하지만 window attention startegy 안에서는 서로 절대 볼 수 없는 patch 가 존재하게 됩니다. 그러므로 서로 다른 window 의 patch 가 볼 수 있도록 해줘야하는데 swin transformer 는 두 가지 방법을 제안합니다.
2.2. patch merging
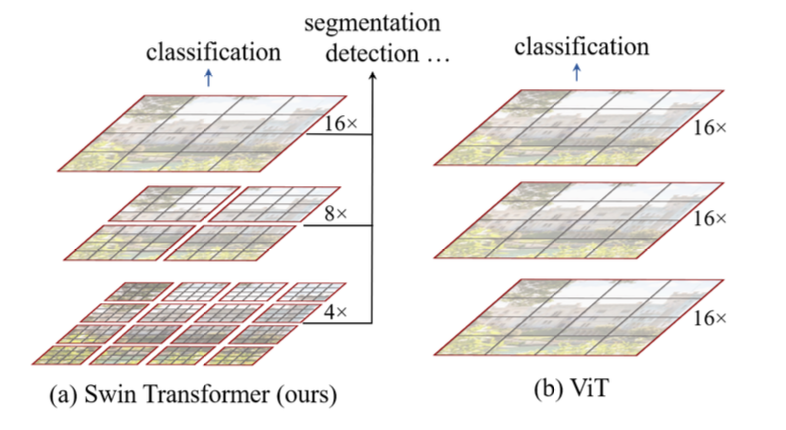
layer 를 통과하면서, swin transformer 모델은 인접한 2x2 크기의 patch 들을 순차적으로 합칩니다. 정확한 합치는 과정은 concatenate 연산 후, 작은 linear layer 를 통과시키는 방식입니다.
이 방법을 통해, swin transformer 모델은 서로 볼 수 없는 patch 들이 서로 참조할 수 있도록 할 수 있으며,
더 큰 범위를 cover 하는 patch 그리고 더 큰 범위를 cover 하는 window 를 통해서 서로 다른 resolution 에서 다양한 spatial informtation 을 학습할 수 있습니다.
U-Net 의 구조를 생각해보면 좋을 것 같습니다.
2.3. shifted window attention
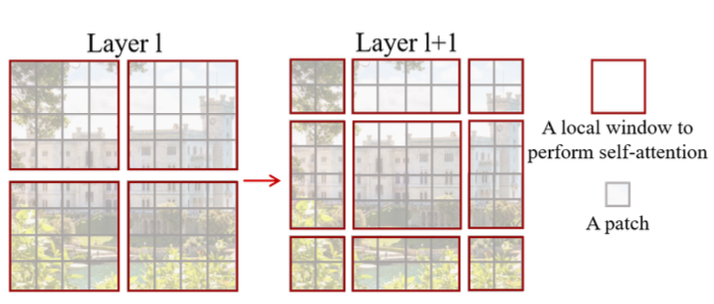
self-attention 에서 서로 볼 수 없는 patch 를 참조할 수 있게하기 위한 두번 쨰 방법은 shifted window 입니다. window 사이즈의 절반만큼 window 를 수직, 수평으로 이동시킨 후 이동한 window 내에서 attention 을 수행하는 방법입니다.
모델에서는 일반적인 self-attention 과 shifted window self-attention 이 번갈아서 사용됩니다.
작은 문제가 있는데, 그렇게 하면 남는 포함되지 못하는 patch 가 남게되는데...
