
- 드디어 DeepLearning.AI의 <ChatGPT Prompt Engineering for Developers> 강의를 정리하고 든 의문
반복적으로 프롬프트를 개선하는 과정은 알겠다. 그런데 어떻게 이 결과물을 평가하지?
- 이 의문을 Text-to-Image 분야에서 발 빠르게 해결한 논문이 있습니다 (세상엔 부지런하고 실행력 좋은 사람들이 참 많습니다)
- HCI 분야의 탑 컨퍼런스인 CHI 2022년에 실린 Design Guidelines for Prompt Engineering Text-to-Image Generative Models입니다
논문을 읽기 전에 공유하고 싶은 내용
- 프롬프트 엔지니어링이란? 타겟 테스크와 유저 요구사항에 적합한 결과를 도출하는 프롬프트를 탐색하는 작업입니다
- 논문에서는 프롬프트를 탐색한 결과물을 평가하는 방법과 그 과정에 얻은 인사이트를 제시하고 있습니다
- 다만 ✨논문이 VQGAN+CLIP 모델에서 실험됐으니 논문의 가설이나 결과가 타겟모델에 적용이 안될 수 도 있습니다
- 하지만 프롬프트 엔지니어링의 또 하나의 역할은 블랙박스 모델이 어떻게 돌아가는지에 대한 설명력을 부여하는 역할을 하기 때문에, 프롬프트 엔지니어링을 통해 모델의 수정방향을 잡을 수 있습니다
- 논문을 통해 ✨프롬프트 결과물을 평가하는 연구설계 방식을 배워가시면 좋겠습니다
프롬프트 타겟 테스크

- Input: 특정 대상에 대한 특정 이미지를 생성하는 프롬프트 텍스트 (그림 속 예시: "dog in the Impressionism style")
- Model: 텍스트 -> 이미지 모델 (VQGAN+CLIP)
- Output: 생성 이미지
잠깐의 모델 설명
-
논문에서는 모델 파라미터 관련 실험도 하고 있습니다. 때문에 VQGAN+CLIP에 대한 설명을 하고 넘어갈게요
