Self-Supervised Learning의 관한 하나의 방법론을 제시한, Google Brain에서 낸 논문인 'A Simple Framework for Contrastive Learning of Visual Representations', 줄여서 SimCLR 논문을 요약/정리해보려 한다.
Background
-
기존의 Supervised Learning은 양질의 label 정보를 충분히 가지고 있는 데이터를 사용해야만 최적의 model을 만들 수 있다. 하지만 양질의 데이터 및 label 정보를 얻는 것은 시간과 돈이 많이 필요하다. 이러한 문제를 극복하기 위해 데이터에서 얻을 수 있는 정보를 사용해서 자체적인 label을 얻기 위해 고안된 방법이 Self-Supervised Learning이다.
-
Self-Supervised Learning 은 딥러닝 분야에서 최근 가장 핫한 토픽 중 하나이다. 사실 Self-Supervised Learning은 그 자체로 분류 및 예측 task의 정확도를 높이는 것이 목적이 아니다. Backbone 모델에서 더 좋은 representation(feature)을 학습하고 추출할 수 있도록 하여 차후 task에서 성능을 올리는 것이 목적이다. 이를 위한 초기 연구들은 보통 Jigsaw Puzzle나 Rotation 등의 간단한 Pretext Task를 직접 선정하여 backbone 모델을 학습시키는 것이었다. 하지만 최근 Self-Supervised Learning 연구 동향은 Pretext Task 없이 Contrastive Learning을 통해 학습하는 것이다.
- 미리 Contrastive Learning을 간단히 설명하자면, 같은 이미지에 augmentation을 가한 뒤, 기준인 anchor와 positive 사이의 positive pair의 embedded vector가 유사해지도록 학습을 하고, 다른 이미지에 서로 다른 augmentation을 가한 뒤, 기준인 anchor embedded vector와 negative embedded vector 사이의 거리는 멀어지도록 학습을 시키는 것이다.
Introduction
-
Human supervision 없이 Representation을 학습하는 것은 오랜 연구 분야였다. Representation을 학습한다는 것은 쉽게 말해, 인간의 간섭 없이 모델이 스스로 task에 적합한 feature들을 알아낸다는 것이다.
-
Contrastive Self-Supervised Learning을 활용하는 SimCLR 논문은 학습과정에서 data augmentation과의 차이를 학습하고 embedding layer를 깊게 쌓음으로써 유사도를 비교하는 공간인 feature space를 더 개선하여 image representation 학습 성능을 크게 향상 시키는 데에 기여하였다.
-
논문에서는 다음의 중요한 3가지 사항을 명확히 밝히고 있다.
- 간단한 몇 개의 Data augmentation 조합이 SimCLR 구조에서 중요한 역할을 한다.
- Representation과 Contrastive loss 사이의 non-linear transformation이 representation 성능을 향상시킨다.
- Contrastive learning은 batch size와 training step이 클 때 효과적이다.
Method
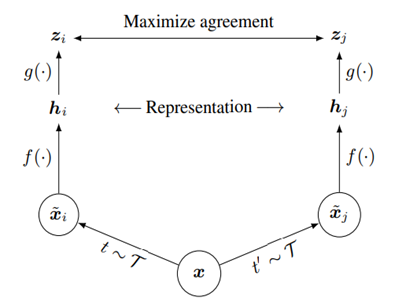
- SimCLR contrastive learning의 전체 framework를 나타내는 그림이다.
: Data augmentation 종류 (RandomResizeCrop, Random Color distortion, Gaussian Blur)
: Random sampling된 Data augmentation 기법
: Augmentation된 이미지
: Base Encoder (ResNet-50)
: ResNet-50 output에서 Global Average Pooling 된 vector
: non-linear representation을 적용하는 Projection head (Two-layer MLP)
: Projection head 통과 후 생성된 vector
Contrastive loss function : 간의 NT-Xent Loss
-
어떠한 관측치에 data augmentation()을 적용하여 2개의 pair image를 만들고 이는 positive pair에 해당한다. 나머지 minibatch에서 생성된 image들은 negative sample로 취급된다.
-
Data augmentation 이후 생성된 각각 는 는 를 통과하여 encoding 되어 Representation 를 생성한다.
-
이후 각각 은 1개의 hidden layer를 지니는 MLP를 통과하여 를 생성하고 이는 Contrastive loss를 구하기 더 좋은 latent space로 이동된다.

