
실습 데이터: 캐글 타이타닉 데이터
데이터 스케일링
데이터 스케일링(Data Scaling)이란 서로 다른 변수의 값 범위를 일정한 수준으로 맞추는 작업을 의미합니다. 값을 조정하는 과정이기 때문에 수치형 변수에만 적용해야 합니다.
사이킷런에서는 스케일링을 수행하기 위한 다양한 스케일러를 제공하는데요.
이때 모든 스케일러는 공통적으로 다음과 같은 메서드를 이용합니다.
fit(): 데이터 변환을 위한 기존 정보 설정 (ex: 데이터 세트의 최댓값/최솟값)transform(): fit()을 통해 설정된 정보를 이용해 실제로 데이터를 변환
그리고 fit_transform()은 위 두 가지 메서드를 한 번에 적용하는 기능을 수행합니다.
우선, 스케일링의 대표적인 방법인 표준화(Standardization)와 정규화(Normalization)를 살펴보겠습니다.
✅ 표준화
▶ 개념
표준화(Standardization)는 변수 각각의 평균을 0, 분산을 1로 만들어주는 스케일링 기법입니다. 표준화가 적용된 변수는 가우시안 정규분포를 가진 값으로 변환됩니다.
아래 수식과 같이, 변수 x의 원래 값에서 x의 평균을 뺀 값을 x의 표준편차로 나눈 값으로 계산할 수 있습니다.
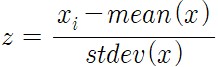
💻 실습
표준화를 위해, 사이킷런에서는 StandardScaler를 제공합니다. 이는 표준화를 쉽게 지원하기 위한 클래스로, 개별 변수를 평균이 0이고 분산이 1인 값으로 변환해줍니다.
- 표준화를 위해 사이킷런의
StandardScaler클래스를 사용합니다.fit_transform()을 사용해서 학습과 스케일링을 한 번에 적용합니다.
다음과 같은 타이타닉 데이터의 "Age", "Fare" 변수에 표준화를 적용해보겠습니다.
| Age | Fare |
|---|---|
| 22.0 | 7.2500 |
| 38.0 | 71.2833 |
| 26.0 | 7.9250 |
| 35.0 | 53.1000 |
| 35.0 | 8.0500 |
| ... | ... |
코드
# train 데이터의 수치형 컬럼을 추출해서 train_X_num이라는 객체에 저장합니다.
train_X_num = train[['Age', 'Fare']]# scikit-learn 패키지의 StandardScaler 클래스를 불러옵니다.
from sklearn.preprocessing import StandardScaler
# StandardScaler 객체를 생성합니다.
standard_scaler = StandardScaler()
# fit_transform()을 사용해서 학습과 스케일링을 한 번에 적용합니다.
train_standard = standard_scaler.fit_transform(train_X_num)
# 표준화가 완료된 데이터를 데이터프레임 형태로 변환합니다.
train_standard = pd.DataFrame(train_standard,
index=train_X_num.index,
columns=train_X_num.columns)# 표준화가 잘 되었는지 데이터를 확인해봅시다.
train_standard.head()
다음과 같이 표준화가 잘 적용되었음을 확인할 수 있습니다.
| Age | Fare |
|---|---|
| -0.530377 | -0.502445 |
| 0.571831 | 0.786845 |
| -0.254825 | -0.488854 |
| 0.365167 | 0.420730 |
| 0.365167 | -0.486337 |
✅ 정규화
▶ 개념
정규화(Normalization)는 일반적으로 서로 다른 변수의 크기를 통일하기 위해 크기를 변환해주는 개념입니다.
아래 수식과 같이, 변수 x의 원래 값에서 x의 최솟값을 뺀 값을 x의 최댓값과 최솟값의 차이로 나눈 값으로 계산할 수 있습니다.
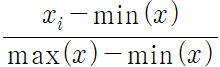
▶ 예시
예를 들어 아래와 같이 두 변수가 있다고 가정해보겠습니다.
- 변수 A: 거리를 나타내는 변수로서 값이 0 ~ 200KM로 주어짐
- 변수 B: 금액을 나타내는 변수로서 값이 0~200,000,000원으로 주어짐
정규화란 이 변수들을 모두 동일한 크기 단위로 비교하기 위해, 값을 모두 0에서 1 사이로 변환하는 것입니다.
▶ 특징
① 정규화를 통해 변수들이 평등하게 0~1 사이에 놓이게 되면, 모델은 어느 특정 변수에 중점을 두기보다는 변수들을 평등하게 바라보고 학습을 진행하게 됩니다.
② MinMaxScaler는 타이타닉 생존자 예측(0 또는 1)과 같은 분류 문제보다는,
아파트 실거래가격 예측과 같은 회귀 문제를 해결할 때 더 적합한 스케일링 기법입니다.
💻 실습
사이킷런의 MinMaxScaler는 데이터 값을 0과 1 사이로 변환해줍니다.
(만약 음수 값이 있으면 -1에서 1 값으로 변환합니다.)