-
그림으로 보면 쉽습니다 (이미지 출처: The Illustrated VQGAN)

-
VQGAN+CLIP은 초기 랜덤 벡터에서 시작합니다 -> 이 때 사용되는 랜덤시드를 설정할 수 있습니다
-
VQGAN 모듈이 반복해서 생성이미지를 만들면 CLIP이 제대로 만들었는지 판단하는데요 -> 이때 이미지 생성을 몇 번 반복할지를 설정할 수 있습니다
-
논문에서는 이 두가지 설정 변수가 미치는 영향에 대한 가설을 세워 검증합니다
프롬프트 평가를 위한 가설들
- 논문은 가설을 세우고 검증하는 방식으로 진행됩니다
- 프롬프트의 어순에 따라서 결과가 다를 것이다
- 모델의 이미지 생성 랜덤시드에 따라서 결과가 다를 것이다
- 모델의 이미지 생성 횟수에 따라서 결과가 다를 것이다
- 타겟 스타일에 따라 결과가 다를 것이다
- 타겟 대상과 스타일의 조합에 따라 결과가 다를 것이다
- 논문에서는 실험을 위해 12개의 대상(love, river...)과 12개의 이미지 스타일(Cubist, action painting...)을 선정했습니다
가설 1: 프롬프트의 어순에 따라서 결과가 다를 것이다 (기각)

- 실험셋팅
- (대상; SUBJECT) 단어와 (스타일; STYLE) 단어로 구성된 9개의 프롬프트 예제를 만듭니다 (위 그림의 왼쪽 예시)
- 그 다음 두 명이 12*12(대상*스타일) 조합에 대해 9개의 프롬프트로 생성된 이미지를 보고
- 최고 OR 최악의 그림을 찾고 -> 찾은 그림이 나머지와 확연하게 다른지 체크합니다 (SAME or OUTLIER)
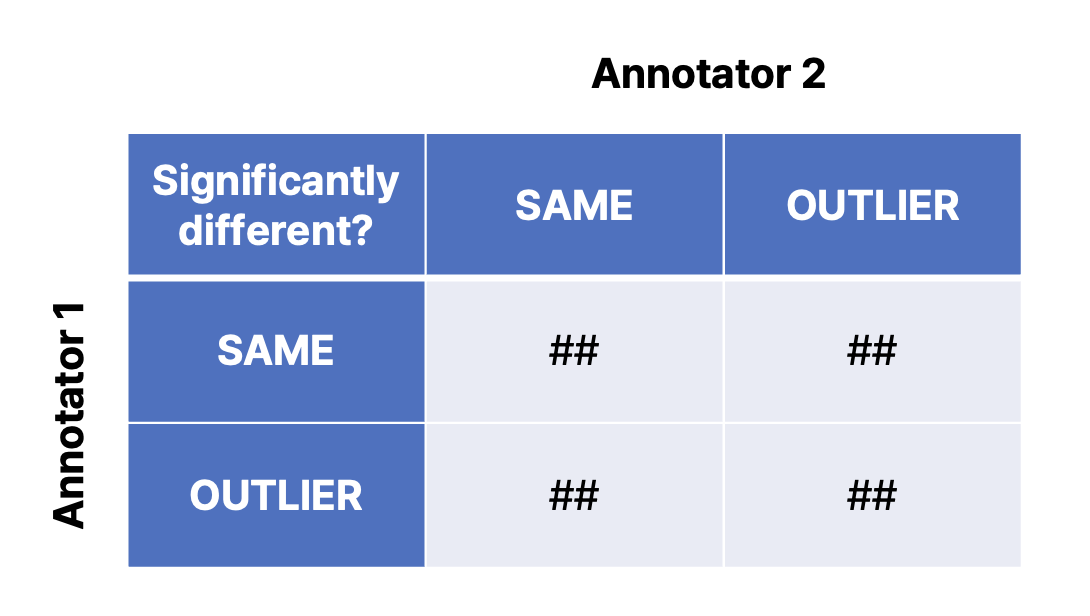
- 실험결과
- 이렇게 실험이 끝나면 9개의 프롬프트에 대해 위 표와 같은 데이터를 얻을 수 있습니다
