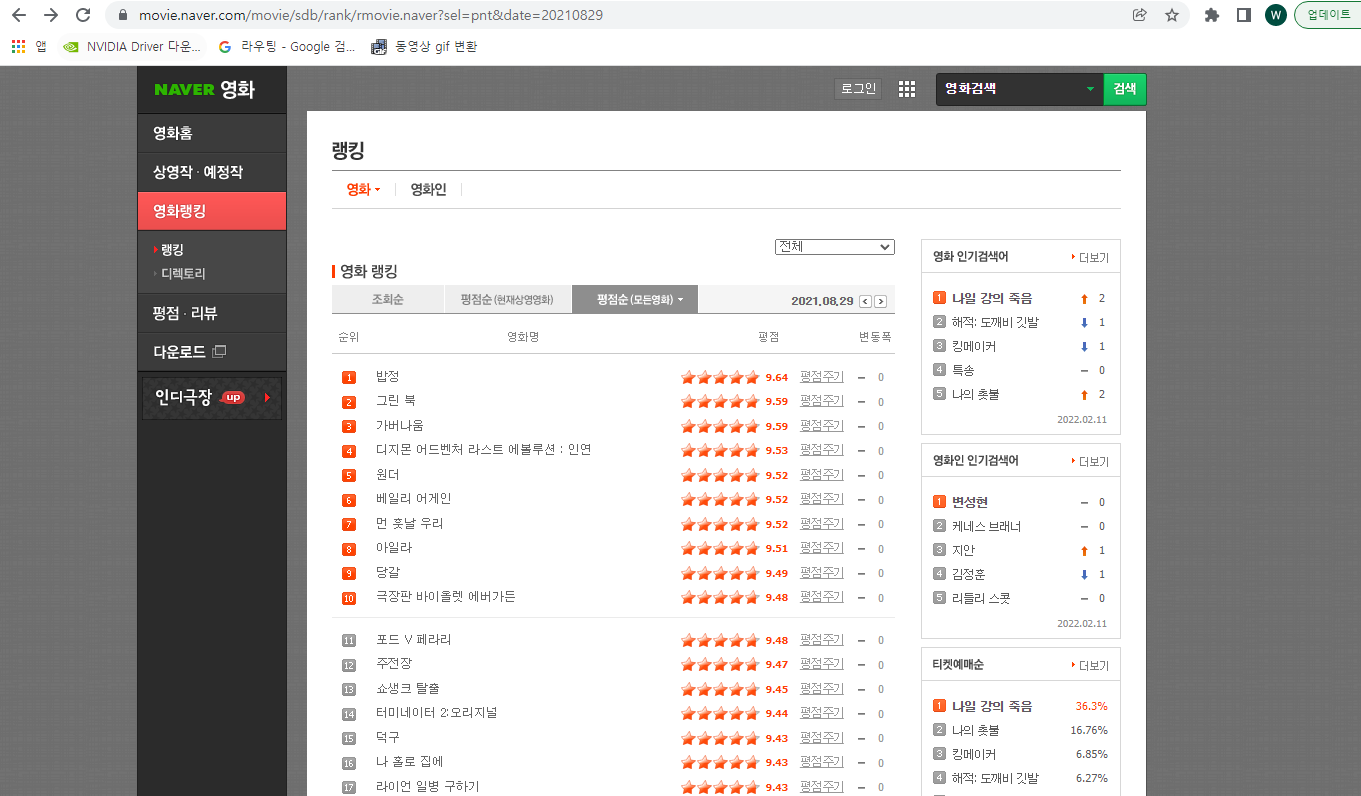
웹스크래핑을 이용해서 네이버 영화페이지의 랭킹 제목들을 가져올 것이다.
- 해당 홈페이지의 html을 가져온다 - (request) 이용
- 해당 홈페이지의 세부 데이터를 찾는다. - beautifulsoup 사용
BeautifulSoup
- HTML, XML 코드 전체를 대상으로 데이터를 읽어오는 라이브러리
네이버영화랭킹 페이지 화면에서 랭킹에 등록된 영화의 이름을 가져오는 작업을 위해 beatifulSoup 을 설치한다.
1위 영화 밥정이라는 이름을 출력하기 위해 영화제목 위에 오른쪽 마우스를 눌러 검사를 실행한뒤 하이라이트 되어있는 구문을 복사한다. 이때 복사는 selector 복사로 진행한다.
복사를 해서 붙여넣으면
#old_content > table > tbody > tr:nth-child(2) > td.title > div > a 이런 문구가 나타나는데, 이것은 해당 엘리멘트가 어느 구조에 어떤 위치로 있는지를 나타내는 것이다.(셀렉터)
import requests
from bs4 import BeautifulSoup
#유저가 부른 것처럼 하기 위한 header 속성
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
#old_content > table > tbody > tr:nth-child(2) > td.title > div > a
# 코딩 시작
title = soup.select_one('#old_content > table > tbody > tr:nth-child(2) > td.title > div > a')
print(title)-
네이버 영화랭킹 홈페이지에서 get 메소트를 요청하여 받아오는 데이터를 받아오는 변수를 선언 (data)
-
그 데이터를 읽어낸 값의 변수를 선언 (soup)
-
해당 셀렉터에 위치한 값을 가진 변수를 선언한뒤 출력을 진행하면
(title)
<a href="/movie/bi/mi/basic.naver?code=186114" title="밥정">밥정</a> 이렇게 출력이 되는데, 여기서 title대신 title.text로 코드를 바꾸면
밥정 만 나오게 된다.
순위와 평점 크롤링
영화 제목의 셀렉터의 상위 값을 movies 라고 선언하여 반복문으로 영화와 순위와 평점을 출력하고자 한다.
import requests
from bs4 import BeautifulSoup
#유저가 부른 것처럼 하기 위한 header 속성
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
# 코딩 시작
title = soup.select_one('#old_content > table > tbody > tr:nth-child(2) > td.title > div > a')
movies = soup.select('#old_content > table > tbody > tr')
print(title.text)
for movie in movies:
a = movie.select_one('td.title > div > a')
if a is not None:
title = a.text
이전에서 텍스트의 셀렉터를 확인했던것 처럼
랭크를 표시하는 이미지의 셀렉터 속성을 보면(이미지의 alt값이 숫자로 되어있어서 alt값이 곧 랭크를 표시하는 수치가 된다.)
#old_content > table > tbody > tr:nth-child(2) > td:nth-child(1) > img
평점을 나타내는 수치의 셀렉터 속성을 보면
#old_content > table > tbody > tr:nth-child(2) > td.point
반복문에서는 상위의 movies = soup.select('#old_content > table > tbody > tr')을 지정해 놓았기 때문에 하위 경로들로 구현을 해도 문제는 없다.
ex) 랭크의 경우
img = movie.select_one("td:nth-child(1) > img") #tr 그다음의 경로부터 끝까지 선언#ex) 평점의 경우
point = movie.select_one("td.point")랭크에서는 alt 값을, 평점에서는 text 값을 가져와야 하므로
정리하면 아래와 같다.
for movie in movies:
a = movie.select_one('td.title > div > a')
img = movie.select_one("td:nth-child(1) > img")
point = movie.select_one("td.point")
if a is not None:
title = a.text
rank = img['alt'] #img에서 'alt' 값만 가져온다.
star = point.text
print(rank,title,star)
