Summary ❕
💡 기존 Encoder-Decoder 기반 텍스트 번역 시 발생하는
긴 입력 문장에 대한 성능 저하 원인을 ’fixed-length’에서 찾아,
새로운 모델 구조를 제시⇒ Variable-length Encoding & Attention Decoding by using
context vector
Review 🗒️
0. Abstract
Previous : Neural Machine Translation with encoder-decoder
Flow : Source 문장 → encoder → “fixed-length” vector → decoder → output
이때, using “fixed-length” : bottleneck 유발!
In this paper ; Automatically soft-search
- 예측할 target word와 연관성이 있는 입력 문장의 파트를 탐색, w/o giving hard segmentation explicitly.
1. Introduction
Traditional translation : Phase-based translation system
- Sub-components tuned seperately
Previous Neural translation : Train a single, large network, sentence-unit
- 입력 문장의 모든 정보를 고정된 길이 “fixed-length”에 압축해야 하는 문제
- 긴 문장에 성능 저하 유발
In this paper : "context vector" 이용
Input 문장이 길어질 때 생기는 정보 압축 문제에 대한 해결책 제시 - 매 단어 생성마다 Automatically soft-search
- Most relevant information이 집중된 위치를 찾아 ⇒ context vector 생성
- 해당 위치 정보(Source position 정보)를 포함
- Contect vector + 이전 예측 단어들 → target word prediction!
Mechanism : ✔️
즉, Encoder는 입력 문장을 sequence of vectors로 변환하고,
Decoder는 인코더의 출력 벡터 중, 필요한 부분(subset)을 골라서 -Context vector를 이용하여- 사용한다.
이를 통해 다음과 같은 효과를 얻을 수 있다.
- 성능 향상
- 언어적으로 더 적합한(자연스러운) 변환
2. Background : Neural Machine Translation
Translation task == 조건부 확률을 최대화 하는 문장을 탐색하는 작업이다.
: Conditional probability of , given a source sentence =
2.1 RNN Encoder-Decoder
Encoder :
입력 문장을 받아 Context vector 를 다음과 같이 생성한다.
-
Input sentence →
Encoder→ Sequence of vectors
→Encoder→ (variable-length, contect vector)RNN :
where ; hidden state at time t
; context vector generated from hidden states
; some nonlinear functions
ex.) can be LSTM
Decoder :
입력을 받아 다음 단어를 예측하도록 학습된다.
-
Trained to predict the next word
(given & previously predicted words )즉, Decoder defines a probability over the translation , 해당 단어로 변환(예측)될 조건부확률을 아래와 같이 정의한다.
, RNN :
Where g ; nonlinear, potentially multi-layered, 확률 계산 함수
; hidden state of RNN
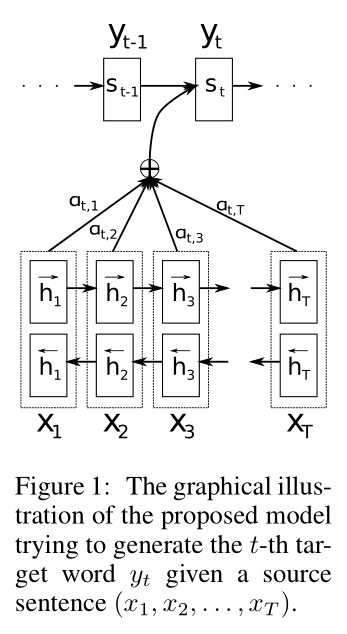
3. Learning to Align and Translate
- Bidirectional RNN Encoder & Searching Decoder
3.1 Decoder : General Description
Conditional probability : We define as
Where ; RNN hidden state of time i,
식 와의 차이점 :
각 target word 마다 조건부확률을 정의하는 가, time 마다 개별적으로 지정되어 있다.
Context vector :
는 인코더의 출력(mapped input sentence) - - 에 의해 아래와 같이 결정된다.
이때, 각각의 는 전체 문장(input sequence)에 대한 정보를 가진다.
(Containing strong focus on suroundings of -th word.)
-
는 다음과 같이 각 에 대한 가중합(weighted sum)으로써 계산되며,
가중치 는 로부터 가 예측될 확률이다.
즉, 를 생성할 때 의 'importance(중요도)'를 의미하며, 그것을 가중치로써 에 반영한다. ( reflectes the importance of the annotation )
Context vector 는, 위치의 단어 가 번째 출력 단어 에 대한 relevent information을 얼마나 가지는지의 정보를 담기 때문!
⇒ 위와 같은 방법으로, 1.의 Mechanism에 언급된 바와 같이,
Decoder가 인코더의 출력 벡터 중, 중요한(필요한) 부분(subset)을 골라서 사용하는 것처럼 보이게 한다.- 그리고 가중치 는 다음과 같이 계산된다.
- 이때, 이다. ( is a feedforward neural network)
이를 통해
Decoder의Attention mechanism이 구현되는데,
입력 문장의 어떤 부분에 집중할지 Decoder가 결정(하는 것처럼 보임)하게 된다.
✔️ Encoder가 입력된 전체 문장을 fixed-length로 압축하는 부담을 덜어준다.
3.2 Encoder : Bidirectional RNN for Annotating Sequences
BiRNN :
각 단어가 자기 자신의 이전 단어들에 대한 정보뿐만 아니라, 이후 단어들에 대한 정보까지 얻을 수 있게 하기 위함이다.
(For summarizing not only the preceding words, but also the following words.)
- Forward RNN : reads input from ( to )
- Calculates forward hidden states =
- Backward RNN : reads input from ( to )
- Calculates backward hidden states =
- Concatenate
⇒ 결과적으로 는 이전, 이후 문맥에 대한 모든 정보를 가진다.