- 이 데이터에 집단 간 비율 간 차이를 판단할 때 사용하는 카이제곱검증을 실행하면 p-value를 얻을 수 있는데요
- 결과는 로 유의성 검증에 실패
- 즉, 문법적 요소는 결과물에 유의미한 영향을 끼치지 않는다고 해석할 수 있습니다
💡 프롬프트 작성할 때 어순, 구두점과 같은 문법요소를 고려하기 보다 타겟 대상과 테스크에 집중합시다
가설 2: 모델의 이미지 생성 랜덤시드에 따라서 결과가 다를 것이다 (채택)
- 실험셋팅
- 가설 1의 실험 방식과 동일합니다. 다만 이번엔 프롬프트는 고정되어있고 모델의 랜덤시드가 변수입니다
- 두 명이 각 프롬프트로 생성된 12*12(대상*스타일) 조합에 9개의 랜덤시드로 생성된 이미지를 보고
- 이 때 사용한 프롬프트는 "SUJECT in the style of STYLE"입니다
- 최고 OR 최악의 그림을 찾고 -> 찾은 그림이 나머지와 확연하게 다른지 체크합니다 (SAME or OUTLIER)

- 실험결과
- 이렇게 실험이 끝나면 9개의 랜덤시드 모델에 대해 가설1과 비슷한 형태의 데이터를 얻을 수 있습니다
- 이번엔 피셔정확검정을 통해(아마 카이제곱검정이 안맞았는 듯) 데이터에 집단 간 비율 간 차이를 판단했는데요
- 결과는 로 유의성 검증에 성공
- 모델의 랜덤 시드가 결과물에 유의미한 영향을 끼친다고 해석할 수 있습니다
가설 3: 모델의 이미지 생성 횟수에 따라서 결과가 다를 것이다 (채택)

-
실험셋팅
- 72개의 이미지에 대해서 이미지 생성 횟수가 [100,200,....,1000]번인 이미지 집합을 생성합니다
- 두 명의 작업자는 각 이미지 집합에서 가장 맘에 드는 이미지를 고릅니다
-
실험결과
- 이렇게 실험이 끝나면 이미지 생성 횟수별로 맘에드는 이미지 비율을 구할 수 있습니다 (아래 표를 보면 오버피팅 현상처럼 생성 횟수 별로 선호 이미지 비율이 줄어드는 것도 확인됩니다)
