Bagging
Bagging: Bootstrap aggregating의 줄임말
- Bootstraping: 복원 추출로 데이터셋을 샘플링하는 방법.
Pasting
-
비복원 추출로 데이터셋을 샘플링하여, 중복되지 않은 데이터로 학습.
-
사실 Bagging, Pasting은 여러 Predictor를 병렬적으로 학습시켜서 하나의 Predictor를 만들 때 Train Set에서 샘플링 데이터 추출 방식을 논하는 것이다.
-
그래서 Bagging 자체를 병렬적 학습 방법으로 보고, 이때 복원 추출로 데이터를 샘플링하는 것을 Bootstrap이라고 부를 수도 있는 것이다.
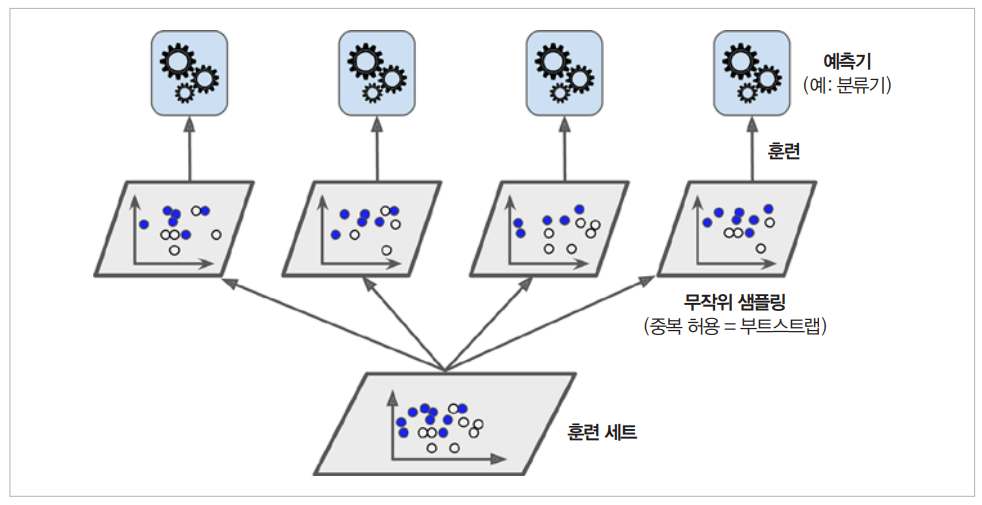
그림은 병렬적으로 데이터를 학습하는 Bagging의 학습하는 모습이다.
-> 이때 학습에 사용되는 Predictor가 모두 Decision Tree일 때 이 학습기는 Random Forest라고 한다.
Boosting
- Bagging의 병렬적인 학습 방법과 다르게, Sequential하게 학습하는 Ensemble 모델이다.
- 즉 직전의 Predictor를 보완해나가면서 일련의 Predictor들을 학습시키는 것입니다.
- 직전 Predictor이 과소적합했던 훈련 샘플의 가중치를 더 높이는 방식으로 진행된다.
- 이렇게 해서 새로운 predictor는 학습하기 어려운 샘플에 점점 더 맞춰지게 되는 것.
Example
1. AdaBoost
2. Gradient Boosting
3. XGBoost
1. AdaBoost
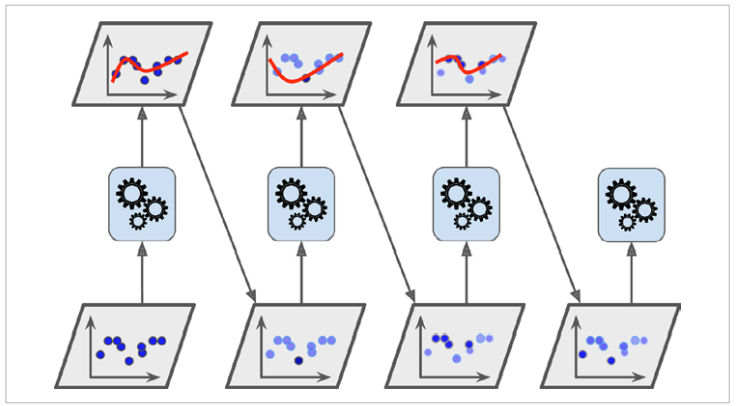
- AdaBoost는 알고리즘이 기반이 되는 첫 번째 분류기를 훈련 세트에서 훈련시키고 predictor를 만든다.
- 그 다음에 알고리즘이 잘못 분류한 훈련 샘플 (Underfitting한 훈련 샘플)의 가중치를 상대적으로 높인다. (즉 뒤의 분류기에서 얘네를 더 집중적으로 훈련할 것이다.)
- 그 다음 두 번째 분류기는 업데이트된 가중치를 사용해서 훈련세트에서 훈련하고 다시 predictor를 만들게 된다.
2. Gradient Boosting
- Gradient Boosting은 AdaBoost 처럼 앙상블에, 이전까지의 오차를 보정하도록 예측기를 순차적으로 추가합니다.
- 하지만 AdaBoost처럼 반복마다 샘플의 가중치를 수정하는 대신 이전 예측기가 만든 잔여 오차 (residual error)에 새로운 예측기를 학습시킵니다.
-> 학습할 때 사용할 훈련 샘플의 비율을 지정하면 (ex 25%) bias는 높아지는 대신 분산이 낮아지게 됩니다.
(complexity가 감소하므로 Bias-variance Trade-off에 의해)
- 이런 기법을 Stochastic Gradient Boosting이라고 한다.
3. XGBoost
이는 Extreme Gradient Boosting의 약자

포항공대 인공지능 대학원에 재학중인 대학원생입니다.