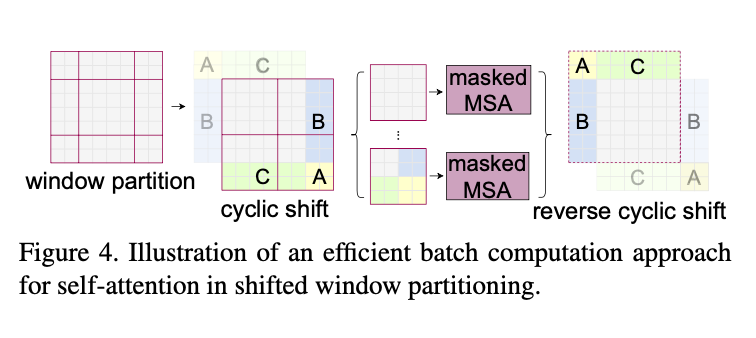
이건 직관적으로 알 수 있는 위 그림과 같은 형태의 연산 처리를 통해 수행합니다.
놀라운 점은, 코드 구현을 보면 생각보다 쉽게 구현되어 있다는 겁니다! 코드 참조해보시면 좋을 것 같아요.
2.4. overall architecture
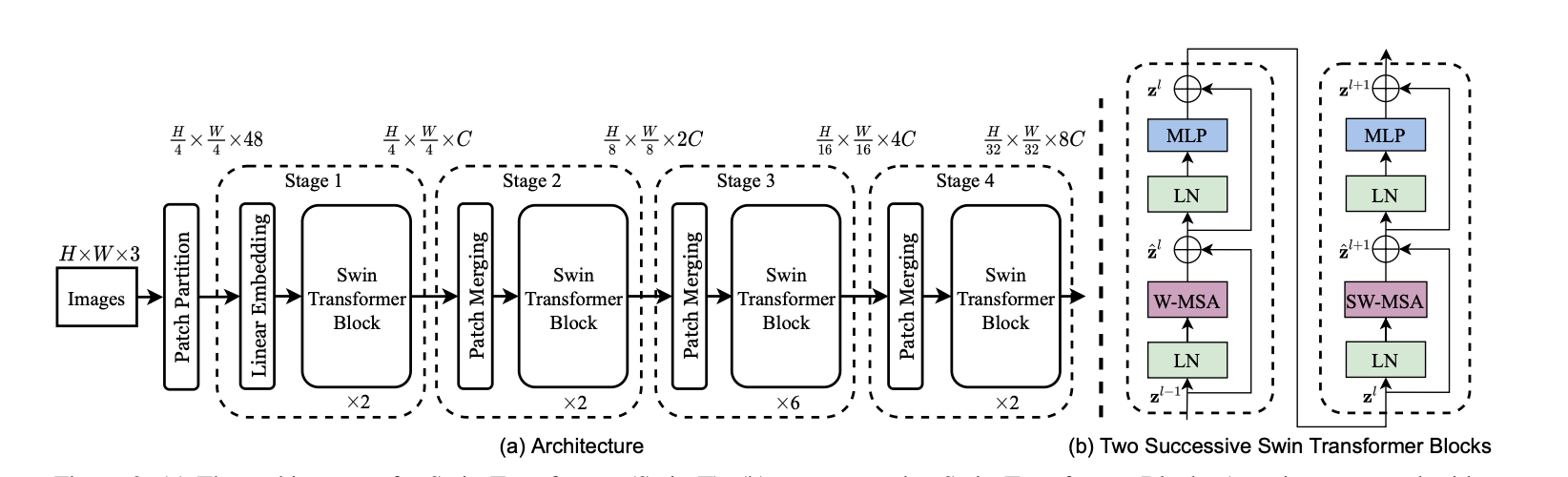
말씀드렸듯이, 전체적인 구조는 U-Net 과 비슷한 구조를 가지고 있습니다.
- feature map 의 크기는 줄어들고, channel 은 두꺼워지면서...
- swinTransformer Block 을 통과하는 형태입니다.
3. SwinTransformerV2
SwinTransformer 와 비교해서 바뀐점만 서술하려고 합니다.