: Cosine similarity
𝜏 : temperature scaling parameter
: 같은 이미지에 대해 다른 augmentation을 적용한 두 이미지
: batch size
-
위의 SimCLR 전체 framework와 위의 그림을 보면 학습 알고리즘과 contrastive learning 컨셉을 전부 이해할 수 있다.
-
아래의 직관적인 그림을 보면 더욱 더 쉽게 이해할 수 있다.
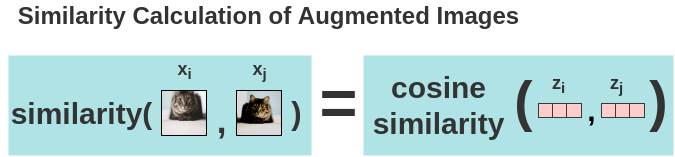
- 위 그림은 Positive pair 이미지를 통해 구한 Cosine 유사도를 나타낸다.
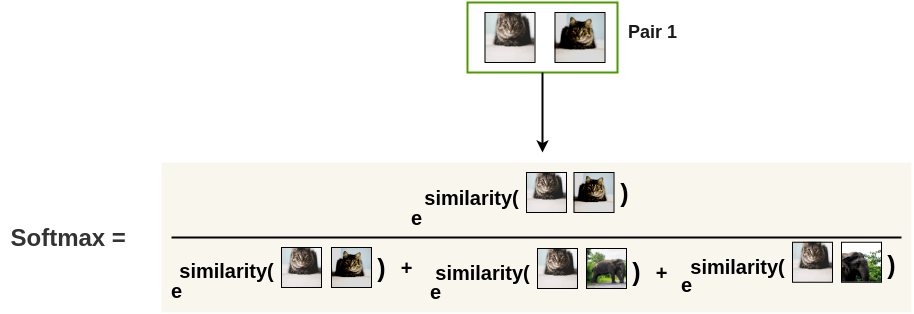
- 그 다음 softmax를 구한다.

- softmax 값을 를 취해 를 구한다.
- 이는 Noise Contrastive Estimation(NCE) Loss를 의미한다.

- 순서가 달라지면 값이 바뀌므로 image pair의 순서가 바뀐 값도 구한다.
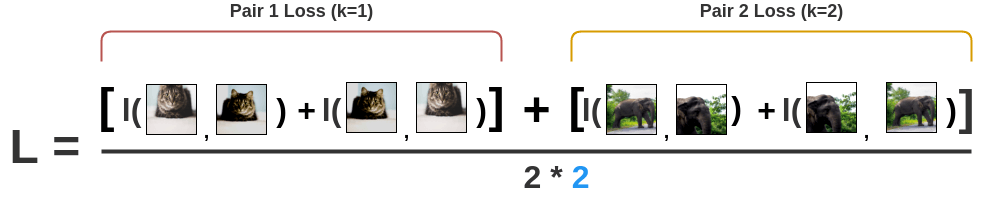
- 전체 batch size에 대한 모든 pair의 loss를 구하여 다 더하고 평균을 낸다.
Training
- 논문에서 제시하는 학습에 대한 추가적인 정보들을 나열하였다.
Training
- Batch size: 256 ~ 8192
- LARS optimizer 사용 : 많은 Batch size 학습을 감당하기 위해
- Aggregating BN mean and variance over all devices
Dataset
- ImageNet 2012
Evaluation
- Linear Evaluation Protocol : representation까지의 parameter를 freeze하고 linear layer 하나만 추가하여 supervised learning, evaluation 진행
Data Augmentation for Contrastive Representation Learning

- 간단한 몇 개로 구성된 Data Augmentation 기법 선택이 매우 중요하였다고 한다.
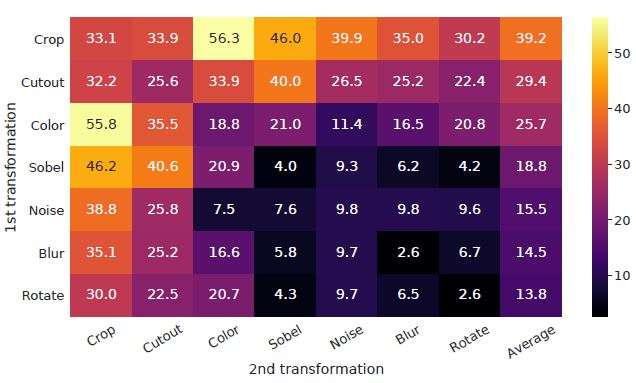
- Random cropping, Random color distortion, Gaussian blur 만을 사용하였을 때 가장 성능이 좋다.
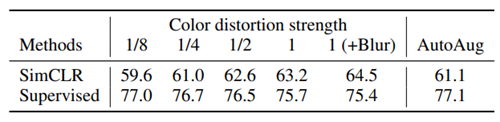
- Supervised의 경우 augmentation의 강한 효과가 오히려 성능을 낮췄지만 SimCLR의 경우 더 좋아졌다.
- 또한 Auto augmentation 하는 경우보다 간단히 구성된 몇 개의 augmentation 기법을 적용한 경우 성능이 좋은 것을 알 수 있다..
Architectures for Encoder and Head
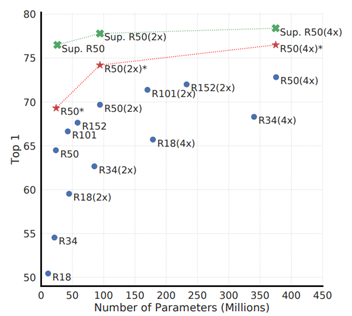
- 모델의 규모가 커질 수록 Unsupervised contrastive learning의 성능이 올라간 것을 알 수 있다.