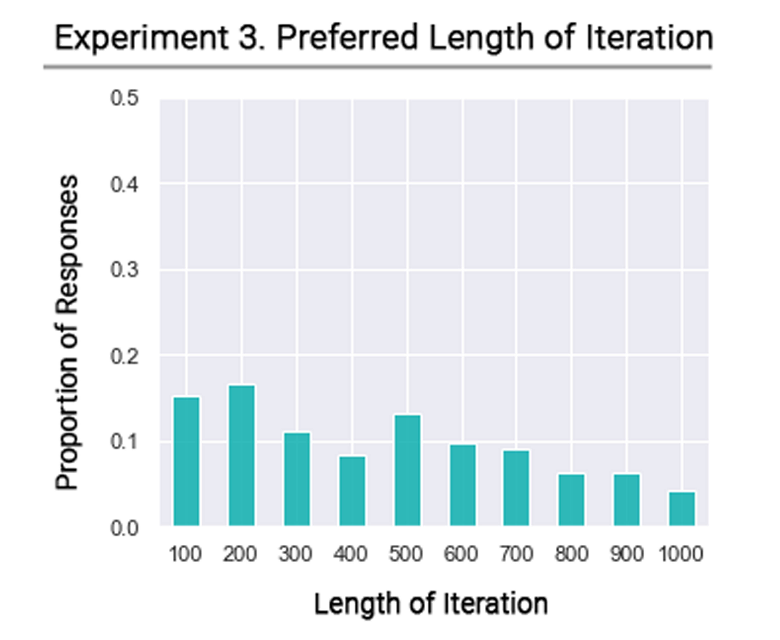
- 이번에도 카이제곱검정을 통해 데이터에 집단 간 비율 간 차이를 판단했는데요
- 결과는 로 유의성 검증에 성공
- 모델의 이미지 생성 횟수가 결과물에 유의미한 영향을 끼친다고 해석할 수 있습니다. 하지만 동시에 저자들은 타겟 스타일에 따라서 이런 결과를 잘 해석해야합니다. 예를 들어, 추상 스타일의 그림은 애초에 적게 모델을 적게 돌려서 세부적인 느낌을 안주는 것이 좋은 해결책이 될 수 있기 때문입니다
💡 모델의 생성 파라미터가 결과물에 영향을 끼칠 수 있다
가설 4: 타겟 스타일에 따라 결과가 다를 것이다 (분석 필요)
- 실험셋팅
- 이 가설은 모델이 아무 스타일이나 잘 할 수 있나? 특정 스타일에 편향되어있는가?를 검증하기 위한 가설입니다
- 이를 위해서 타겟 스타일을 51개로 늘렸습니다
- 두 명의 작업자는 12개의 타겟 대상에 대해서 51개의 스타일로 생성된 이미지를 보고 5점 척도로 점수를 매깁니다 (높을 수록 좋음)
- 실험결과 분석은 점수 분석 + 점수가 높은/낮은 케이스에 대한 분석으로 진행됩니다
-
실험결과
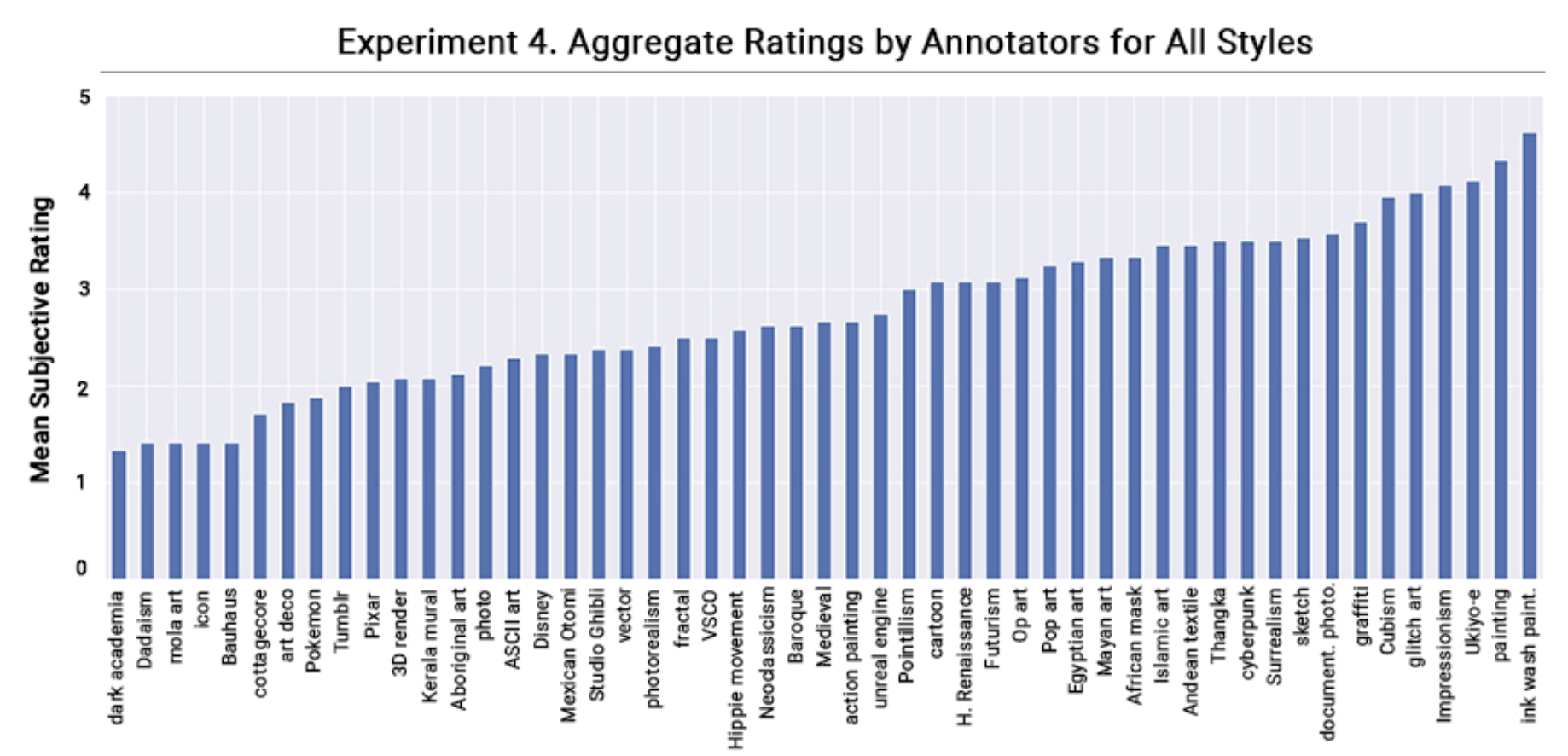
-
선호도 점수는 각 스타일마다 꽤나 다르게 나왔습니다
-
그럼 어떤 스타일을 잘하고? 어떤 스타일을 실패했을까?
-
성공 사례 분석
- 특정 컬러나 텍스쳐가 독특할 때 (우키요에, 고대 이집트풍, 중세풍, 사이버펑크)
- 특정 선의 특징이 있을 때 (점묘법, 큐비즘, 카툰 스타일)
- 스타일에 맞는 원근법이나 빛/그림자 묘사를 잘 한다 (중세풍은 평평하게 등등..)
-
실패 사례 분석
- 스타일에 대한 이해 자체가 어려울 때 (다크 아카데미풍을 = 나의 히어로 아카데미아풍으로 인식한다던가?)