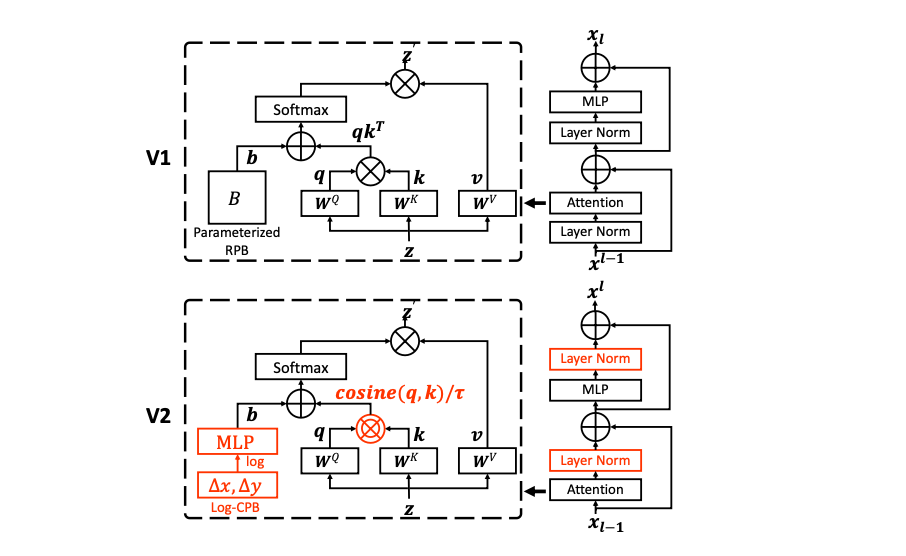
Swin Transformer block 단위의 변경사항만 있습니다.
3.1. LayerNorm
layer norm 을 attention, MLP 이후에 수행되도록 변경하였습니다. 사실 이건 다양한 모델의 코드 구현을 보면 작성자에 따라 다르지만...
제가 기존에 사용하던, 그리고 많이 보는 코드 구현의 순서는
activation -> normalization -> mlp(ml layer) 였으므로 약간의 변화가 생겼네요.
3.2. scaled cosine attention
기존의 attention 연산은 query 와 key 의 matrix 곱연산을 수행했지만, 해당 논문은 query 값과 key 값간의 cosine 값을 attention value 로 사용합니다.
가장 큰 이유는, pretrained model 을 transfer learning 할 때 window size를 변경하면 모델의 성능이 크게 바뀌었기 때문이라고 밝힙니다. 특히 3.1. layer norm 처리 후에는 그러한 영향이 더욱 커졌다고 하네요.
3.3. log-scaled relative position bias
attention 과정에서 position bias 를 주면 더욱 성능이 좋아진다는 연구 결과에 따라 swin transformer v2 에서는 position bias 를 적용합니다. 다만 기존 연구는 fixed position bias 를 사용한 것과 다르게 해당 논문에서는 작은 mlp 를 사용해서 position bias 를 계산합니다.
또한, 이 역시 window size 의 영향에 큰 영향을 받으므로 log-scale 로 계산합니다.
3.4. Also...
위에서 서술한 변경 사항들에는 소소한 추가사항들이 존재합니다. 다만, 어차피 정말 세세한 부분까지 논문을 이해하고 싶으신 분들은 이 글로 큰 그림을 잡고 논문을 정독하실 것이라 생각해 swin transformer v2 의 세세한 부분에 대해서는 서술하지 않겠습니다.
4. 코드 사용
swin transformer 는 timm 과 hugging face transformers 에서 지원합니다.
- timm swin transformer
사용시 조금 주의가 필요합니다. 모델 구현외의 padding 지원이 되지 않으므로 image의 W, H 값이patch_size * window_size * 2^(n_layers-1)의 배수로 실행해줘야합니다. - hugging face transformer
padding 으로 어떤 크기의 image input, patch size, window size 가 들어오더라도 정상적으로 연산을 수행합니다.
Reference
- VisionTransformer
- SwinTransformer
- SwinTransformerV2
- U-Net
- FPN
(link 및 paper info 는 업데이트 예정)