- 위의 표를 보면 Projection Head를 사용한 것이 아닌 것보다 성능이 좋게 나타났으며, Linear보다 Non-linear projection head가 더 representation 성능이 좋게 나타난다.
Loss Function and Batch Size

- 여러 Loss Function 중 NT-Xent (Normalized Temperature-scaled Cross Entropy)의 성능이 가장 높았다.

- 또한 Batch Size를 매우 키우는 것이 더 좋은 성능을 보이고 있다. 이는 batch size를 매우 늘릴 경우 그 안에서 충분한 양의 negative sample을 뽑을 수 있기 때문이라고 추론해 볼 수 있다.
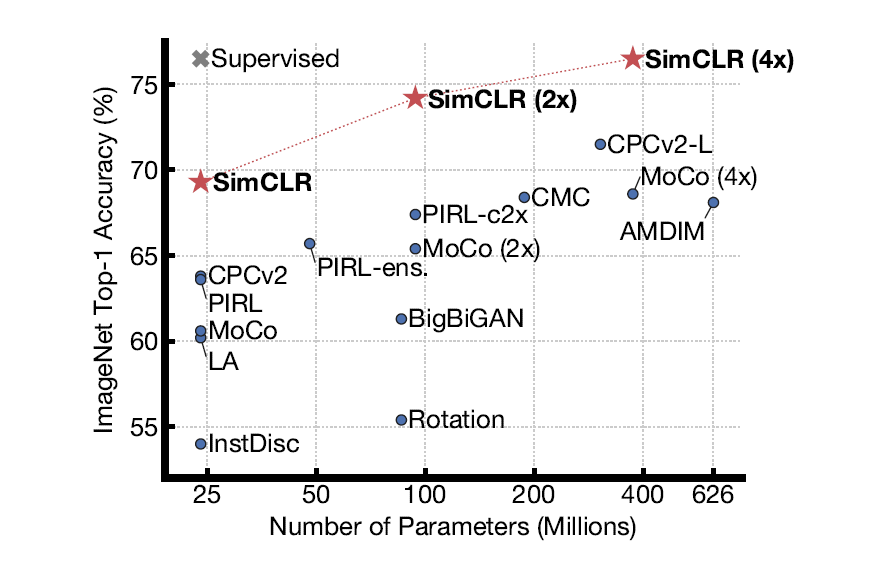
Comparison with State-of-the-art
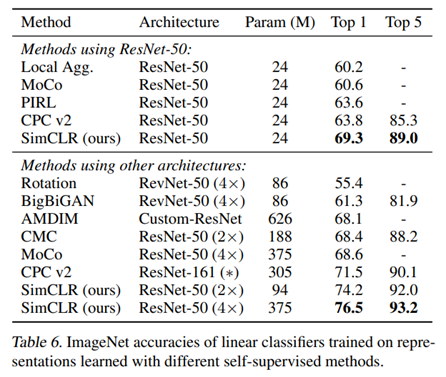
- 여러 Self-Supervised model과의 Linear evaluation 결과를 비교하였을 때, Architecture 별로 ResNet-50을 사용한 결과와 더 깊은 구조를 사용했을 때의 결과 모두 SimCLR에서 가장 뛰어난 성능을 보인다.
- Self-supervised 외에 transfer learning, semi-supervsied learning에 대한 실험에서도 우수한 성능을 보이고 있다.
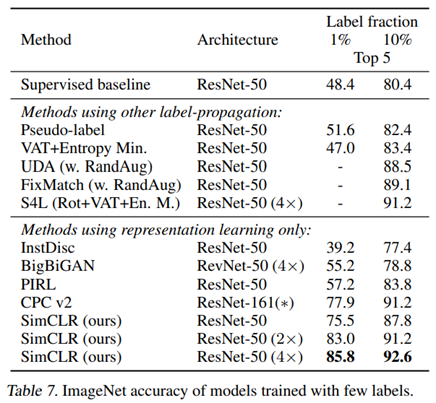
- Semi-supervised learning에 대한 실험 결과

- Transfer learning에 대한 실험 결과
Conclusion
-
Self-supervised Learning Simple framework로 Self-supervised learning, Semi-supervised learning, Transfer learning의 성능을 크게 개선하였다.
-
Supervised learning과는 다른 augmentation과 non-linear projection head를 제안하였다.
-
Representation을 학습하는 것으로 Supervised learning 수준의 성능을 달성하였다.
-
기존의 Pretext task를 활용하지 않고 Memory Bank 또한 필요로 하지 않는다.
References
original SimCLR paper : https://arxiv.org/abs/2002.05709
The Illustrated SimCLR Framework : https://amitness.com/2020/03/illustrated-simclr/