- 데이터의 값을 0~1 사이로 변환하기 위해,
MinMaxScaler클래스를 사용합니다.fit_transform()을 사용해서 학습과 스케일링을 한 번에 적용합니다.
이번에는 "Age", "Fare" 변수에 MinMax 스케일링을 적용해보겠습니다.
코드
# train 데이터의 수치형 컬럼을 추출해서 train_X_num이라는 객체에 저장합니다.
train_X_num = train[['Age', 'Fare']]# scikit-learn 패키지의 MinMaxScaler 클래스를 불러옵니다.
from sklearn.preprocessing import MinMaxScaler
# MinMaxScaler 객체를 생성합니다.
minmax_scaler = MinMaxScaler()
# fit_transform()을 사용해서 학습과 스케일링을 한 번에 적용합니다.
train_minmax = minmax_scaler.fit_transform(train_X_num)
# Min-Max 스케일링이 완료된 데이터를 데이터프레임 형태로 변환합니다.
train_minmax = pd.DataFrame(train_minmax,
index=train_X_num.index,
columns=train_X_num.columns)# 스케일링이 잘 되었는지 데이터를 확인해봅시다.
train_minmax.head()
다음과 같이 수치형 변수들의 값이 0~1 사이로 잘 변환되었음을 확인할 수 있습니다.
| Age | Fare |
|---|---|
| 0.271174 | 0.014151 |
| 0.472229 | 0.139136 |
| 0.321438 | 0.015469 |
| 0.434531 | 0.103644 |
| 0.434531 | 0.015713 |
✅ 로버스트
표준화, 정규화 이외에도 로버스트 스케일링이라는 기법이 존재합니다.
▶ 개념
로버스트(Robust)는 데이터의 중앙값 = 0, IQR = 1이 되도록 스케일링하는 기법입니다.
아래 수식과 같이, 변수 x의 원래 값에서 x의 중앙값을 뺀 값을 x의 제3사분위수(Q3)와 제1사분위수(Q1)의 차이를 나눈 값으로 계산할 수 있습니다.
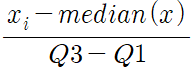
▶ 특징
RobustScaler를 사용하면 모든 변수들이 같은 스케일을 갖게 되며, StandardScaler에 비해 스케일링 결과가 더 넓은 범위로 분포하게 됩니다.
따라서 StandardScaler에 비해 이상치의 영향이 적어진다는 장점이 있습니다.
💻 실습
RobustScaler클래스를 사용합니다.fit_transform()을 사용해서 학습과 스케일링을 한 번에 적용합니다.
이번에는 "Age", "Fare" 변수에 Robust 스케일링을 적용해보겠습니다.
코드
# train 데이터의 수치형 컬럼을 추출해서 train_X_num이라는 객체에 저장합니다.
train_X_num = train[['Age', 'Fare']]# scikit-learn 패키지의 RobustScaler 클래스를 불러옵니다.
from sklearn.preprocessing import RobustScaler
# RobustScaler 객체를 생성합니다.
robustScaler = RobustScaler()
# fit_transform()을 사용해서 학습과 스케일링을 한 번에 적용합니다.
X_train_robust = robustScaler.fit_transform(train_X_num)
# robust 스케일링이 완료된 데이터를 데이터프레임 형태로 변환합니다.
train_robust = pd.DataFrame(X_train_robust,
index=train_X_num.index,
columns=train_X_num.columns)
🔎 스케일링할 때 주의할 점
위에서 언급했듯이 사이킷런의 모든 스케일러는 공통적으로 다음과 같은 메서드를 이용하며, fit_transform()은 이 두 가지 메서드를 한 번에 적용하는 기능을 수행합니다.
fit(): 데이터 변환을 위한 기존 정보 설정 (ex: 데이터 세트의 최댓값/최솟값)transform(): fit()을 통해 설정된 정보를 이용해 실제로 데이터를 변환
그런데 메서드들을 사용할 때 주의해야 할 점!이 있습니다.
학습 데이터로 fit()과 transform()을 적용하면, 테스트 데이터로는 다시 fit()을 수행하지 않고 학습 데이터로 fit()을 수행한 결과를 이용해 transform() 변환을 적용해야 한다는 것입니다.
즉 테스트 데이터에 다시 fit()을 적용해서는 안 되며, 학습 데이터로 이미 fit()이 적용된 Scaler 객체를 이용해 transform()으로 변환해야 합니다.
이렇게 하지 않으면 학습 데이터와 테스트 데이터의 스케일링 기준 정보가 서로 달라지기 때문에 올바른 예측 결과를 도출하지 못할 수도 있습니다 😥
정리하자면 다음과 같습니다.
- 테스트 데이터에는 이미 학습 데이터로 fit()이 수행된 Scaler 객체를 이용해 transform()으로 변환해야 합니다.
참고

4개의 댓글

https://noti.st/viwadoll
https://findaspring.org/members/viwadoll/