- 스타일 특징을 캐치할 능력이 없을 때 (다다이즘 같은 스타일. 참고로 다다이즘의 대표적 작품은 마르셀 뒤샹의 샘(a.k.a 변기))
- 특정 스타일에 대한 훈련 리소스가 부족할 때 (언리얼 스타일은 무조건 바위와 함께 나온다던가)
-
이것저것 분석을 많이 했지만 결국 사진과 비슷한 구체적인 스타일은 잘되고, 추상적인 스타일 + 레퍼런스 부족한 스타일은 어렵다라는 결과
-
🧐 레퍼런스 부족하다는 문제는 이건 VQGAN+CLIP의 시절 얘기고 Stable Diffusion + LoRA로 스타일 별 개별 학습이 되는 시점에 글을 써보면 어렵지 않게 해결할 수 있는 지점이라고 생각합니다
-
🧐 문제는 추상표현이 어렵다라는 점인데.... 딥러닝은 A=A^을 잘하지 거기에 A=@?&*를 보여주는 개념미술 계열 작업들을 굳이 맡길 이유가 있을까요? 단순 참고나 퀄이 중요하지 않은 작업에 쓸 수도 있겠지만요...
가설 5: 타겟 스타일에 따라 결과가 다를 것이다 (분석 필요)
- 실험셋팅
- 이 가설은 모델이 특정 물체에 스타일을 입히는 일에 편향되어있는가?를 검증하기 위한 가설입니다
- 앞선 가설4는 다양한 스타일에 대한 선호도 조사라면, 가설5는 물체를 고정해놓고 그 물체를 가장 잘 표현할 수 있는 문제를 찾는데 주목했습니다
- 이를 위해서 51개의 대상에 대해 31개 스타일로 생성된 이미지를 보고 5점 척도로 점수를 매겼습니다
- 추가로 대상를 (추상 물체, 개념 물체)로 나누고 스타일을 (추상 스타일, 개념 스타일)로 나눠서 two-way ANOVA 테스트를 진행했어요
- 실험결과
- 이번 결과도 가설4와 같이 케이스 스터디로 진행했습니다
- 결론만 이야기하면 각 물체에 따라 잘 맞는 궁합이 있고, 그 궁합은 추상도와 관련성으로 결정된다는 결론입니다 (예를 들어 "아파트"와 같은 현대 문물이 "바로크풍"과 만났을 대 결과는 딱히 좋지 않겠죠)
💡 X를 Y스타일로 변환할 때 성공하려면 X와 Y와 궁합을 잘 고려해보자
정리와 후기
- 지금까지 텍스트-이미지 생성 테스크에서 결과물을 평가하는 방법을 알아봤습니다
- 생성 옵션들을 잘 고려해라, 원하는 테스크의 적합성을 잘 생각해라라는 말이 어떻게 보면 당연하게 들릴 수 있겠지만, 당연함도 구체적인 실험을 통해 검증해야하는게 아니겠습니까. 이 논문은 그런 점에서 어떻게 가설을 세우고 실험 설계를 할지에 대한 레퍼런스를 제공했다는 점에서 의미가 있다고 평가할게요
- 이 논문에서는 결과물 평가를 CS 전문가의 설계(저자들) + 미술 전문가의 평가(어노테이터들) 조합으로 진행했는데요. 데이터셋 구축과 마찬가지로 프롬프트 엔지니어링 또한 우리가 원하는 타겟 도메인의 전문가와 잘 협업할 수록 좋은 영역이라는 생각이 듭니다
- 가설 검증하면서 본 처참한 kappa score(0.00x이 논문에 실리더라구요.. 그리고 사유: 주관적인 테스크라서 그럼이라고 덧붙였음) 를 보면서 생성 테스크라는 게 주관성이 많이 필요한 일인 만큼, 생성 테스크의 유저를 타겟팅을 잘하는 것이 그 유저들에게 만족감을 주는 성공적인 프롬프트/모델 개발의 토대라는 걸 깨닫습니다
